前言
本文介绍了网络的一些基础概念,主要包括:IP和端口号、TCP/UDP协议、网络字节流以及套接字接口。
一、IP与端口号
1.IP
每台主机都有自己的IP地址,所以当数据从一台主机传输到另一台主机,就需要IP地址。报头中会包含源IP和目的IP。
源IP地址:发送数据包的那个主机的IP地址。
目的IP地址:想要发到的那个主机的IP地址。
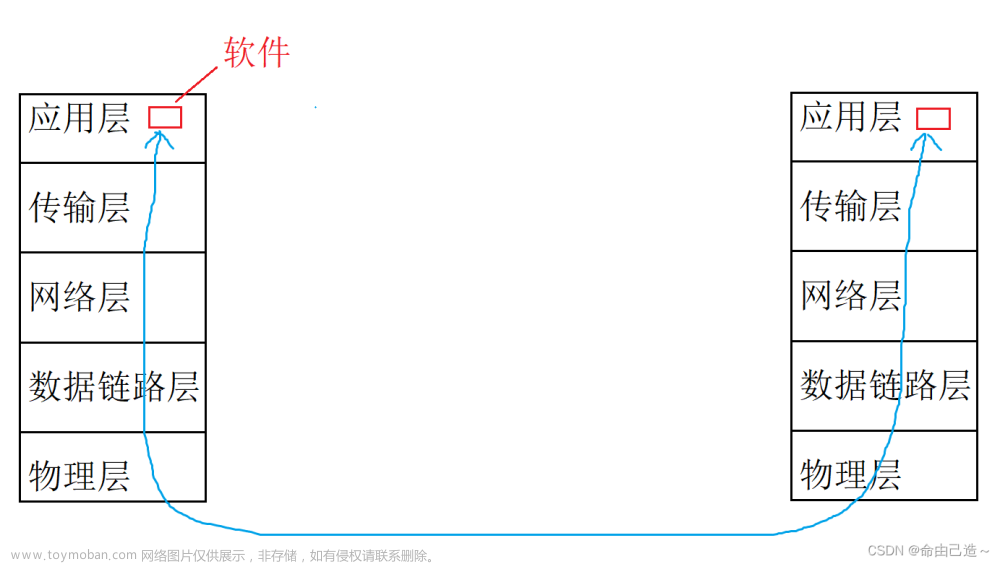
我们将数据从一台主机传递到另一台主机,并不是真正的目的。真正通信的不是这两个机器,而是这两个机器上的软件。
应用层不止一个软件。
公网IP唯一标识了主机,则数据就可以由一台主机传递到另一台主机。但是主机上有这么多软件(进程),我们怎么能保证软件A发送的数据被另一台主机上的软件B所接收呢?即如何标识主机上客户或服务进程的唯一性?
为了标识一台主机上服务进程的唯一性,我们用端口号port标识服务进程、客户进程的唯一性。
2.端口号
端口号是一个2字节16位的整数。
它是用来标识一个进程,告诉操作系统要把数据交付给哪个进程。(同一个主机中,端口号只能被一个进程占用)
因此,IP地址(唯一标识全网的某个主机) + 端口号(唯一标识服务器上的某个进程)能够标识网络上某个主机上的某个进程(全网唯一的进程)。
网络通信的本质就是进程间通信,我们之前讲过进程间通信的本质是进程们看到同一份资源,此时的同一份资源就是网络。
通信的本质就IO,因为我们上网的行为就两种:1.发送数据;2.接收数据。
3.我们之前讲过,可以用进程pid来标识一个进程,那么为什么还要有端口号port呢?
- 解耦:pid是系统规定的,而port是网络规定的,这样可以将系统和网络解耦;
- port标识服务器中的进程是唯一不变的(要让客户端进程找到服务器对应进程,就像是110、120一样不能被改变),而每次启动程序,程序的pid都会发送改变。
- 不是所有的进程都需要提供网络服务或请求(不是所有进程都需要port),但每个进程都需要pid。
一个端口号只能被一个进程占用,但是一个进程可以绑定多个端口号(1对n)。
4.底层OS如何根据port找到进程?
