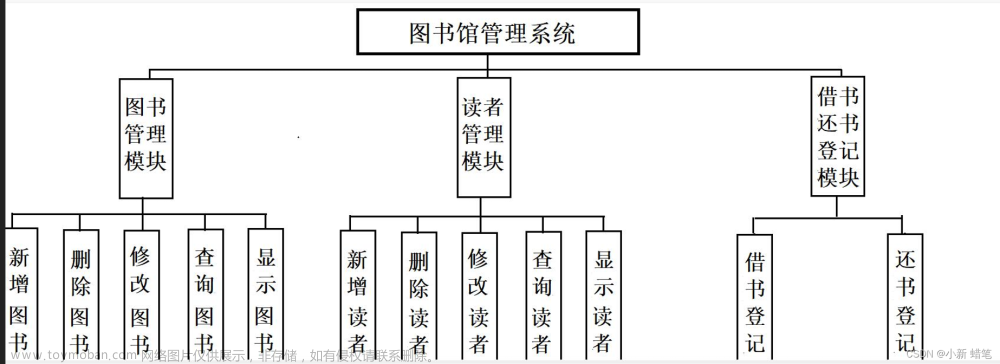
爬取的步骤
1. 爬取一章小说内容
2. 爬取一本小说内容
3. 实现搜索作者或者小说名字 进行下载说
4. 把程序打包成exe软件
# 爬虫基本步骤:
1. 发送请求
# 确定发送请求的url地址 我们请求网址是什么
# 确定发送请求的方式是什么 get请求 post请求
# headers 请求参数
2. 获取数据
# 获取[服务器]返回的数据内容 (千万别只盯着元素面板)
3. 解析数据
# 提取我们想要的数据内容 小说内容 小说标题
4. 保存数据
# 保存到本地文件 txt文章来源:https://www.toymoban.com/news/detail-496682.html
根据项目主题,设计项目实施方案,包括实现思路与技术难点等文章来源地址https://www.toymoban.com/news/detail-496682.html
# 导入数据请求模块 pip install requests
import requests
# 数据解析模块 pip install parsel
import parsel
# 进度条显示 pip install tqdm
from tqdm import tqdm
#数据分析
import pandas as pd
import numpy as np
#云词库
import jieba
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from PIL import Image
from os import path
#数据可视化
import matplotlib.pyplot as plt
import numpy as np
import random
def get_response(html_url):
"""发送请求"""
# headers 请求头 作用就是把python代码伪装成浏览器 去发送请求 一种简单的反反爬手段
# 对于某些网站 没有加headers 可能会被服务器识别出来 是你爬虫程序, 从而不会给你返回相应的数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
# 通过requests这个模块get请求方法 对于url地址发送请求 并且携带上面headers请求头 , 最后用自定义变量response接收返回数据
response = requests.get(url=html_url, headers=headers)
return response
def get_novel_list_url(html_url):
"""获取小说章节的url地址"""
response = get_response(html_url)
selector = parsel.Selector(response.text)
# 获取标签属性内容 attr(属性名字)
href = selector.css('#list dd a::attr(href)').getall()
# print(href)
return href
def save(name, title, content):
"""数据保存"""
with open(name + '.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
# print(title, '正在保存')
def get_novel_content(name, html_url):
"""获取小说内容"""
response = get_response(html_url)
selector = parsel.Selector(response.text) # 把获取下面html字符串数据 转换成 selector对象
# selector对象 调用里面 xpath或者css用法
# css选择器 根据标签属性提取数据内容
# get() 获取第一个标签内容返回的字符串数据 text 获取这个标签的文本数据
# getall 获取所有标签内容 返回的列表数据类型
# 标签里面class类属性 小圆点. 代替加上的名字
# 标签里面id 用# 代替 加上名字
title_name = selector.css('.bookname h1::text').get() # 小说章节名字 提取下来了
content_list = selector.css('#content::text').getall() # 小说的内容
# 保存数据 保存到本文 txt里面 字符串数据保存 就把我们 列表转成字符串
# 把列表转成字符串 join 用一个换行符 把列表元素合并起来 变成一个字符串数据
novel_content = '\n'.join(content_list).replace('? 笔????趣阁 ?? w?w?w?.?b?i?q?u?g?e?.cn', '')
save(name, title_name, novel_content)
def main(html_url):
"""主函数 前面写好的函数 功能模块整合到一起"""
href = get_novel_list_url(html_url)
response = get_response(html_url)
selector = parsel.Selector(response.text)
novel_name = selector.css('#info h1::text').get() # 获取小说名字
for link in tqdm(href):
link_url = 'https://www.biqugee.com' + link
get_novel_content(novel_name, link_url)
if __name__ == '__main__':
# url = 'https://www.biqugee.com/book/5527/'
# main(url)
while True:
key_word = input('请输入你想要下载的小说(输入0即可退出程序): ')
if key_word == '0':
break
html_url = f'https://www.biqugee.com/search.php?q={key_word}'
response = get_response(html_url)
