前言
本文首先简单介绍 Stable Diffusion 模型结构 Latent Diffusion 的论文和博客,然后介绍模型的训练和推理技术细节(不含数学推导),接着介绍几个 prompt 搜索引擎等实用工具,最后简单介绍 AI 作画(图像生成)的发展史,并测试了 Stable Diffusion 不同风格和 prompt 的生成样例。
模型简介
Model:Latent Diffusion
Paper:High-Resolution Image Synthesis with Latent Diffusion Models
Huggingface官方博客:
- Stable Diffusion with 🧨 Diffusers
- The Annotated Diffusion Model
训练集:LAION-high-resolution 和 LAION-Aesthetics
使用协议:stable-diffusion-license(不要生成违禁图;SD放弃版权;商用时也需遵守上面协议)
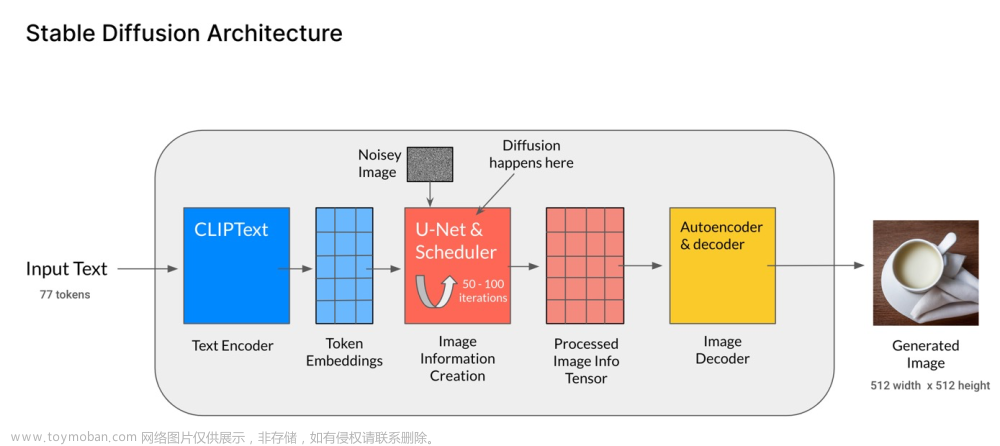
模型结构图: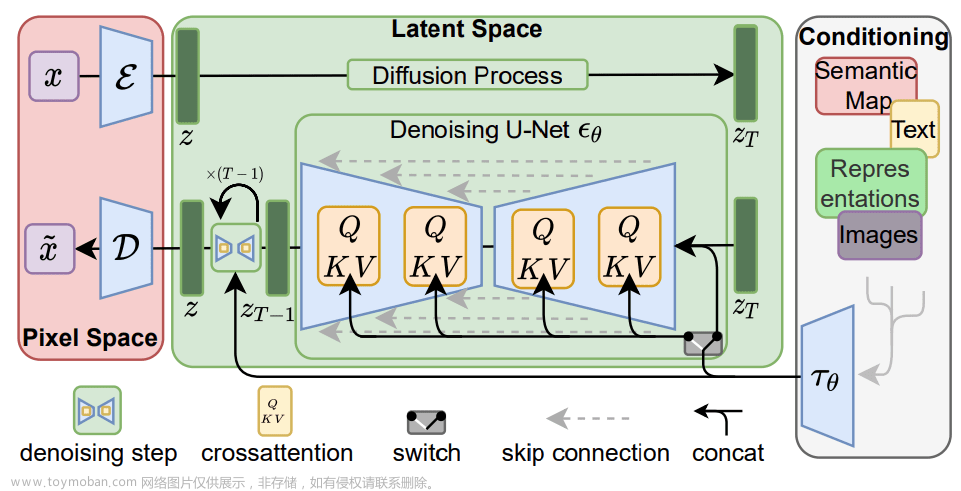
模型原理(图源Twitter):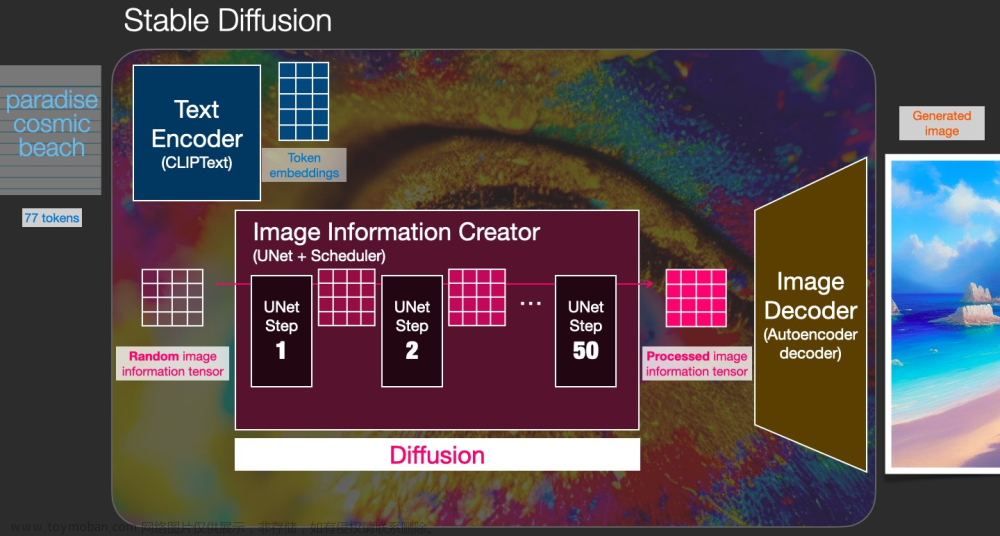 文章来源:https://www.toymoban.com/news/detail-496734.html
文章来源:https://www.toymoban.com/news/detail-496734.html
模型训练
本部分内容主要翻译自 Huggingface官方博客。文章来源地址https://www.toymoban.com/news/detail-496734.html
- 训练目标:一步步对随机的高斯噪声降噪(denoise),参考 diffusers colab。

