评价模型-TOPSIS法(优劣解距离法)
1.1 概念
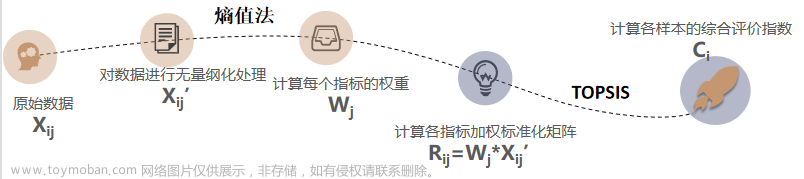
TOPSIS 法是一种常用的组内综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。基本过程为基于归一化后的原始数据矩阵,采用余弦法找出有限方案中的最优方案和最劣方案,然后分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。该方法对数据分布及样本含量没有严格限制,数据计算简单易行
1.2 适用范围
评价对象得分,且各个指标值已知。(下图案例)
评价个体与评价指标之间的关系
知识点概括

TOPSIS法建模步骤
**1. 将原始数据矩阵正向化。也就是将那些极小型指标,中间型指标,区间型指标对应的数据全部化成极大型指标,方便统一计算和处理。
- 将正向化后的矩阵标准化。也就是通过标准化消除量纲的影响。
- 计算每个方案各自与最优解和最劣解的距离
- 根据最优解与最劣解计算得分并排序**

原始矩阵正向化

极小型 to 极大型

中间型 to 极大型

区间型 to 极大型

正向化矩阵标准化

%% 对正向化后的矩阵进行标准化
%X为正向化矩阵 标准化矩阵Z
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)
计算各评价指标与最优及最劣向量之间的差距

评价对象与最优方案的接近程度

%% 计算与最大值的距离和最小值的距离,并算出得分 标准化矩阵Z
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ],2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ],2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S) %归一化得分
[sorted_S,index] = sort(stand_S ,'descend')
sort排序函数
% Matlab中给一维向量排序是使用sort函数:sort(A),排序是按升序进行的,其中A为待排序的向量;
% 若欲保留排列前的索引,则可用 [sA,index] = sort(A,'descend')
% 排序后,sA是排序好的向量,index是向量sA中对A的索引。
% sA = 8 3 2 1
% index = 4 3 1 2
Topsis与层次评价法AHP
1. Topsis法避免了数据的主观性,不需要目标函数,不用通过检验,而且能够很好的刻画多个影响指标的综合影响力度,并且对于数据分布及样本量、指标多少无严格限制,既适于小样本资料,也适于多评价单元、多指标的大系统,较为灵活、方便。但是该算法需要每个指标的数据,而对应的量化指标选取会有一定难度,同时不确定指标的选取个数为多少适宜,才能够去很好刻画指标的影响力度.
2. 层次分析法的判断矩阵是通过“专家”评分获取的,主观性强,且n不宜过大。
优劣解距离法的指标评分则是现成的,且对较大的m与n同样适用。相较于层次分析法两两比较而言,优劣解距离法不易于发生混淆。文章来源:https://www.toymoban.com/news/detail-497920.html
案例
题目:评价下表中20条河流的水质情况
注:含氧量越高越好;PH值越接近7越好;细菌总数越少越好;植物性营养物量介于10‐20之间最佳,超
过20或低于10均不好。 文章来源地址https://www.toymoban.com/news/detail-497920.html
文章来源地址https://www.toymoban.com/news/detail-497920.html
clear;clc
%% 第一步:导入数据data
load data_water_quality.mat
%% 第二步:判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);
if Judge == 1
Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、4三列需要处理,那么你需要输入[2,3,4]: '); %[2,3,4]
disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')
Type = input('例如:第2列是极小型,第3列是区间型,第4列是中间型,就输入[1,3,2]: ');
% 注意,Position和Type是两个同维度的行向量
for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数
X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));
% Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数
% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素
% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型)
% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列
% 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量
end
disp('正向化后的矩阵 X = ')
disp(X)
end
%% 第三步:对正向化后的矩阵进行标准化
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)
%% 第四步:计算与最大值的距离和最小值的距离,并算出得分
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ],2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ],2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)
[sorted_S,index] = sort(stand_S ,'descend')
%归一化结果分数 从大到小
sorted_S =
0.0819
0.0713
0.0633
0.0592
0.0585
0.0551
0.0531
0.0519
0.0505
0.0498
0.0480
0.0480
0.0469
0.0461
0.0440
0.0428
0.0373
0.0323
0.0301
0.0299
index =
16
3
1
5
15
7
14
20
13
9
4
10
18
11
8
6
12
19
2
17
到了这里,关于Matlab评价模型-TOPSIS法(优劣解距离法)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!