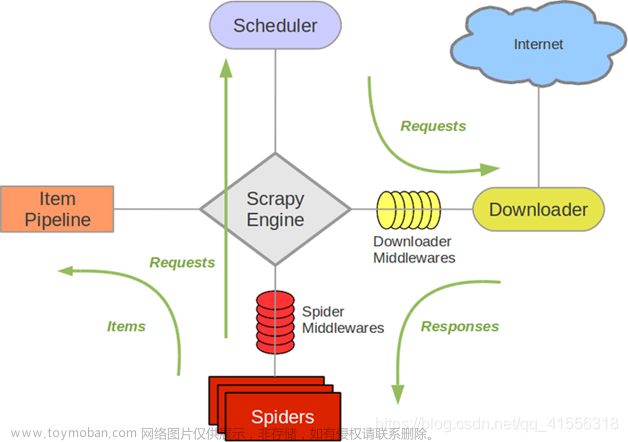
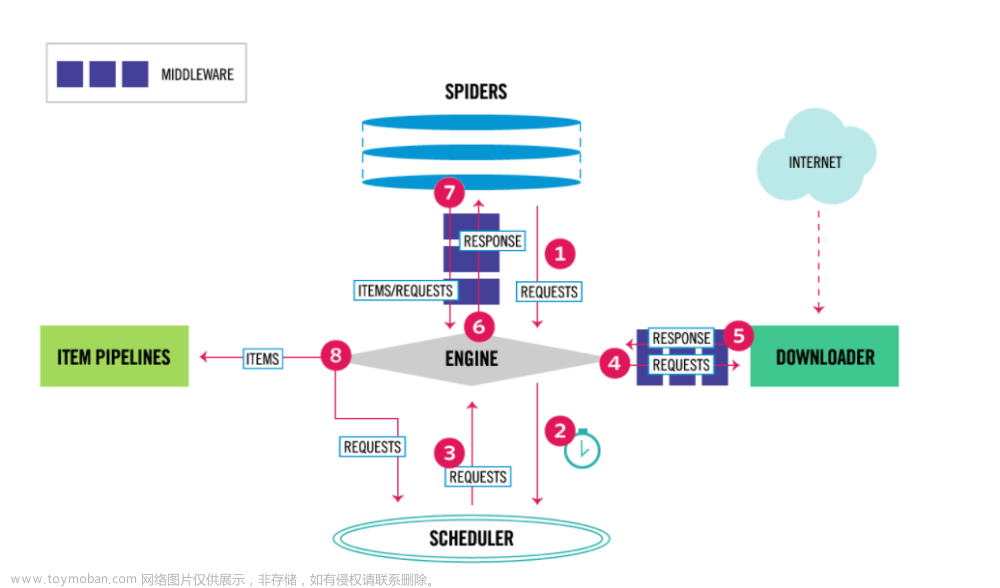
重写框架自带媒体管道类部分方法实现保存图片名字的自定义:
- spider文件中要拿到图片列表并yield item;
- item里需要定义特殊的字段名:image_urls=scrapy.Field();
- settings里设置IMAGES_STORE存储路径,如果路径不存在,系统会帮助我们创建;
- 使用默认管道则在s
文章来源地址https://www.toymoban.com/news/detail-496937.html
文章来源:https://www.toymoban.com/news/detail-496937.html
到了这里,关于Python爬虫之Scrapy框架系列(21)——重写媒体管道类实现保存图片名字自定义及多页爬取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!