本文首发于公众号:Hunter后端
原文链接:celery笔记六之worker介绍
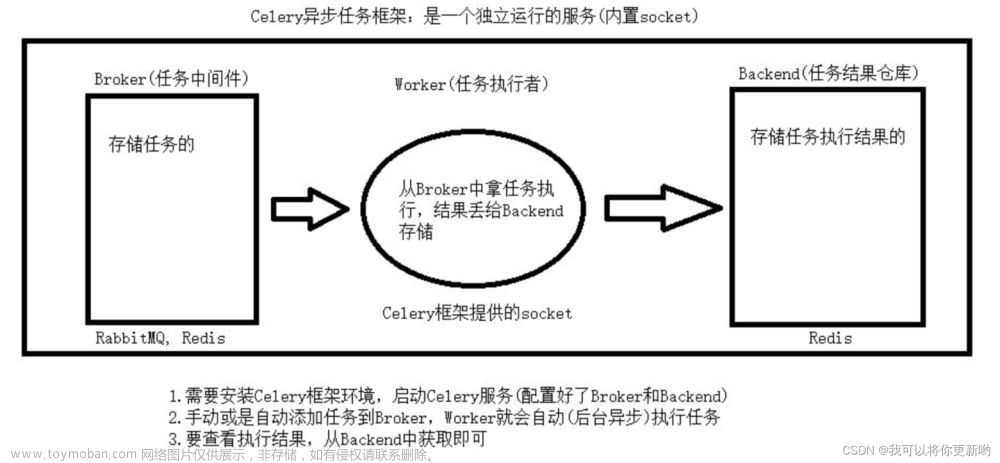
前面我们介绍过 celery 的理想的设计方式是几个 worker 处理特定的任务队列的数据,这样可以避免任务在队列中的积压。
这一篇笔记我们介绍一下如何使用 worker 提高系统中任务的处理效率。
- worker启动
- worker与队列
- worker检测
- 其他worker命令
1、worker 启动
前面介绍过 worker 的启动方式,在 celery 配置文件的上一级目录运行下面的命令:
celery -A hunter worker -l INFO
其中,-l 表示日志等级,相当于是 --loglevel=INFO
celery -A hunter worker --loglevel=INFO
指定worker的hostname
celery -A hunter worker -l INFO -n worker1@%h
其中,%h 表示主机名,包含域名在内,%n 表示仅包含主机名,%d 表示仅包含域名。
以下是示例:
| 变量 | 示例 | 结果 |
|---|---|---|
| %h | worker1@%h | worker1@george.example.com |
| %n | worker1@%n | worker1@george |
| %d | worker1@%d | worker1@example.com |
指定日志文件地址
logfile 参数可以指定日志文件地址:
celery -A hunter worker --loglevel=INFO --logfile=/Users/hunter/python/celery_log/celery.log
杀死 worker 进程
我们可以通过获取 worker 的进程 id 来杀死这些进程:
ps aux | grep 'celery -A hunter' | awk '{print $2}' |xargs sudo kill -9
并发处理
一般来说,当我们直接启动 worker 的时候,会默认同时起好几个 worker 进程。
如果不指定 worker 的数量,worker 的进程会默认是所在机器的 CPU 的数量。
我们也可以通过 concurrency 参数来指定启动 worker 的进程数。
比如说,我们想启动三个 worker 的进程,可以如下指定:
celery -A hunter worker --concurrency=3 -l INFO
--concurrency 也可以简写成 -c:
celery -A hunter worker -c 3 -l INFO
这样,我们在启动的命令行里输入下面的参数就可以看到启动了三个 worker 的进程:
ps aux |grep 'celery -A hunter'
这里有一个关于 worker 进程数启动多少的问题,是不是我们的 worker 启动的越多,我们的定时任务和延时任务就会执行得越快呢?
