elasticSearch写入原理
最近学习完了es相关的课程整理除了es的核心内容,学习这东西知其然知其所以然,自己按照自己的理解整理了es相关的面试题。先热个身,整理一下es的写入原理,有不对的地方请大家指正。
这些原理的东西我觉得还是流程图比较好理解一点,先从流程图开始吧
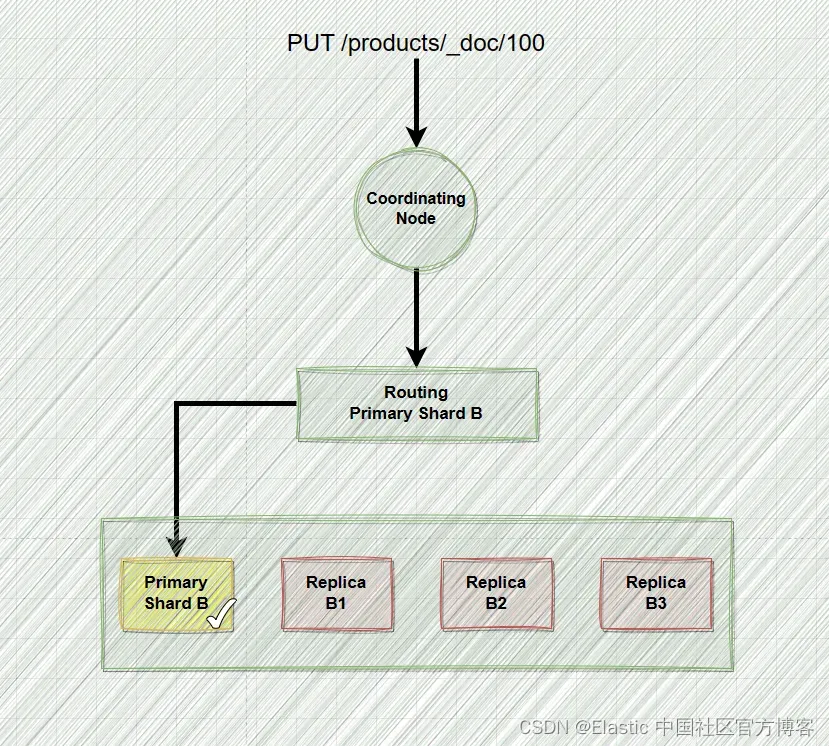
一、es 写入流程图展示

二、详细步骤
-
客户端写入数据先到内存的buffer当中
-
当内存buffer达到一定容量的阈值或者设定时间的阈值时,内存buffer的数据会refresh到segment file 文件当中,并且与此同时会向translog文件中写入数据。(默认refresh的时间是1s)
== 补充==
什么是segment file文件?
每一个segment file 文件就是一个倒排索引文件.
========================================================================
refresh 操作是发生在JVM当中的肯定会消耗服务器的堆内存,refresh的次数越好越好
-
当segment file文件达到一定的阈值会触发Commit point ,把segment 的文件merge 写入到OSCache 文件当中,并且会把当谢写入到segment file文件标记为删除
== 补充 ==
Commit Point
1.选择相似的segment file文件进行合并
2.flush数据
3.创建新的commit point状态标记新的segment file 文件,删除旧的commit point
4.将新的commit point 搜索状态打开
5.删除旧的segment file 文件
-
写入到OS Cache 之后会迅速做出反应 segment file文件的状态就会变成open,这样数据就可以查询了
== 补充 ==
OS Cache 是基于物理内存.写入到OSCache之后要清空buffer文章来源:https://www.toymoban.com/news/detail-497204.html
OS Cache 是基于物理内存.写入到OSCache之后要清空buffer
-
当OS Cache的数据到达一定的阈值或者每隔30分钟 ,就会执行commit操作把OS Cache中的数据写入到OS Disk当中,并且清空Translog 文件。文章来源地址https://www.toymoban.com/news/detail-497204.html
到了这里,关于elasticSearch写入原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!