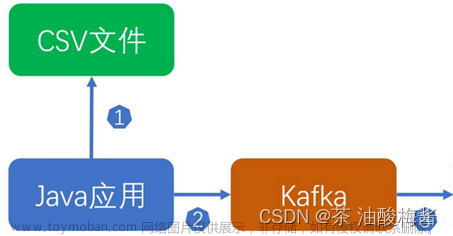
一、概述
1. Kafka介绍
Apache Kafka是一个分布式的流处理平台。它最初是由LinkedIn开发并开源的,现在已经成为Apache软件基金会旗下的顶级项目之一。Kafka主要用于实时流数据的高吞吐量传输、存储和处理,例如日志收集、流式的ETL以及实时的Web日志等。
2. Spark介绍
Apache Spark是一个用于大规模数据处理的通用引擎,最初也是由Spark项目组织开发,并被捐赠给了Apache软件基金会。Spark提供了丰富的数据处理接口,包括批处理、交互式查询和流处理等,比传统的Hadoop MapReduce计算速度更快,易于使用和开发。
3. 实时计算系统的定义和特点
实时计算系统是指能够实时地进行数据处理和分析的系统,典型的应用场景包括金融交易处理、物流路线优化、在线广告投放等。实时计算系统具有以下特点:
- 时间敏感性:实时计算系统要求能够在毫秒级别内快速地对数据进行响应和处理。
- 大规模性:实时计算系统需要能够有效地处理大量的数据,应对复杂多变的业务场景。
- 高可靠性:实时计算系统要求能够保证数据处理的准确性和稳定性,降低错误率和故障率。
- 可扩展性:实时计算系统需要具备良好的可扩展性和容错性,能够对数据进行水平扩展和负载均衡。
代码示例:
以下是Java代码示例,用于将Kafka中的实时流式数据读取并进行Spark流式处理:
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class KafkaSparkStreaming {
public static void main(String[] args) throws Exception {
// 创建SparkConf对象
SparkConf conf = new SparkConf().setAppName("KafkaSparkStreaming").setMaster("local[*]");
// 创建JavaStreamingContext对象,并设置批处理间隔
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
// 设置Kafka相关参数
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "localhost:9092");
kafkaParams.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaParams.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaParams.put("group.id", "test-group");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
// 设置需要读取的主题
Collection<String> topics = Arrays.asList("test-topic");
// 从Kafka中读取实时流数据,并进行处理
JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams));
stream.foreachRDD(rdd -> {
rdd.foreach(record -> {
System.out.println(record.value());
// 进行Spark流式处理,例如WordCount等业务逻辑
});
});
// 启动流式处理任务
jssc.start();
jssc.awaitTermination();
}
}
以上是一个简单的Kafka和Spark集成的示例其中使用了Spark Streaming API对从Kafka中读取的实时流数据进行处理。通过该样例,我们可以更好地理解实时计算系统在大数据分析和处理中的重要性和灵活性。
二、实时计算系统设计
1. 数据采集阶段
在这个阶段需要采集源数据并将其发送到Kafka集群中。可以使用各种方式来收集数据,比如通过HTTP协议、文件系统或者其他API接口。
2. 消息传输阶段
消息传输阶段是指从Kafka集群中获取数据,然后将其传输到Spark集群进行处理。在这一阶段,您需要确保Kafka集群能够支持高吞吐量的消息传输,并控制消息传输的速率。
3. 数据处理和计算阶段
在这个阶段需要定义Spark的数据流处理任务。通过Spark Streaming,你可以对数据进行实时处理、聚合、分析等操作。在处理数据的过程中可以根据需要使用各种算法和函数库。
以下是一个简单的示例:
// 创建SparkConf对象
SparkConf conf = new SparkConf().setAppName("Data Processing");
// 创建JavaStreamingContext对象
JavaStreamingContext jssc = new JavaStreamingContext(conf, new Duration(1000));
// 从Kafka中读取数据
JavaPairInputDStream<String, String> messages = KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParams,
topicsSet
);
// 通过flatMap算子对数据进行处理
JavaDStream<String> lines = messages.flatMap(x -> Arrays.asList(x._2.split(" ")).iterator());
// 通过window()函数定义滑动窗口,设置窗口大小和步长
JavaDStream<String> windowedWordCounts = lines.window(Durations.seconds(30), Durations.seconds(10))
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a, b) -> a + b)
.filter(count -> count._2() > 10)
.map(wordCount -> wordCount._1() + ": " + wordCount._2());
// 打印结果流
