引言
上篇分析了在使用任务执行框架时需要注意的各种情况,并简单介绍了如何正确调整线程池大小。

本篇将继续介绍对线程池进行配置与调优的一些方法,详细如下:
1. 配置 ThreadPoolExecutor
ThreadPoolExecutor 为 Executors 中的 newCachedThreadPool、newFixedThreadPool 和 newScheduledThreadExecutor 等工厂方法返回的 Executor 提供了基本的实现,它是个灵活、稳定的线程池,允许开发人员进行各种定制,以满足需求。
如果默认的执行策略不能满足要求,那我们该如何定制呢?
可以通过 ThreadPoolExecutor 的构造函数来实例化一个对象,并根据实际的需要来定制,具体可以参考 Executors 的源码来了解默认配置下的执行策略,然后再以这些执行策略为基础进行修改。
如下给出 ThreadPoolExecutor 中定义的通用的构造函数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
1.1 线程的创建与销毁
线程池中,线程的创建与销毁都有哪些因素来共同负责呢?
-
线程池的基本大小(
corePoolSize)。也就是线程池的目标大小,即在没有任务执行时线程池的大小,并且只有在工作队列满了的情况下才会创建超出这个数量的线程。 -
线程池的最大大小(
maximumPoolSize)。可同时活动的线程数量的上限。 -
线程的存活时间(
keepAliveTime)。如果某个线程的空闲时间超过了存活时间,那么将被标记为可回收的,并且当线程池的当前大小超过了基本大小时,这个线程将被终止。
通过调节线程池的基本大小和存活时间,可以帮助线程池回收空闲线程占有的资源,从而使得这些资源可以用于执行其他工作。
下面我们来看看 线程池框架 Executors 中的工厂方法是如何调节的?
-
newFixedThreadPool工厂方法将线程池的基本大小和最大大小设置为参数中指定的值,而且创建的线程池不会超时。 -
newCachedThreadPool工厂方法将线程池的最大大小设置为Integer.MAX_VALUE,而将基本大小设置为 零,并将超时设置为 1 分钟,这种方法创建出来的线程池可以被无限扩展,并且当需求降低时也会自动收缩。
当然,其他形式的线程池可以通过显式的 ThreadPoolExecutor 构造函数来灵活地构造。
1.2 管理队列任务
在笔者的《Java并发编程学习10-任务执行与Executor框架》这篇博文中提到过,如果无限制地创建线程,那么不仅带来高的资源消耗,也增加了系统的不稳定性。
虽然通过采用固定大小的线程池可以解决上述问题,但在高负载情况下,应用程序仍可能耗尽资源,比如新请求的到达速率超过了线程池的处理速率。即使请求的平均到达速率很稳定,也仍然会出现请求突增的情况。我们知道,尽管队列有助于缓解任务的突增问题,但如果任务持续高速地到来,那么最后还是要抑制请求的到达率以避免耗尽内存。甚至在耗尽内存之前,响应性能也将随着任务队列的增长而变得越来越糟糕。
在 ThreadPoolExecutor 中,它提供了一个 BlockingQueue 来保存等待执行的任务。
基本的任务排队方法有 3 种:
- 无界队列
- 有界队列
- 同步移交
newFixedThreadPool 和 newSingleThreadExecutor 在默认情况下将使用一个无界的 LinkedBlockingQueue 来进行队列的管理。如果所有工作者线程都处于忙碌状态,那么任务将在队列中等候。如果任务持续快速地到达,并且超过了线程池处理它们的速度,那么队列将无限制地增加。
那有没有一种更稳妥的资源管理策略呢?
那当然是有的,那就是使用有界队列,例如 ArrayBlockingQueue、有界的 LinkedBlockingQueue、PriorityBlockingQueue。
虽然有界队列有助于避免资源耗尽的情况发生,但 当队列填满之后,新的任务该怎么办呢?
这就要不得不提到 饱和策略[Saturation Policy],详见下面的 1.3 小节
注意:在使用有界的工作队列时,队列的大小与线程池的大小必须一起调节。如果线程池较小而队列较大,那么有助于减少内存使用量,降低
CPU的使用率,同时还可以减少上下文切换,但付出的代价就是会限制系统的吞吐量。
对于非常大的或者无界的线程池,我们该如何来避免任务排队呢?
