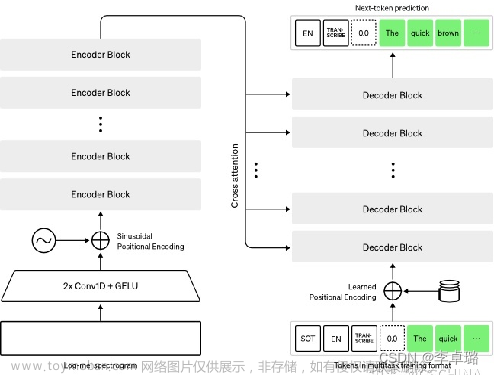
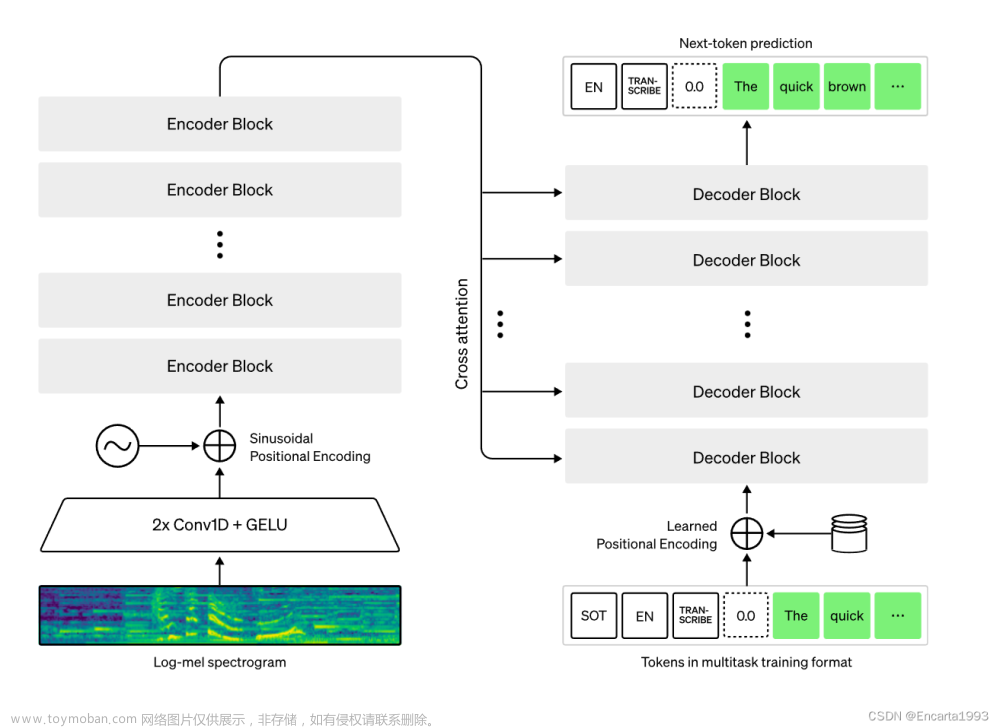
1.whisper部署
详细过程可以参照:🏠
创建项目文件夹
mkdir whisper cd whisperconda创建虚拟环境
conda create -n py310 python=3.10 -c conda-forge -y安装pytorch
pip install --pre torch torchvision torchaudio --extra-index-url下载whisper
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git安装相关包
pip install tqdm pip install numba pip install tiktoken==0.3.3 brew install ffmpeg测试一下whispet是否安装成功(默认识别为中文)
whisper test.wav --model small #test.wav为自己的测试wav文件,map3也支持 small是指用小模型whisper识别中文的时候经常会输出繁体,加入一下参数可以避免:
whisper test.wav --model small --language zh --initial_prompt "以下是普通话的句子。" #注意"以下是普通话的句子。"不能随便修改,只能是这句话才有效果。
2.脚本批量测试
创建test.sh脚本,输入一下内容,可以实现对某一文件夹下的wav文件逐个中文语音识别。
#!/bin/bash
for ((i=0;i<300;i++));do
file="wav/A13_${i}.wav"
if [ ! -f "$file" ];then
break
fi
whisper "$file" --model medium --output_dir denied --language zh --initial_prompt "以下是普通话的句子。"
done
实现英文语音识别需要修改为:
#!/bin/bash
for ((i=0;i<300;i++));do
file="en/${i}.wav"
if [ ! -f "$file" ];then
break
fi
whisper "$file" --model small --output_dir denied --language en
done
3.对运行出来的结果进行评测
一般地,语音识别通常采用WER,即词错误率,评估语音识别和文本转换质量。
这里我们主要采用 github上的开源项目:🌟 编写的python-wer代码对结果进行评价。
其中,我们的正确样本形式为:
whisper输出的预测结果形式为:
因此要对文本进行处理(去空格、去标点符号)后进行wer评价,相关代码如下:
(可根据具体情况修改calculate_WER)


import sys
import numpy
def editDistance(r, h):
'''
This function is to calculate the edit distance of reference sentence and the hypothesis sentence.