uint16(端口号)——task_struct——哈希。
我们在网络通信过程中,IP + port唯一标识一个进程,IP有源IP和目的IP,port也有源port和目的port。
我们在发送数据时也要将自己的IP和端口号发送过去,因为数据还要被发送回来。因此发送数据时一定会多出来一部分数据(以协议的形式呈现)。
二、TCP/UDP协议
我们用的套接字接口一定会使用传输层协议,不会绕过传输层去调用下面的协议。
传输层的协议分为:TCP协议和UDP协议
1.TCP协议特点
TCP(Transmission Control Protocol传输控制协议)
- 传输层协议
- 有连接(正式通信前要先建立连接)
- 可靠传输(在内部帮我们做可靠传输工作)
- 面向字节流
2.UDP协议特点
UDP(User Datagram Protocol用户数据报协议)
- 传输层协议
- 无连接
- 不可靠传输
- 面向数据报
注意:
理解不可靠传输:如果发送数据时出现了丢包的情况,或者数据被重复传递了(传递了多份)或者网络出现了问题等等造成的后果就叫做不可靠传输。因此,传输层就是用来解决可靠性的一个协议。
可不可靠是一个中性词。可靠是需要成本的,往往在编码和维护上都比较复杂;不可靠没有成本,使用起来也简单。
所以要分场景使用它们。
三、网络字节流
1.大端和小端数据
我们知道内存中的多字节数据相对于内存地址有大端和小端之分。
大端和小端:
小端:低权值放在低地址(小低低)
大端:低权值放在高地址(相反)
假设出现一种情况:一个大端机用大端的方式发送数据给一个小端机,如果现在是跨网络传数据,那么我们并不能清楚传输的数据是大端还是小端。
因此就有了规定,网络中的数据都是大端的。
发送数据的主机如果是大端机,就不用再做处理;如果是小端机就将数据由小端转为大端再发送数据。(接收数据同理)
如何定义网络数据流的地址
发送主机,把发送缓冲区内的数据按内存地址由低到高的顺序发送(即,先发出的数据在低地址,后发出的数据在高地址。);
接收主机,把网络上接收到的数据按字节一次保存在接收缓冲区内,也是按内存地址从低到高的顺序保存。
四、socket套接字接口
1.socket常见API
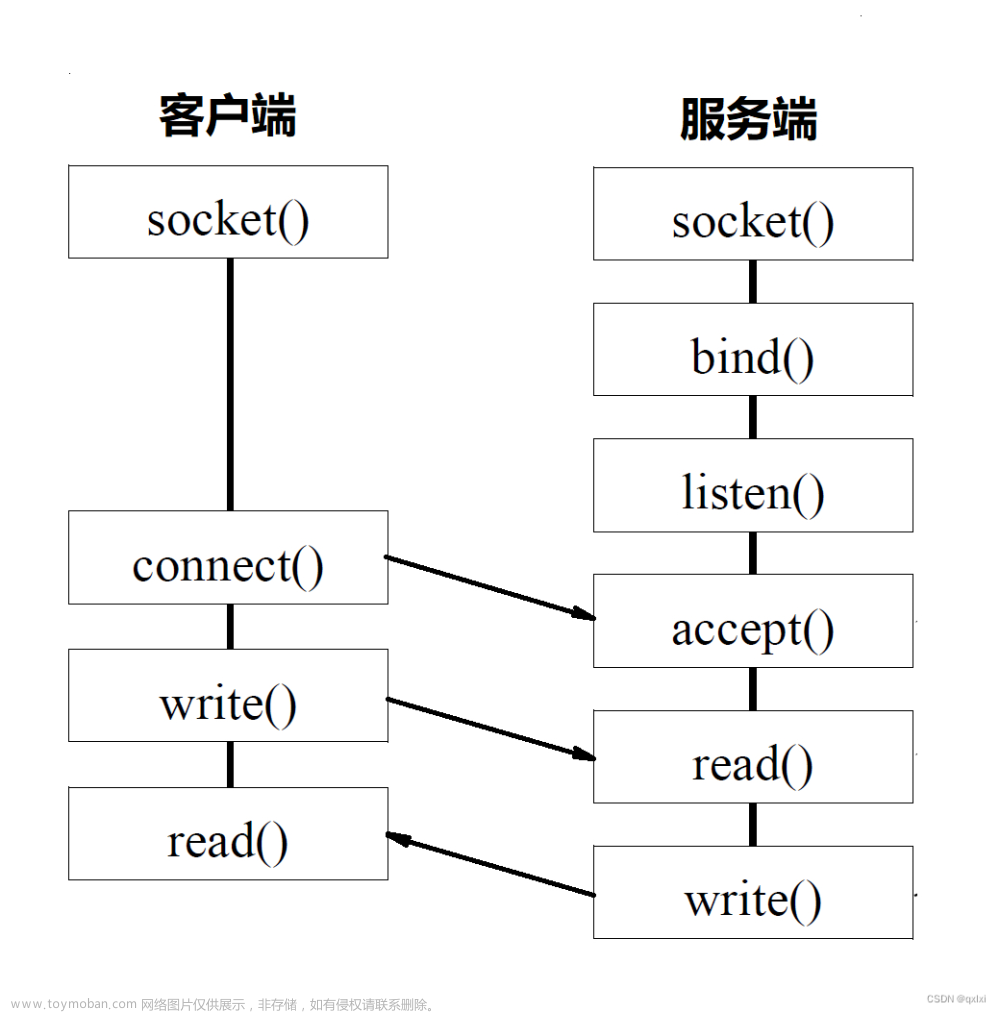
//穿个件socket文件描述符(TCP/UDP,客户端 + 服务器)
int socket(int domain, int type, int protocol);
//绑定端口号(TCP/UDP,服务器)