可以通过使用 SynchronousQueue,直接将任务从生产者移交给工作者线程。
SynchronousQueue 不是一个真正的队列,而是一种在线程之间进行移交的机制。要将一个元素放入 SynchronousQueue 中,必须有另一个线程正在等待接受这个元素。如果没有线程正在等待,并且线程池的当前大小小于最大值,那么 ThreadPoolExecutor 将创建一个新的线程,否则根据饱和策略,这个任务将被拒绝。
使用直接移交将更高效,因为任务会直接移交给执行它的线程,而不是被首先放在队列中,然后由工作者线程从队列中提取该任务。
只有当线程池是无界的或者可以拒绝任务时,SynchronousQueue 才有实际意义。在 newCachedThreadPool 工厂方法中就使用了它。
对于
Executor,newCachedThreadPool工厂方法是一种很好的默认选择,它能提供比固定大小的线程池更好的排队性能。这种性能的差异是由于使用了SynchronousQueue而不是LinkedBlockingQueue。当需要限制当前任务的数量以满足资源管理需求时,那么可以选择固定大小的线程池。
像 LinkedBlockingQueue 和 ArrayBlockingQueue 这样的 FIFO(先进先出)队列,任务的执行顺序与它们的到达顺序相同。如果你想控制任务的执行顺序,就可以使用 PriorityBlockingQueue,这个队列将根据优先级来安排任务。
那这里的任务优先级是通过什么来定义的呢?
-
自然顺序 :任务本身具有可以比较大小的能力,且它实现了
Comparable接口,并在 compareTo() 方法中定义任务之间的优先级关系。 -
Comparator:任务本身不具备比较大小的能力,则它可以使用自定义的
Comparator对象来定义任务之间的优先级关系
注意:只有当任务相互独立时,为线程池或者工作队列设置界限才是合理的。如果任务之间存在依赖性,那么有界的线程池或队列就可能导致线程 ”饥饿“ 死锁问题。
1.3 饱和策略
上文其实我们已经提到了,当有界队列被填满后,线程池的饱和策略将开始发挥作用。
那什么是线程池的饱和策略呢?
线程池的饱和策略是指当线程池无法处理新提交的任务时,如何拒绝这些任务并通知提交者。
Java 提供了哪些内置的饱和策略呢?
-
AbortPolicy【中止策略】: 默认的饱和策略,当线程池无法处理新提交的任务时,直接抛出 RejectedExecutionException 异常;调用者可以捕获这个异常,然后根据需求编写自己的处理代码。 -
CallerRunsPolicy【调用者运行策略】: 当线程池无法处理新提交的任务时,直接在提交任务的线程中执行该任务; -
DiscardPolicy【抛弃策略】: 当线程池无法处理新提交的任务时,直接丢弃当前任务。 -
DiscardOldestPolicy【抛弃最旧的策略】: 当线程池无法处理新提交的任务时,丢弃队列中最旧的未处理任务,并尝试重新提交当前任务;
除了上述的四种内置的饱和策略外,我们还可以通过实现 RejectedExecutionHandler 接口来自定义饱和策略,具体如下:
public class MyRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 自定义饱和策略的处理逻辑
}
}
然后在创建线程池时,可以通过其构造方法传递自定义的饱和策略,具体如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10), new MyThreadFactory(), new MyRejectedExecutionHandler());
当然创建线程池时,也是可以使用 setRejectedExecutionHandler 方法来给线程池设置新的饱和策略。
下面演示创建一个固定大小的线程池,并采用有界队列以及 “调用者运行” 饱和策略,具体如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(N_THREADS, N_THREADS, 0L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(CAPACITY));
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
当工作队列被填满后,实际上是没有预定义的饱和策略来阻塞任务的提交。不过,我们可以使用 Semaphore(信号量)来控制任务的提交速率,下面来看一下如下的实例:
@ThreadSafe
public class BoundedExecutor {
private final Executor exec;
private final Semaphore semaphore;
public BoundedExecutor(Executor exec, int bound) {
this.exec = exec;
this.semaphore = new Semaphore(bound);
}
public void submitTask(final Runnable command) throws InterruptedException {
semaphore.acquire();
try {
exec.execute(new Runnable() {
@Override
public void run() {
try {
command.run();
} finally {
semaphore.release();
}
}
});
} catch (RejectedExecutionException e) {
semaphore.release();
}
}
}
在上述的 BoundedExecutor 类中,我们使用信号量来控制正在执行的和等待执行的任务数量,其中信号量的上界需要设置为 线程池的大小 加上 可排队的任务数量。
1.4 线程工厂