Main algorithm used is dynamic programming.
Attributes:
r -> the list of words produced by splitting reference sentence.
h -> the list of words produced by splitting hypothesis sentence.
'''
d = numpy.zeros((len(r)+1)*(len(h)+1), dtype=numpy.uint8).reshape((len(r)+1, len(h)+1))
for i in range(len(r)+1):
d[i][0] = i
for j in range(len(h)+1):
d[0][j] = j
for i in range(1, len(r)+1):
for j in range(1, len(h)+1):
if r[i-1] == h[j-1]:
d[i][j] = d[i-1][j-1]
else:
substitute = d[i-1][j-1] + 1
insert = d[i][j-1] + 1
delete = d[i-1][j] + 1
d[i][j] = min(substitute, insert, delete)
return d
def getStepList(r, h, d):
'''
This function is to get the list of steps in the process of dynamic programming.
Attributes:
r -> the list of words produced by splitting reference sentence.
h -> the list of words produced by splitting hypothesis sentence.
d -> the matrix built when calulating the editting distance of h and r.
'''
x = len(r)
y = len(h)
list = []
while True:
if x == 0 and y == 0:
break
elif x >= 1 and y >= 1 and d[x][y] == d[x-1][y-1] and r[x-1] == h[y-1]:
list.append("e")
x = x - 1
y = y - 1
elif y >= 1 and d[x][y] == d[x][y-1]+1:
list.append("i")
x = x
y = y - 1
elif x >= 1 and y >= 1 and d[x][y] == d[x-1][y-1]+1:
list.append("s")
x = x - 1
y = y - 1
else:
list.append("d")
x = x - 1
y = y
return list[::-1]
def alignedPrint(list, r, h, result):
'''
This funcition is to print the result of comparing reference and hypothesis sentences in an aligned way.
Attributes:
list -> the list of steps.
r -> the list of words produced by splitting reference sentence.
h -> the list of words produced by splitting hypothesis sentence.
result -> the rate calculated based on edit distance.
