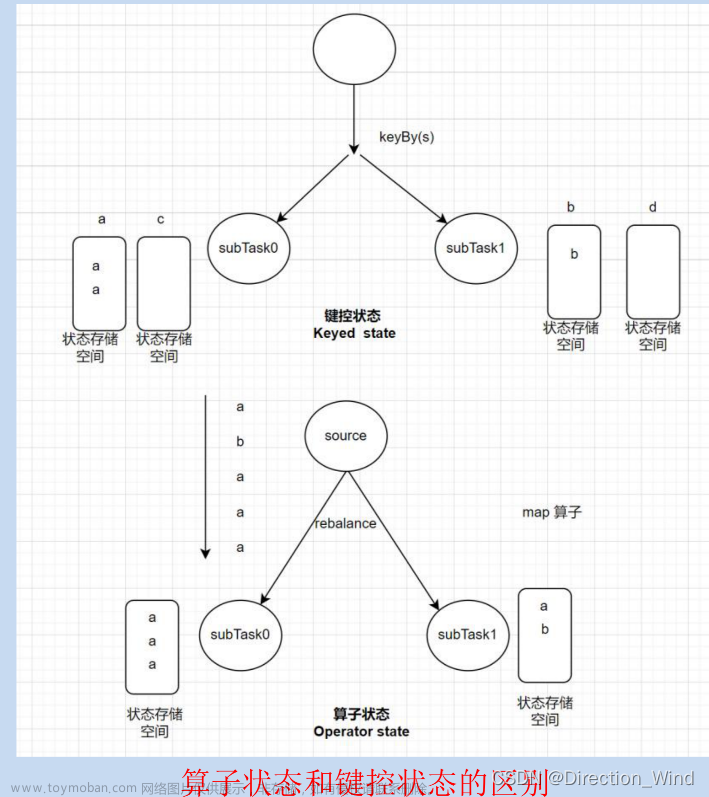
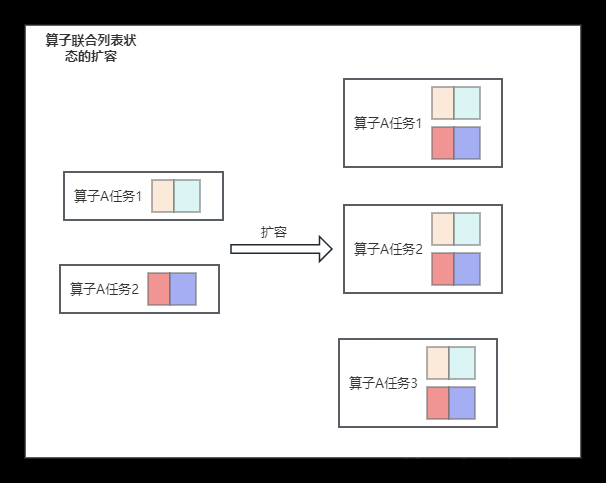
算子状态 (Operator State) : 一个算子并行实例上定义的状态,作用范围 : 当前算子任务
算子状态支持三种结构类型 : ListState、UnionListState、BroadcastState
列表状态
ListState : 将状态表示为列表 , 当前并行子任务上的所有状态项的集合
- 当算子并行度调整时,会把算子的列表状态都收集起来,再均匀分配 (轮询) 给所有并行任务
例子 : map 计算数据的个数
public class OperatorListStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("hadoop102", 7777)
.map(new MyCountMapFunction())
.print();
env.execute();
}
// 1.实现 CheckpointedFunction 接口
public static class MyCountMapFunction implements MapFunction<String, Long>, CheckpointedFunction {
private Long count = 0L;
private ListState<Long> state;
@Override
public Long map(String value) throws Exception {
return ++count;
}
// 2.本地变量持久化:将本地变量, 拷贝到算子状态中, 开启 checkpoint 时, 才会调用
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
System.out.println("snapshotState...");
// 2.1 清空算子状态
state.clear();
// 2.2 将 本地变量 添加到 算子状态 中
state.add(count);
}
// 3.初始化本地变量:程序启动和恢复时, 从状态中, 把数据添加到本地变量,每个子任务调用一次
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
System.out.println("initializeState...");
// 3.1 从上下文初始化算子状态
state = context.getOperatorStateStore()
.getListState(new ListStateDescriptor<Long>("state", Types.LONG));
// 3.2 从算子状态中, 把数据拷贝到本地变量
if (context.isRestored()) {
for (Long c : state.get()) {
count += c;
}
}
}
}
}
联合列表状态
联合列表状态 (UnionListState) : 将状态表示为一个列表
- 并行度调整时 : 常规列表状态是轮询分配状态项 ; 联合列表状态算子会直接广播状态的完整列表
- 注意 : 当列表大 , 会有效率问题
state = context.getOperatorStateStore()
.getUnionListState(new ListStateDescriptor<Long>("union-state", Types.LONG));
广播状态
广播状态 (BroadcastState) : 当所有分区的所有数据都访问同个状态文章来源:https://www.toymoban.com/news/detail-496671.html
- 当并行度调整时 , 复制到新并行子任务 ; 删除多余并行子任务
例子 : 水位 > 阈值, 就发送告警文章来源地址https://www.toymoban.com/news/detail-496671.html
public class OperatorBroadcastStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 数据流
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());
// 配置流(用来广播配置)
DataStreamSource<String> configDS = env.socketTextStream("hadoop102", 8888);
// 1. 将 配置流 广播
MapStateDescriptor<String, Integer> broadcastMapState = new MapStateDescriptor<>("broadcast-state", Types.STRING, Types.INT);
BroadcastStream<String> configBS = configDS.broadcast(broadcastMapState);
//2.把 数据流 和 广播后的配置流 connect
BroadcastConnectedStream<WaterSensor, String> sensorBCS = sensorDS.connect(configBS);
// 3.调用 process
sensorBCS.process(
new BroadcastProcessFunction<WaterSensor, String, String>() {
// 数据流的处理方法: 数据流 只能 读取 广播状态,不能修改
@Override
public void processElement(WaterSensor value, ReadOnlyContext ctx, Collector<String> out) throws Exception {
// 5.通过上下文获取广播状态,取出里面的值(只读,不能修改)
ReadOnlyBroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);
Integer threshold = broadcastState.get("threshold");
// 判断广播状态里是否有数据,因为刚启动时,可能是数据流的第一条数据先来
threshold = (threshold == null ? 0 : threshold);
if (value.getVc() > threshold) {
out.collect(value + ",水位超过指定的阈值:" + threshold + "!!!");
}
}
// 广播后的配置流的处理方法: 只有广播流才能修改 广播状态
@Override
public void processBroadcastElement(String value, Context ctx, Collector<String> out) throws Exception {
// 4. 通过上下文获取广播状态,往里面写数据
BroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);
broadcastState.put("threshold", Integer.valueOf(value));
}
}
).print();
env.execute();
}
}
到了这里,关于Flink 算子状态的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!