一、实验介绍
1.1 实验内容
基于开源软件搭建满足企业需求的Hadoop生态系统,构建基础的大数据分析平台。
本实验采用4台机器搭建Hadoop完全分布式集群,其中1台机器作为Master节点,另外三台机器作为Slave节点,主机名分别为Slave1,Slave2和Slave3。
1.2 实验知识点
Hadoop集群部署
HDFS分布式文件系统管理
1.3 实验环境
Hadoop2.7.3
VMware Workstation 16 Pro for Windows
1.4 实验资源
| 资源名称 | 存储目录 |
|---|---|
| hadoop安装包 | /opt/software/package/ |

1.5 实验步骤清单
检查实验环境(防火墙、hosts配置、ssh互信)
可以参考搭建Hadoop集群环境
部署hadoop集群(安装hadoop、创建hdfs数据文件、修改配置文件、主从节点同步)
测试hadoop集群(启动集群、验证集群)
二、实验架构
| 序号 | IP地址 | 机器名 |
|---|---|---|
| 1 | 172.25.10.140 | master |
| 2 | 172.25.10.141 | slave1 |
| 3 | 172.25.10.142 | slave2 |
| 4 | 172.25.10.143 | slave3 |
三、实验环境准备
启动虚拟机master、slave1,slave2和slave3的快照。
输入用户名root密码root登录系统。
四、实验步骤
4.1 查看环境
#关闭防火墙命令systemctl stop firewalld
#检查防火墙是否关闭firewall-cmd --state
#检查四台虚拟机hosts文件cat /etc/hosts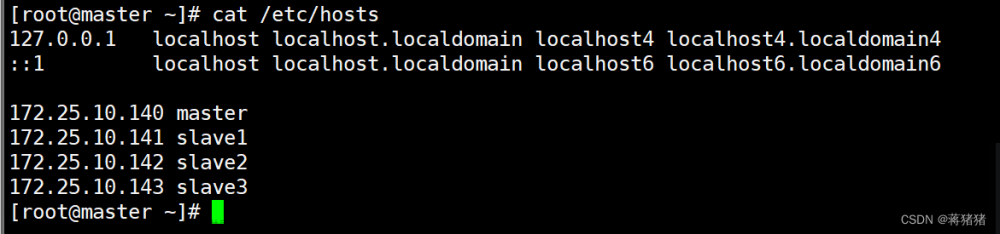
#检查ssh环境ssh slave1 datessh slave2 datessh slave3 date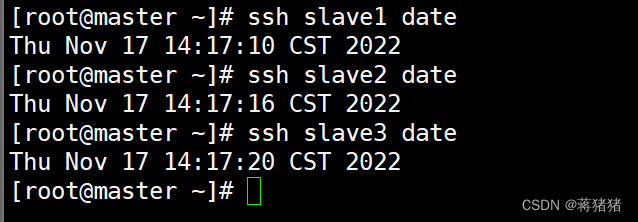
4.2部署Hadoop集群
4.2.1安装hadoop(master)
#解压安装包tar zxvf /opt/software/package/hadoop-2.7.3.tar.gz -C /usr/local/
#重命名Hadoop安装目录mv /usr/local/hadoop-2.7.3 /usr/local/hadoop
4.2.2创建hdfs数据文件存储目录(master)
#删除并创建hdfs数据文件存储目录rm -rf /home/hadoopdirmkdir /home/hadoopdir
#创建临时文件存储目录mkdir /home/hadoopdir/tmp
