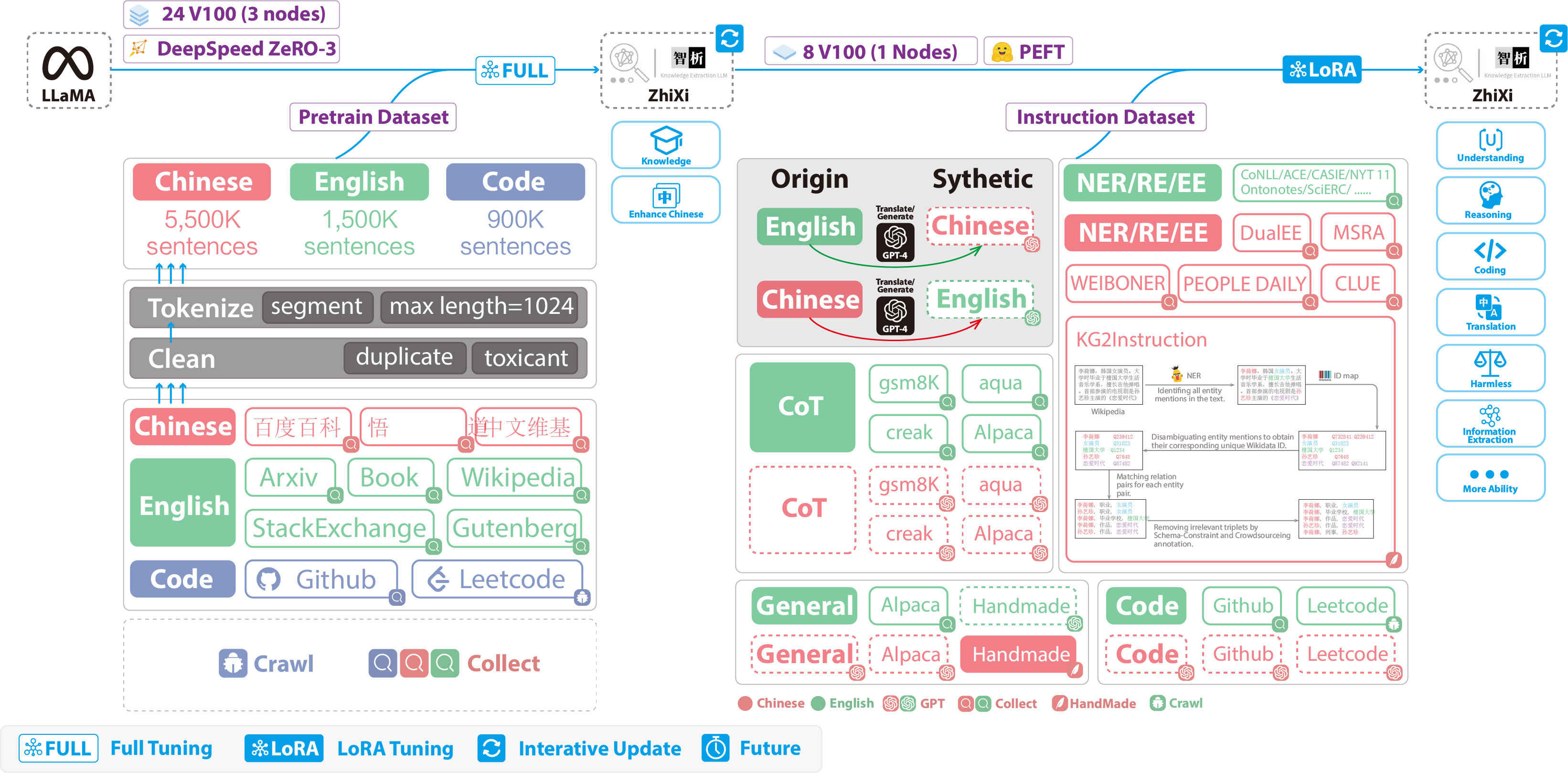
羊驼实战系列索引
博文1:本地部署中文LLaMA模型实战教程,民间羊驼模型
博文2:本地训练中文LLaMA模型实战教程,民间羊驼模型(本博客)
博文3:精调训练中文LLaMA模型实战教程,民间羊驼模型
简介
在学习完上篇【1本地部署中文LLaMA模型实战教程,民间羊驼模型】后,我们已经学会了下载模型,本地部署模型,部署为网页应用。
如果我们对于模型在某些方面的能力不够满意,想要赋予模型一些特殊的能力,那么我们可以选择领域内特殊的数据集,然后在基础模型上继续训练,从而得到一个新的模型。例如我们可以把医学知识用于训练模型,得到一个医生chatGPT;把佛学资料用于训练模型,得到一个佛祖chatGPT;人类的已有知识是海量的,智慧是无穷的,我相信大家一定有更好的想法!
本博客主要包含以下内容:
1训练数据准备,纯文本txt数据。
2训练脚本编写,主要参数讲解,消耗显存控制在24GB以内
3训练实战,测评。文章来源:https://www.toymoban.com/news/detail-496385.html
系统配置
系统:Ubuntu 20.10
CUDA Version: 11.8
GPU: RTX3090 24G
内文章来源地址https://www.toymoban.com/news/detail-496385.html
到了这里,关于本地训练中文LLaMA模型实战教程,民间羊驼模型,24G显存盘它!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[玩转AIGC]LLaMA2训练中文文章撰写神器(数据准备,数据处理,模型训练,模型推理)](https://imgs.yssmx.com/Uploads/2024/01/799326-1.png)