windowedWordCounts.print();
// 启动JavaStreamingContext
jssc.start();
jssc.awaitTermination();
4. 数据存储和查询阶段
在这个阶段需要将处理后的数据存储到适当的数据库中(如HBase,Cassandra)。存储和查询操作可以是实时的,也可以是定期的。您可以根据自己的业务需要选择合适的存储方式,并使用Spark SQL等工具来查询数据。
三、实时计算系统的应用
1.Kafka在实时计算系统中的作用
Kafka是一个高吞吐量的分布式消息系统,常用于大规模数据处理场景中的数据缓存和传输。在实时计算系统中,Kafka扮演了以下角色:
a.消息缓存和传输
Kafka可以接受和存储多个数据来源的数据,并将其传输到指定的目标地点。对于实时计算任务而言,操作人员可以根据实际业务需求设定关注的数据源和目标点,确保数据传输的高效性和准确性。
b.数据分区和负载均衡
在实时计算过程中,存在大量的数据处理请求需要同时进行,对于一个分布式处理系统而言,这些请求需要被合理地分摊到多个处理集群中,以提高整个系统的运行效率。Kafka通过对数据进行分区,将相同类型或者相关的数据放在同一个分区中,最终确保数据的处理过程更加均衡。
c.高可靠性和容错处理
Kafka在数据传输和存储过程中非常注重数据的准确性和可靠性,它能够在数据传输过程中自动进行数据备份和故障转移,确保数据的连续可靠性。在实时计算场景下,Kafka能够帮助操作人员有效地处理数据的丢失或被破坏等意外情况。
2.Spark在实时计算系统中的作用
Spark是一个基于内存计算的大数据计算框架,常用于实时流计算和批处理。在实时计算系统中,Spark扮演了以下角色:
a.实时流计算和批处理
Spark Streaming可以直接读取Kafka生成的实时消息流,并进行流式计算。通过将数据流分成一系列的小批次进行实时计算,Spark能够完美地支持实时数据处理,并且其底层的弹性分布式数据集RDD(Resilient Distributed Dataset)也保证了数据在计算过程中不受损坏。
b.窗口统计和聚合分析
Spark能够快速准确地进行数据窗口操作,例如数据统计、聚合分析等,支持多种类型的窗口操作,包括滑动窗口、时间窗口等,对于数据可视化和报表生成等任务具有重要作用。文章来源:https://www.toymoban.com/news/detail-496786.html
c.数据可视化和报表生成
最终,通过调用相关的可视化工具,Spark还能够将处理后的数据以可视化图表的形式呈现出来,并生成各种定制化的报表。这不仅提高了业务数据分析的效率,也能够帮助操作人员更好地理解处理后的实时数据。文章来源地址https://www.toymoban.com/news/detail-496786.html
//数据读取
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.kafka.common.serialization.StringDeserializer;
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "localhost:9092,anotherhost:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "use_a_separate_group_id_for_each_stream");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
Collection<String> topics = Arrays.asList("topicA", "topicB");
JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams)
);
四、实时计算系统的优缺点
1. 优点
a.性能高,响应快
- Kafka和Spark都是被设计用来处理大量数据、支持高并发的系统,因此基于这两个框架实现的实时计算系统可以具有出色的性能。
- Kafka具有高吞吐量和低延迟的特性,在生产者和消费者之间构建了一种高效的异步通信机制,同时也保证了数据的可靠性。
- Spark作为一个内存计算框架,可以快速并行处理数据,并且具备分布式计算能力,因此也能保障实时计算系统的性能。
b.容易扩展和部署
- Kafka和Spark都是开源的分布式系统,拥有大量社区支持。因此,在实现实时计算系统时,开发者可以借助这些社区提供的文档和工具来轻松地进行部署和扩展。
- Kafka在设计上考虑到了扩展性,可以基于集群模式来进行横向扩展,但是却不会降低其性能。
- Spark通过Spark Streaming组件,可以将数据流合并到一个连续的RDD(弹性分布式数据集)中,以便于进一步操作。这种处理方式与Spark进行批处理的方式相同,因此也很容易进行部署和扩展。
c.兼容多种数据源和格式
- Kafka支持多种协议(如HTTP、TCP和IPC)和多种编码格式(如AVRO、JSON等),这使得实时计算系统能够兼容多种数据源和不同格式的数据。
- Spark可以与各种数据源(如Hadoop、Cassandra、HBase)以及多种文件格式(如文本文件、JSON和Parquet)进行交互。
2. 缺点
a.对硬件和软件要求较高
- 实时计算需要消耗大量的CPU、内存和带宽资源,因此需要相对较高配置的硬件。
- 在软件方面,Kafka和Spark都需要在集群环境中运行。由于集群计算的特殊性,需要有专门的运维人员来进行管理和维护。
b.维护和管理成本较高
- 由于实时计算需要监视和控制不断变化的数据流,因此需要运维人员定期维护和管理系统,以保证其稳定性和可用性。
- 另外,由于Kafka和Spark都需要与其他组件(如Hadoop、Cassandra等)相结合,因此开发者需要投入额外的精力来管理和协调这些不同的工具。
c.实时性和准确性需要保证
- 实现实时计算系统需要实时更新数据,因此需要通过适当的技术手段来提高系统的实时性。
- 同时,在实时计算过程中,需要保证数据的准确性,避免出现因为网络延迟、数据丢失或其他原因导致的误差。这需要在技术实现上加以保障。
到了这里,关于基于Kafka和Spark实现实时计算系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!