基于ChatGPT的端到端语音聊天机器人项目实战
ChatGPT API后台开发实战
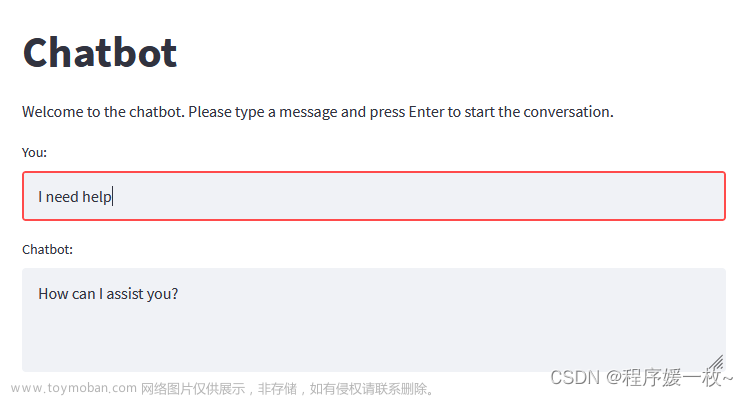
本节主要是跟大家分享一个端到端的基于模型驱动的对话机器人,会有前端和后端,也会有一些具体模型的调用,读者需具有Python语言编程的基础,这是前置性的条件,有了这个基础,理论上讲本节所有的内容,读者都可以掌握,这个语音聊天软件包含三部分, Frontend是前端,Backend是后台,模型层是ChatGPT或者大型语言模型(Large Language Models),如图1-1所示。 文章来源:https://www.toymoban.com/news/detail-497149.html
文章来源:https://www.toymoban.com/news/detail-497149.html
图1- 1 语音聊天软件架构图
从生产级开发架构的角度,会使用框架耦合掉后端和具体的模型层,Framework框架可以调用后端的任何模型,包括Google的模型,也有一些开源的模型,一个很重要的来源是Hugging Face,后端呼叫API的部分往往是跟模型本身进行交互,数据的部分称为私域数据(Private Data),私域数据跟模型训练数据是不一样的,它可能是企业的私有数据,也可能是企业服务于用户的过程中,每个用户产生的数据,这肯定是绝对的核心,每一个企业做产品的时候,用户数据是核心的资产、价值或者竞争力,因为现在很多模型都是通用的,模型本身并不能直接带来产品价值的差异化,而拥有的数据是一个核心竞争力的基础,在框架的支持下,数据和模型进行互动,这是技术的核心。作为生产级的开发文章来源地址https://www.toymoban.com/news/detail-497149.html
到了这里,关于基于ChatGPT的端到端语音聊天机器人项目实战(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!