并不是,有实验证明 worker 的数量启动得越多,对于 task 处理的性能有可能还会起到一个反向作用,这里不作展开讨论,我们可以设置 CPU 的数量即可。
当然,你也可以根据 worker 处理任务的情况,基于 application,基于工作负载,任务运行时间等试验出一个最佳的数量。
2、worker与队列
消费指定队列的task
我们可以在运行 worker 的时候指定 worker 只消费特定队列的 task,这个特定队列,可以是一个,也可以是多个,用逗号分隔开。
指定的方式如下:
celery -A hunter worker -l INFO -Q queue_1,queue_2
列出所有活跃的queues
下面的命令可以列出所有系统活跃的队列信息:
celery -A hunter inspect active_queues
假设目前我们相关配置如下:
app.conf.task_queues = (
Queue('default_queue',),
Queue('queue_1'),
Queue('queue_2'),
)
app.conf.task_routes = {
'blog.tasks.add': {
'queue': 'queue_1',
},
'blog.tasks.minus': {
'queue': 'queue_2',
},
}
我们这样启动worker:
celery -A hunter worker -l INFO -c 3 -n worker1@%h
然后运行上面的查看队列命令:
celery -A hunter inspect active_queues
可以看到如下输出:
-> worker1@localhost: OK
* {'name': 'default_queue', 'exchange': {...}, 'routing_key': 'default_queue', ...}
* {'name': 'queue_1', 'exchange': {...}, 'routing_key': 'default_queue', ...}
* {'name': 'queue_2', 'exchange': {...}, 'routing_key': 'default_queue', ...}
1 node online.
其中,输出结果最上面的 worker1@localhost 就是我们启动 worker 通过 -n 指定的 hostnam,可以通过这个来指定 worker。
我们可以指定 worker 输出对应的队列数据:
celery -A hunter inspect active_queues -d worker1@localhost
除了命令行,我们也可以在交互界面来获取这些数据:
# 获取所有的队列信息
from hunter.celery import app
app.control.inspect().active_queues()
# 获取指定 worker 的队列信息
app.control.inspect(['worker1@localhost']).active_queues()
3、worker 的检测
app.control.inspect() 函数可以检测正在运行的 worker 信息,我们可以用下面的命令来操作:
from hunter.celery import app
i = app.control.inspect()
这个操作是获取所有节点,我们也可以指定单个或者多个节点检测:
# 输入数组参数,表示获取多个节点worker信息
i = app.control.inspect(['worker1@localhost', 'worker2@localhost'])
# 输入单个worker名,指定获取worker信息
i = app.control.inspect('worker1@localhost')
获取已经注册的task列表
用到前面的 app.control.inspect() 函数和其下的 registered() 函数
i.registered()
# 输出结果为 worker 及其下的 task name
# 输出示例为 {'worker1@localhost': ['blog.tasks.add', 'blog.tasks.minus', 'polls.tasks.multi']}
输出的格式是一个 dict,worker 的名称为 key,task 列表为 value
正在执行的 task
active() 用于获取正在执行的 task 函数
i.active()
# 输出 worker 正在执行的 task
# 输出示例为 {'worker1@localhost': [{'id': 'xxx', 'name': 'blog.tasks.add', 'args': [3, 4], 'hostname': 'worker1@localhost', 'time_start': 1659450162.58197, ..., 'worker_pid': 41167}
输出的结果也是一个 dict,每个 worker 下有 n 个正在 worker 中执行的 task 信息,这个 n 的最大数量取决于前面我们启动 worker 时的 --concurrency 参数。
在其中的 task 信息里包含 task_id,task_name,和输入的参数,开始时间,worker name 等。
即将运行的 task
比如我们运行 add 延时任务,定时在 20s 之后运行:
add.apply_async((1, 1), countdown=20)
返回的结果每个 worker 下有一个任务列表,每个列表存有任务的信息:
i.scheduled()
# 输出信息如下
# {'worker1@localhost': [{'eta': '2022-08-02T22:56:49.503517+08:00', 'priority': 6, 'request': {'id': '23080c03-a906-4cc1-9ab1-f27890c58adb', 'name': 'blog.tasks.add', 'args': [1, 1], 'kwargs': {}, 'type': 'blog.tasks.add', 'hostname': 'worker1@localhost', 'time_start': None, 'acknowledged': False, 'delivery_info': {...}}]}
queue队列中等待的 task
如果我们有任务在 queue 中积压,我们可以使用:
i.reserved()
来获取队列中等待的 task 列表
4、其他 worker 命令
ping-pong
检测 worker 还活着的 worker
使用 ping() 函数,可以得到 pong 字符串的回复表明该 worker 是存活的。
from hunter.celery import app
app.control.ping(timeout=0.5)
# [{'worker1@localhost': {'ok': 'pong'}}]
我们也可以指定 worker 来操作:
app.control.ping(['worker1@localhost'])
如果你了解 redis 的存活检测操作的话,应该知道在 redis-cli 里也可以执行这个 ping-pong 的一来一回的检测操作。文章来源:https://www.toymoban.com/news/detail-497226.html
如果想获取更多后端相关文章,可扫码关注阅读: 文章来源地址https://www.toymoban.com/news/detail-497226.html
文章来源地址https://www.toymoban.com/news/detail-497226.html
到了这里,关于celery笔记六之worker介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!