selector = parsel.Selector(response.text)
divs = selector.css('div.result-list div.result-item')
if divs:
lis = []
for div in divs:
name = div.css('.result-game-item-title-link::attr(title)').get() # 小说名字
novel_id = div.css('.result-game-item-title-link::attr(href)').get().split('/')[2] # 小说ID
author = div.css('.result-game-item-info p:nth-child(1) span:nth-child(2)::text').get() # 小说作者
dit = {
'小说': name,
'作者': author,
'书ID': novel_id,
}
lis.append(dit)
print(f'一共搜索到{len(lis)}条数据, 结果如下: ')
search_results = pd.DataFrame(lis)
print(search_results)
num = input('请输入你想要下载的小说序号: ')
novel_id = lis[int(num)]['书ID']
# 字符串格式化的方法 ...
url = f'https://www.biqugee.com/book/{novel_id}/'
print('你想要下载的小说url地址是: ', url)
main(url)
else:
print('没有搜索到内容, 请重新输入')
# # 1. 发送请求
# url = 'https://www.biqugee.com/book/5527/2130010.html'
# # headers 请求头 作用就是把python代码伪装成浏览器 去发送请求 一种简单的反反爬手段
# # 对于某些网站 没有加headers 可能会被服务器识别出来 是你爬虫程序, 从而不会给你返回相应的数据
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
# }
# # 通过requests这个模块get请求方法 对于url地址发送请求 并且携带上面headers请求头 , 最后用自定义变量response接收返回数据
# response = requests.get(url=url, headers=headers)
# # 2. 获取数据 <Response [200]> response对象 200 状态码表示请求成功
# # print(response.text) # response.text 获取响应体的文本数据 返回html字符串数据
# # 3. 解析数据
# selector = parsel.Selector(response.text) # 把获取下面html字符串数据 转换成 selector对象
# # selector对象 调用里面 xpath或者css用法
# # css选择器 根据标签属性提取数据内容
# # get() 获取第一个标签内容返回的字符串数据 text 获取这个标签的文本数据
# # getall 获取所有标签内容 返回的列表数据类型
# # 标签里面class类属性 小圆点. 代替加上的名字
# # 标签里面id 用# 代替 加上名字
# title_name = selector.css('.bookname h1::text').get() # 小说章节名字 提取下来了
# content_list = selector.css('#content::text').getall() # 小说的内容
# # 保存数据 保存到本文 txt里面 字符串数据保存 就把我们 列表转成字符串
# novel_content = '\n'.join(content_list).replace('? 笔????趣阁 ?? w?w?w?.?b?i?q?u?g?e?.cn', '')
# print(title_name)
# print(novel_content)
# with open(title_name + '.txt', mode='a', encoding='utf-8') as f:
# f.write(title_name)
# f.write('\n')
# f.write(novel_content)
#以字典的形式输出
with open("D:/Users/Admin/PycharmProjects/pythonProject1/venv/斗破苍穹之我的师父是云韵.txt","r",encoding="UTF-8") as df:
de = df.read()
df.close()
# jieba库分词
ls = jieba.lcut(de)
# 建立空字典进行词频统计
d = {}
# jieba库分词为ls(含有'\xa0','/n')
# for i in ls:
# if i == "\xa0":
# pass
# elif i == '\n':
# pass
# else:
# # print(i)
# d[i] = d.get(i, 0) + 1
# value_dict = sorted(d.items(), key=lambda d: d[1], reverse=True)
# for i in value_dict:
# print(i)
#符号居多去除符号
for i in ls:
if i == "\xa0":
continue
elif i == '\n':
continue
elif i in ', 。 “ ” … !? ?':
print(2)
else:
d[i] = d.get(i, 0) + 1
value_dict=sorted(d.items(), key=lambda d: d[1],reverse=True)
print(value_dict)
c = []
x =[]
for i in value_dict:
c.append(i[0])
x.append(i[1])
txt = " ".join(c)
# 导入自定义图片作为背景
backgroud_Image = plt.imread('C:/Users/Admin/Desktop/蜡笔小新.jpg')
print('加载图片成功!')