int bind(int socket, const struct sockaddr*address, socklen_t address_len);
//开始监听socket(TCP, 服务器)
int listen(int socket, int backlog);
//接收请求(TCP, 服务器)
int accept(int socket, struct sockaddr* address, socklen_t* address_len);
//建立联系(TCP, 客户端)
int connect(int sockfd, const struct sockaddr* addr, socklen_t addrlen);
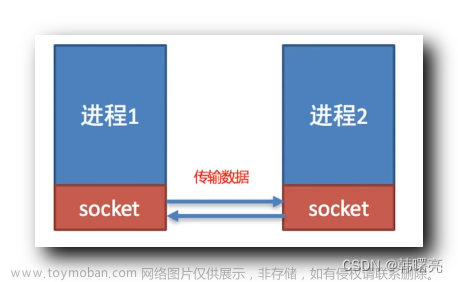
IP地址 + 端口号能够标识该主机上的唯一一个进程:IP和端口号port就称为套接字。
socket是插座的意思,未来进行网络通信时,插头和插座配套使用。
2. 套接字
套接字种类
套接字种类比较多,常见的有以下三种:
1.网络套接字;
2.原始套接字;
3.unix域间套接字;
用途
1.网络套接字主要运用于跨主机之间的通信,也可以支持本地通信;
2.域间套接字只能在本地通信;
3.原始套接字可以跨传输层(TCP/IP协议)访问底层的数据。
这些套接字应用场景完全不同,所以我们想使用套接字就要使用三套不同的接口。未来方便使用,设计者只设计了一套接口,因此需要通过不同的参数,解决所有网络或者其他场景下的通信问题。
3.例子
sockaddr_in(inet, 网络通信)与sockaddr_un(unix, 域间套接字)
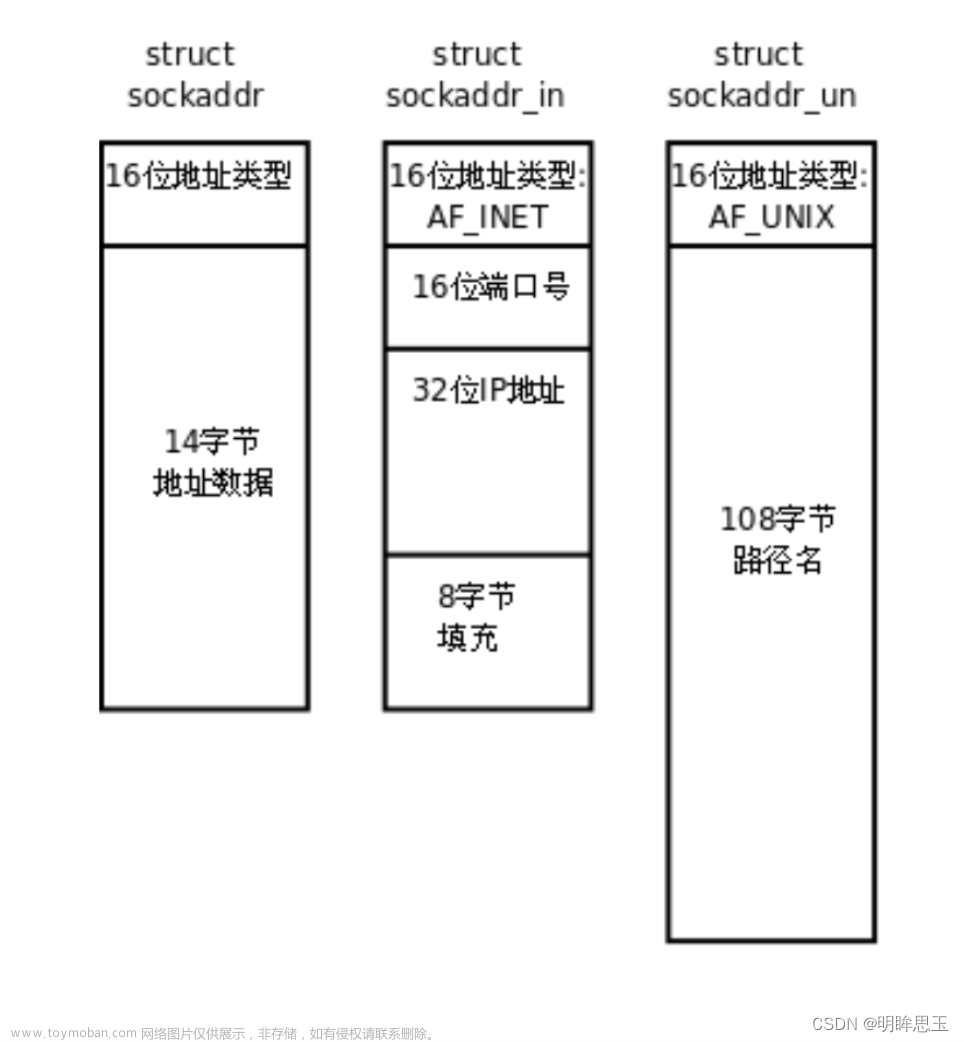
struct sockaddr_in{
short int sin_family; //地址族,一般为AF_INET
unsigned short int sin_port;//端口号,网络字节序
struct in_addr sin_addr; //IP地址
unsigned char sin_zero[8]; //用于填充,使sizeof(sockaddr_in)等于16
};
struct sockaddr_un{
sa_family_t sun_family; //AF_INET
char sun_path[108]; //带有路径的文件名
};//通过同一个文件的路径来让进程看到同一份资源