#创建namenode数据目录mkdir -p /home/hadoopdir/dfs/name
#创建datanode数据目录mkdir /home/hadoopdir/dfs/data
4.2.3修改配置文件(master)
1、配置环境变量
#检查环境变量
vim /etc/profile
#末尾添加
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=${HADOOP_INSTALL}/bin:${HADOOP_INSTALL}/sbin:${PATH}

#/etc/profile文件生效source /etc/profile
#hadoop-env.sh配置JAVA_HOME
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh```
export JAVA_HOME=/usr/local/jdk/jre
#验证Hadoop版本
```hadoop version```
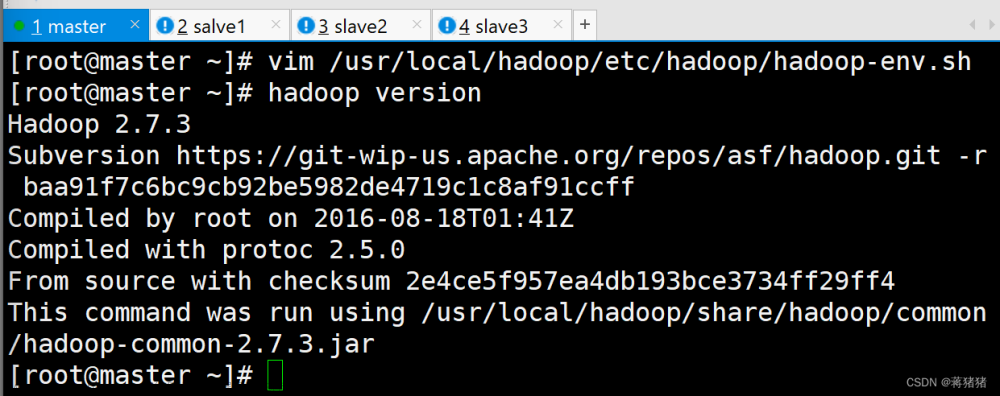 2、修改core-site.xml内容参考如下
```vim /usr/local/hadoop/etc/hadoop/core-site.xml```
2、修改core-site.xml内容参考如下
```vim /usr/local/hadoop/etc/hadoop/core-site.xml```
#修改配置文件vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
5、修改 yarn-site.xmlvi /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
6、修改 slaves文件vim /usr/local/hadoop/etc/hadoop/slaves
slave1
slave2
slave3
7、初始化HDFShadoop namenode -format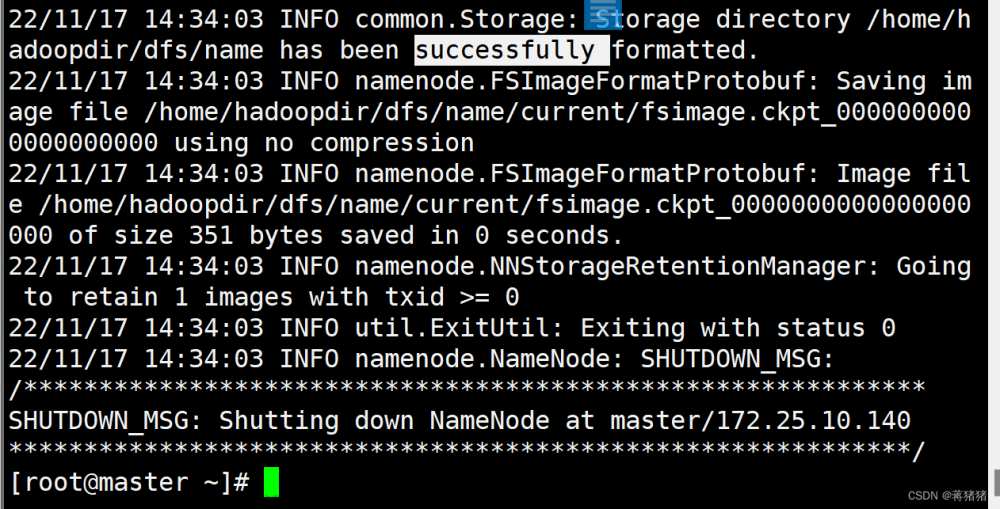
备注:最后出现“util.ExitUtil: Exiting with status 0”,表示成功。
4.2.4主从节点同步(master)
1、同步/usr/local/hadoop目录文件到slave节点scp -r /usr/local/hadoop slave1:/usr/local/scp -r /usr/local/hadoop/ slave2:/usr/local/scp -r /usr/local/hadoop/ slave3:/usr/local/
2、同步/home/hadoopdir目录文件到slave节点