'''
print("REF:", end=" ")
for i in range(len(list)):
if list[i] == "i":
count = 0
for j in range(i):
if list[j] == "d":
count += 1
index = i - count
print(" "*(len(h[index])), end=" ")
elif list[i] == "s":
count1 = 0
for j in range(i):
if list[j] == "i":
count1 += 1
index1 = i - count1
count2 = 0
for j in range(i):
if list[j] == "d":
count2 += 1
index2 = i - count2
if len(r[index1]) < len(h[index2]):
print(r[index1] + " " * (len(h[index2])-len(r[index1])), end=" ")
else:
print(r[index1], end=" "),
else:
count = 0
for j in range(i):
if list[j] == "i":
count += 1
index = i - count
print(r[index], end=" "),
print("\nHYP:", end=" ")
for i in range(len(list)):
if list[i] == "d":
count = 0
for j in range(i):
if list[j] == "i":
count += 1
index = i - count
print(" " * (len(r[index])), end=" ")
elif list[i] == "s":
count1 = 0
for j in range(i):
if list[j] == "i":
count1 += 1
index1 = i - count1
count2 = 0
for j in range(i):
if list[j] == "d":
count2 += 1
index2 = i - count2
if len(r[index1]) > len(h[index2]):
print(h[index2] + " " * (len(r[index1])-len(h[index2])), end=" ")
else:
print(h[index2], end=" ")
else:
count = 0
for j in range(i):
if list[j] == "d":
count += 1
index = i - count
print(h[index], end=" ")
print("\nEVA:", end=" ")
for i in range(len(list)):
if list[i] == "d":
count = 0
for j in range(i):
if list[j] == "i":
count += 1
index = i - count
print("D" + " " * (len(r[index])-1), end=" ")
elif list[i] == "i":
count = 0
for j in range(i):
if list[j] == "d":
count += 1
index = i - count
print("I" + " " * (len(h[index])-1), end=" ")
elif list[i] == "s":
count1 = 0
for j in range(i):
if list[j] == "i":
count1 += 1
index1 = i - count1
count2 = 0
for j in range(i):
if list[j] == "d":
count2 += 1
index2 = i - count2
if len(r[index1]) > len(h[index2]):
print("S" + " " * (len(r[index1])-1), end=" ")
else:
print("S" + " " * (len(h[index2])-1), end=" ")
else:
count = 0
for j in range(i):
if list[j] == "i":
count += 1
index = i - count
print(" " * (len(r[index])), end=" ")
print("\nWER: " + result)
return result
def wer(r, h):
"""
This is a function that calculate the word error rate in ASR.
You can use it like this: wer("what is it".split(), "what is".split())
"""
# build the matrix
d = editDistance(r, h)
# find out the manipulation steps
list = getStepList(r, h, d)
# print the result in aligned way
result = float(d[len(r)][len(h)]) / len(r) * 100
result = str("%.2f" % result) + "%"
result=alignedPrint(list, r, h, result)
return result
# 计算总WER
def calculate_WER():
with open("whisper_out.txt", "r") as f:
text1_list = [i[11:].strip("\n") for i in f.readlines()]
with open("A13.txt", "r") as f:
text2_orgin_list = [i[11:].strip("\n") for i in f.readlines()]
total_distance = 0
total_length = 0
WER=0
symbols = ",@#¥%……&*()——+~!{}【】;‘:“”‘。?》《、"
# calculate distance between each pair of texts
for i in range(len(text1_list)):
match1 = re.search('[\u4e00-\u9fa5]', text1_list[i])
if match1:
index1 = match1.start()
else:
index1 = len(text1_list[i])
match2 = re.search('[\u4e00-\u9fa5]', text2_orgin_list[i])
if match2:
index2 = match2.start()
else:
index2 = len( text2_orgin_list[i])
result1= text1_list[i][index1:]
result1= result1.translate(str.maketrans('', '', symbols))
result2= text2_orgin_list[i][index2:]
result2=result2.replace(" ", "")
print(result1)
print(result2)
result=wer(result1,result2)
WER+=float(result.strip('%')) / 100
WER=WER/len(text1_list)
print("总WER:", WER)
print("总WER:", WER.__format__('0.2%'))
calculate_WER()评价结果形如:

4.与paddlespeech的测试对比:
| 数据集 |
数据量 |
paddle (中英文分开) |
paddle (同一模型) |
whisper(small) (同一模型) |
whisper(medium) (同一模型) |
||
| zhthchs30 (中文错字率) |
250 |
11.61% |
45.53% |
24.11% |
13.95% |
||
| LibriSpeech (英文错字率) |
125 |
7.76% |
50.88% |
9.31%文章来源:https://www.toymoban.com/news/detail-496316.html |
9.31% |
5.测试所用数据集
自己处理过的开源wav数据文章来源地址https://www.toymoban.com/news/detail-496316.html
到了这里,关于whisper语音识别部署及WER评价的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!