可以看到sockaddr_in和sockaddr_un是两个不同的通信场景。区分它们可以使用前2个字节:16地址类型协议家族的标识符(代表是本地通信还是网络通信)。我们两个结构体都不用,直接用sockaddr。未来进行网络编程时,如果是网络通信,填充的网络信息是struct sockaddr_in这个结构体。
比如,我们想用网络通信,虽然参数是const struct sockaddr* addr,但实际上传进去的却是sockaddr_in结构体(类型不一致,需要进行强制类型转换)。函数内部对它们一视同仁,全部当作sockaddr类型,然后根据它们的前两个字节判断是什么通信,然后再强转回去。
接口的设计为啥是structaddr结构?为什么不用void类型(C语言未来能够接收任意来下,可以将参数设置为void*;并且void不需要强转)?
因为设计这一接口时的C语言标准还没有void;
这是OS的接口,不能随意更改;
其他语言可能不支持void*。
可以将sockaddr看作基类,将sockaddr_in和sockaddr_un看做派生类,它们构成了多态体系。文章来源:https://www.toymoban.com/news/detail-498098.html
五、总结
- IP地址 + 端口号port可以标识网络上的某一台主机上的某一个进程(全网唯一)。
- TCP/UDP协议是传输层的协议,其他特点不同。例如:UDP是不可靠的。
- 套接字是一种网络通信机制,IP + 端口号是套接字的构成形式。
- 网络字节序规定为大端(我们规定网络中的数据是大端形式)。
- sockaddr使用统一的接口解决所有网络或者其他场景下的通信问题。
总结
以上就是今天要讲的内容,本文介绍了socket套接字的相关概念。本文作者目前也是正在学习网络相关的知识,如果文章中的内容有错误或者不严谨的部分,欢迎大家在评论区指出,也欢迎大家在评论区提问、交流。
最后,如果本篇文章对你有所启发的话,希望可以多多支持作者,谢谢大家!文章来源地址https://www.toymoban.com/news/detail-498098.html
到了这里,关于网络之socket套接字-基础知识的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[JAVAee]网络编程-套接字Socket](https://imgs.yssmx.com/Uploads/2024/02/636708-1.png)




