一 回顾BeautifulSoup库
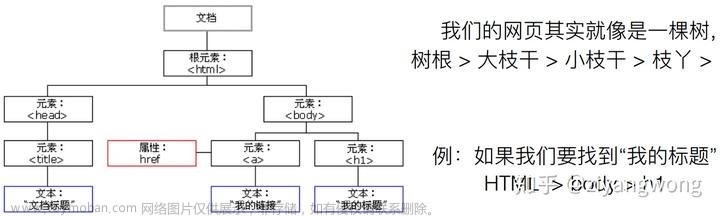
BeautifulSoup是Python的一个HTML/XML解析库,用于从HTML或XML文件中提取数据。结合Python的requests库,可以实现网页爬取和数据提取。
以下是一个简单的使用BeautifulSoup和requests库实现爬虫的示例:文章来源:https://www.toymoban.com/news/detail-496939.html
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 提取所有链接
links = soup.find_all('a')
for link in links:
print(link.get('href'))
# 提取页面标题
title = soup.title.string
print(title)
二 上操作
用requests库和BeautifulSoup4库,爬取校园新闻列表的时间、标题、链接、来源。文章来源地址https://www.toymoban.com/news/detail-496939.html
import requests
from bs4 import BeautifulSoup
re = requests.get("http://news.gzcc.cn/html/xiaoyuanxinwen/")
re.encoding = 'utf-8'
soup = BeautifulSoup(re.te到了这里,关于使用Python的Requests和BeautifulSoup库来爬取新闻网站的新闻标题、发布时间、内容等信息,并将数据存储到数据库中的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!