- 优势:Latent diffusion 之所以是 “latent”,是因为模型是在低维的潜空间(latent space)上进行扩散过程,而不是在实际的像素空间,从而降低了内存消耗和计算复杂度(比如输入shape是(3,512,512),下采样因子是8,潜空间中变成了(3,64,64),节省了8×8=64倍的内存)。训练完之后的模型就能把一张图表示成一个低维的潜特征。
- Latent diffusion 模型的三大核心部分:
- Text Encoder:把 prompt 表示成潜特征,从而可以输入到 U-Net。Stable Diffusion 直接用了CLIP 预训练的 Text Encoder,冻结权重。
- VAE:VAE 的 encoder 用来将图片编码成潜特征(作为U-Net的输入),decoder 用来将潜特征转成图像。显然推理时只用到了VAE的decoder。
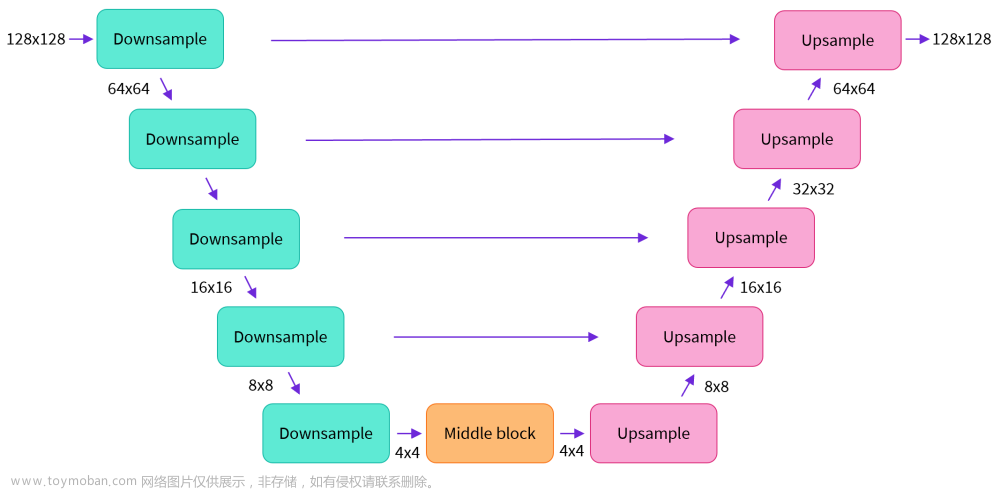
- U-Net:由 encoder 和 decoder 都是由 ResNet blocks 构成。其中 encoder 用来下采样(降低分辨率),decoder 用来上采样(升高分辨率)。U-Net 的输出预测了噪声的残差,可用于计算预测的去噪图像表示。为了防止下采样时损失信息,通常把同一层上下采样的 ResNet 之间给连起来。此外,Stable Diffusion 的 U-Net 还能通过 cross-attention 层把 prompt 的表示给嵌入(U-Net的encoder和decoder都加了cross-attention层,在ResNet blocks之间加)。
到了这里,关于AI 作画:Stable Diffusion 模型原理与实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!