w = WordCloud(
# 汉字设计
font_path="msyh.ttc",
# 宽度设置
width=1000,
# 高度设置
height=800,
# 设置背景颜色
background_color="white",
# 设置停用词
stopwords=STOPWORDS,
## 设置字体最大值
max_font_size=150,
)
w.generate(txt)
print('开始加载文本')
img_colors = ImageColorGenerator(backgroud_Image)
# 字体颜色为背景图片的颜色
w.recolor(color_func=img_colors)
# 显示词云图
plt.imshow(w)
# 是否显示x轴、y轴下标
plt.axis('off')
# 显示图片
plt.show()
# 获得模块所在的路径的
d = path.dirname(__file__)
# w.to_file(d,"C:/Users/Admin/Desktop/wordcloud.jpg")!!!!!!!!!!!
print('生成词云成功!')
#数据可视化
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
##value_dict 数据字典
#作者喜欢用显示前20条数据
plt.bar(c[:20],x[:20])
plt.show()
#绘制饼图
plt.figure(figsize=(12,8))
# 定义饼图的标签,标签是列表
labels = c[:10]
#绘图数据
plt.pie(x=x[:10], #绘图数据
#添加教育水平标签
labels=labels,
#设置百分比的格式,这里保留两位小
autopct='%.2f%%',
#设置百分比标签与圆心的距离
pctdistance=0.8,
#设置教育水平标签与圆心的距离
labeldistance=1.1,
#设置饼图的初始角度
startangle=180,
#设置饼图的半径
radius=1.2,
#是否逆时针,这里设置为顺时针方向
counterclock=False,
# 设置饼图内外边界的属性值
wedgeprops={'linewidth':1.5, 'edgecolor':'green'},
# 设置文本标签的属性值
textprops={'fontsize':10, 'color':'black'},
)
plt.title("字数统计")
plt.show()
#绘制环形图
fig, ax = plt.subplots(figsize=(6, 6))
wedgeprops = {'width':0.3, 'edgecolor':'black', 'linewidth':3}
ax.pie([87,13], wedgeprops=wedgeprops, startangle=90, colors=['#5DADE2', '#515A5A'])
plt.title('环形图', fontsize=24, loc='center')
plt.text(0, 0, "31.59%", ha='center', va='center', fontsize=42)
plt.text(-1.2, -1.2, "运用最多的字占比", ha='left', va='center', fontsize=12)
#绘制散点折线图
plt.figure(figsize=(12,8))
plt.plot(x[:30], c[:30], c='coral',linestyle=':',linewidth=2,label='Myanmar')
plt.scatter(x[:30], c[:30],s=15,)
plt.show()
plt.figure(figsize=(12,6))
#散点拟合
x_1=list(range(1,len(x)+1))
x_2 = np.array(x)
z1 = np.polyfit(x_1,x_2,2)
p1 = np.poly1d(z1)
print(p1)
yvals = p1(x)
plot1 = plt.plot(x_1,x_2,"*",label = "numpy")
plot1 = plt.plot(x_1,yvals,"r",label = "value")
plt.legend(loc = 4)
plt.title("散点拟合")
plt.show()到了这里,关于Python爬虫期末设计(内含源代码及实验报告)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!