LLaMA模型
简单了解[LeCun狂赞:600刀GPT-3.5平替! 斯坦福70亿参数「羊驼」爆火,LLaMA杀疯了]
论文原文:https://arxiv.org/abs/2302.13971v1
预训练数据

模型架构
模型就是用的transformer的decoder,模型设计的不同点在于:
1 Position Embedding:RoPE旋转位置编码rotary-embedding
删除了绝对位置嵌入,而是在网络的每一层添加了Sujianlin等人(2021)引入的旋转位置嵌入(RoPE)。
现阶段被大多数模型采用的位置编码方案,具有很好的外推性。
[RoPE旋转位置编码]
2 Feedforward Layer
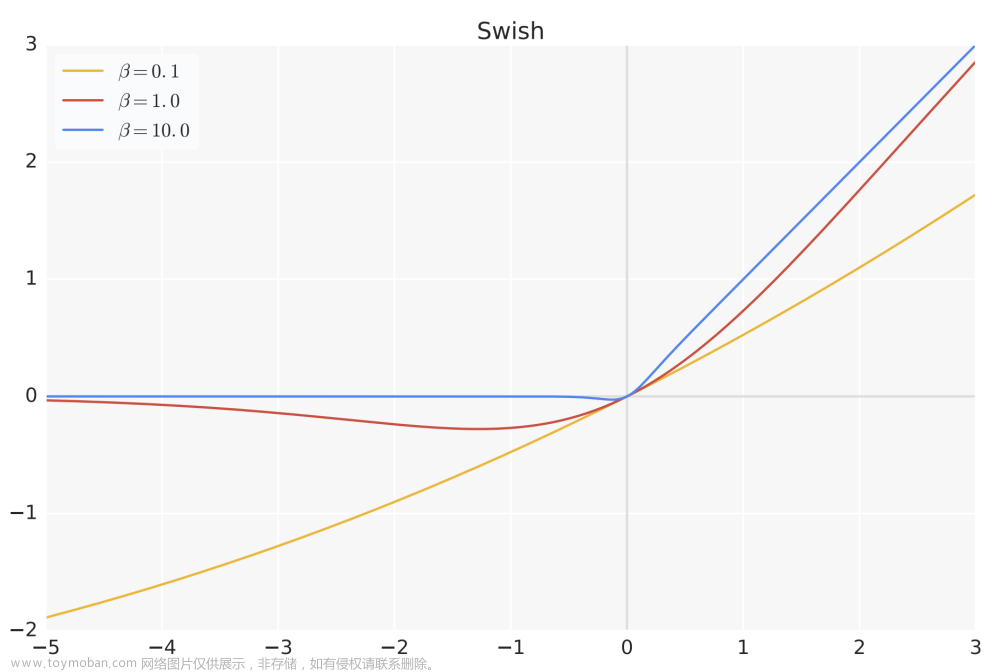
采用SwiGLU;Feedforward变化为(8/3)倍的隐含层大小,即2/3*4d而不是4d。
SwiGLU激活函数:
Swish=x⋅sigmoid(βx)

源于PaLM中使用的[SwiGLU激活函数]
3 Layer Normalization: 基于RMSNorm的Pre-Normalization
同GPT3。
Pre-Normalization

RMS Pre-Norm

[LLM:大模型的正则化_-柚子皮-的博客-CSDN博客]
不同模型的超参数的详细信息。

训练细节
使用AdamW优化器进行训练(Loshchilov和Hutter,2017),具有以下超参数:β1=0.9,β2=0.95。
使用余弦学习速率表,使得最终学习速率等于最大学习速率的10%。我们使用0.1的权重衰减和1.0的梯度裁剪。
使用2000个预热步骤,并根据模型的大小改变学习速度和批量大小。
Alpaca模型

[Stanford CRFM]
中文聊天aipaca
GitHub - ymcui/Chinese-LLaMA-Alpaca
内容导引
| 章节 | 描述 |
|---|---|
| ⏬模型下载 | 中文LLaMA、Alpaca大模型下载地址 |
| 🈴合并模型 | (重要)介绍如何将下载的LoRA模型与原版LLaMA合并 |
| 💻本地推理与快速部署 | 介绍了如何对模型进行量化并使用个人电脑部署并体验大模型 |
| 💯系统效果 | 介绍了部分场景和任务下的使用体验效果 |
| 📝训练细节 | 介绍了中文LLaMA、Alpaca大模型的训练细节 |
安装
python3.8
# wget https://download.pytorch.org/whl/cu111/torch-1.10.2%2Bcu111-cp38-cp38-linux_x86_64.whl
# wget https://download.pytorch.org/whl/cu111/torchvision-0.11.3%2Bcu111-cp38-cp38-linux_x86_64.whl
# wget https://download.pytorch.org/whl/cu111/torchaudio-0.10.2%2Bcu111-cp38-cp38-linux_x86_64.whl
# torch+cuda
# 进入whl所在目录
pip3 install torch-1.10.2+cu111-cp38-cp38-linux_x86_64.whl torchaudio-0.10.2+cu111-cp38-cp38-linux_x86_64.whl torchvision-0.11.3+cu111-cp38-cp38-linux_x86_64.whl
# transformers
pip3 install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
# others
pip3 install fire fairscale sentencepiece -i https://pypi.tuna.tsinghua.edu.cn/simple
from:LLM:LLaMA模型和微调的Alpaca模型_-柚子皮-的博客-CSDN博客
ref:[代码角度看LLaMA语言模型:Meta最新模型LLaMA细节与代码详解]
[Meta最新语言模型LLaMA论文研读:小参数+大数据的开放、高效基础语言模型阅读笔记]*文章来源:https://www.toymoban.com/news/detail-496187.html
[LLaMA:开源的高效的基础语言模型 - 简书]文章来源地址https://www.toymoban.com/news/detail-496187.html
到了这里,关于LLM:LLaMA模型和微调的Alpaca模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![MedicalGPT:基于LLaMA-13B的中英医疗问答模型(LoRA)、实现包括二次预训练、有监督微调、奖励建模、强化学习训练[LLM:含Ziya-LLaMA]。](https://imgs.yssmx.com/Uploads/2024/02/828638-1.png)