#删除目录ssh slave1 rm -rf /home/hadoopdirssh slave2 rm -rf /home/hadoopdirssh slave3 rm -rf /home/hadoopdir
#同步目录scp -r /home/hadoopdir slave1:/home/scp -r /home/hadoopdir slave2:/home/scp -r /home/hadoopdir slave3:/home/
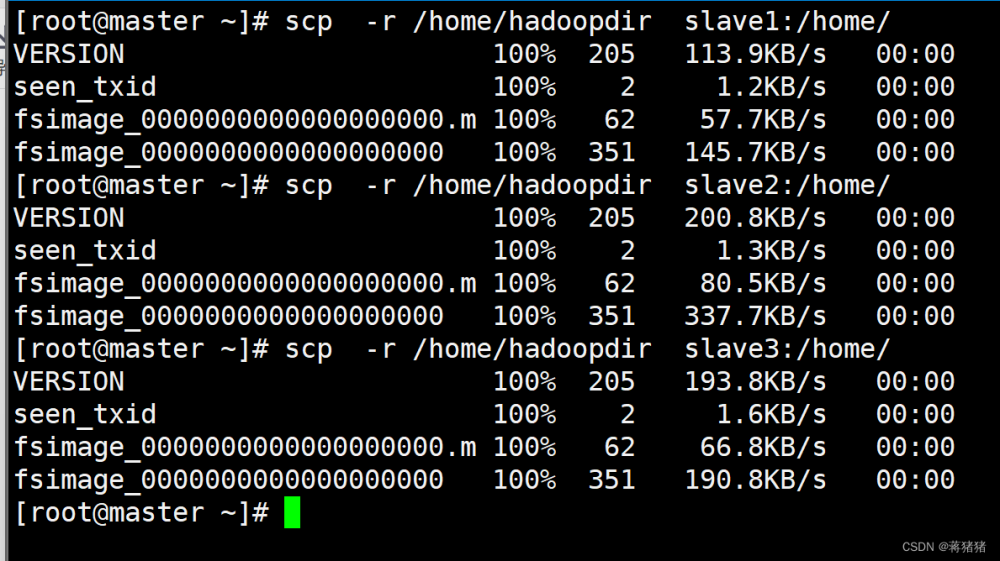
3、同步环境信息scp /etc/profile slave1:/etc/profilescp /etc/profile slave2:/etc/profilescp /etc/profile slave3:/etc/profile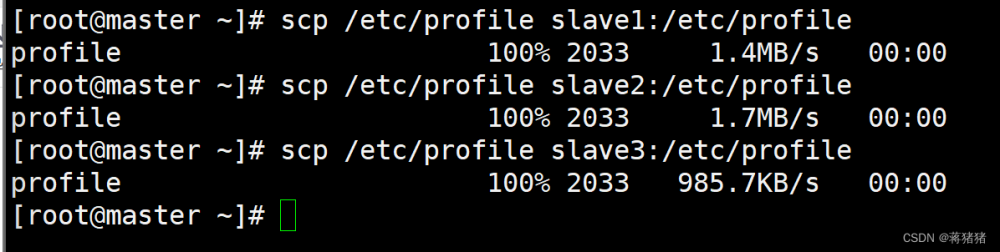
[root@slave1 ~]# source /etc/profile
``[root@slave2 ~]# source /etc/profile [root@slave3 ~]# source /etc/profile```
4.3测试Hadoop集群
4.3.1启动集群
#启动hadoop集群(master)start-all.sh 
4.3.2验证Hadoop集群
1、JPS查看Java进程
#master
#slave1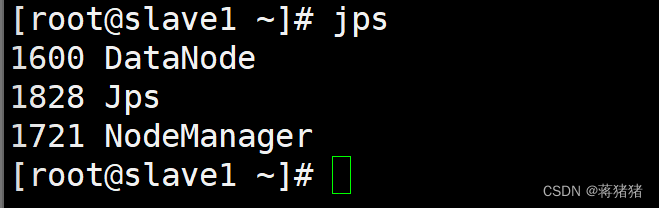
#slave2
#slave3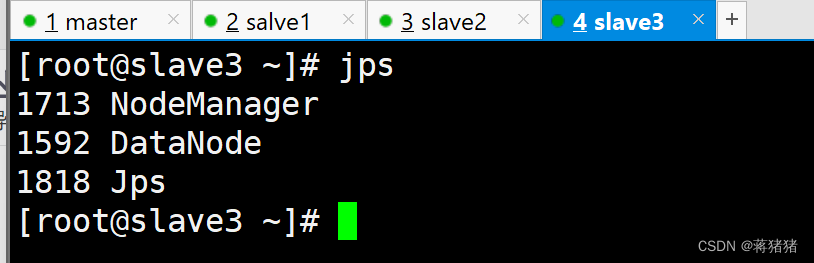
2、登录网页查看
打开浏览器,登录http://172.25.10.140:50070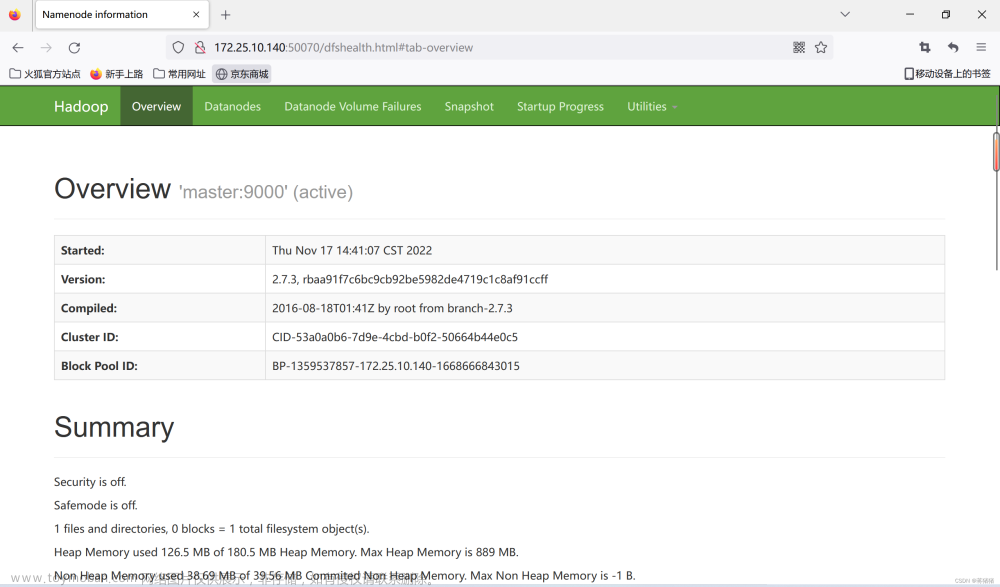
打开浏览器,查看yarn环境,登录http://172.25.10.140:8088 文章来源:https://www.toymoban.com/news/detail-497336.html
文章来源:https://www.toymoban.com/news/detail-497336.html
五、实验总结
本次实验采用完全分布式集群安装方式,需要提前部署JDK环境、SSH验证等过程。安装并启动后可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。文章来源地址https://www.toymoban.com/news/detail-497336.html
到了这里,关于接上篇文章,完成Hadoop集群部署实验的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!