每当线程池需要创建一个线程时,都是通过线程工厂方法来完成的。线程池中默认的线程工厂方法将创建一个新的、非守护的线程,并且不包含特殊的配置信息。
在 ThreadFactory 中只定义了一个方法 newThread,每当线程池需要创建一个新线程时都会调用这个方法。如下可见 ThreadFactory 接口:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
当然很多情况下,我们需要使用定制的线程工厂方法,比如:
- 为线程池的线程指定一个
UncaughtExecptionHandler; - 实例化一个定制的
Thread类用于执行调式信息的记录; - 为线程指定名字,用来解释线程的转储信息和错误日志。
那么我们可以通过指定一个线程工厂方法,来定制线程池的配置。
下面给出一个自定义的线程工厂示例:
public class MyThreadFactory implements ThreadFactory {
private final String poolName;
public MyThreadFactory(String poolName) {
this.poolName = poolName;
}
@Override
public Thread newThread(Runnable runnable) {
return new MyAppThread(runnable, poolName);
}
}
当然在 MyAppThread 中,我们还可以定制其他行为,包括:为线程指定名字,设置自定义 UncaughtExecptionHandler 向 Logger 中写入信息,维护一些同级信息(包括有多少个线程被创建和销毁),以及在线程被创建或者终止时把调试信息写入日志。
下面来看一下具体的示例:
public class MyAppThread extends Thread {
public static final String DEFAULT_NAME = "MyAppThread";
private static volatile boolean debugLifecycle = false;
private static final AtomicInteger created = new AtomicInteger();
private static final AtomicInteger alive = new AtomicInteger();
private static final Logger LOGGER = Logger.getAnonymousLogger();
public MyAppThread(Runnable runnable) {
this(runnable, DEFAULT_NAME);
}
public MyAppThread(Runnable runnable, String poolName) {
super(runnable, poolName + "-" + created.incrementAndGet());
setUncaughtExceptionHandler(new UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
LOGGER.log(Level.SEVERE, "UNCAUGHT in thread " + t.getName(), e);
}
});
}
@Override
public void run() {
// 复制 debug 标志以确保一致的值
boolean debug = debugLifecycle;
if (debug)
LOGGER.log(Level.FINE, "Created " + getName());
try {
alive.incrementAndGet();
super.run();
} finally {
alive.decrementAndGet();
if (debug)
LOGGER.log(Level.FINE, "Exiting " + getName());
}
}
public static int getThreadsCreated() {
return created.get();
}
public static int getThreadsAlive() {
return alive.get();
}
public static boolean getDebug() {
return debugLifecycle;
}
public static void setDebug(boolean b) {
debugLifecycle = b;
}
}
在 Java 应用程序中,如果需要通过安全策略来控制对某些特殊代码库的访问权限,可以使用 Java 安全管理器(SecurityManager)来实现。Java 安全管理器是一个用于保护 Java 应用程序免受恶意代码攻击的重要组件,它通过限制应用程序对系统资源和敏感信息的访问,防止可能存在的安全漏洞被利用。其中在 Executors 中的 privilegedThreadFactory 工厂方法获取的线程工厂就使用了 Java 安全管理器的机制。
如果不使用 privilegedThreadFactory,线程池创建的线程将从在需要新线程时调用 execute 或 submit 的客户程序中继承访问权限,从而导致一些安全性的问题。例如,如果客户程序的访问权限范围比较广泛,而某个特定的代码库只能被授权用户访问,那么此时在客户程序中创建的线程就可能会绕过安全策略,从而访问到受保护的代码库,导致安全漏洞。
因此,在需要进行安全控制的情况下,推荐使用 privilegedThreadFactory 工厂方法来创建线程池。通过这种方式创建出来的线程,将与创建 privilegedThreadFactory 的线程拥有相同的访问权限、AccessControlContext 和 contextClassLoader,从而确保了线程池中的所有线程都受到相应的安全策略的保护。这样,就能够更好地保障系统的安全性和稳定性。
1.5 定制 ThreadPoolExecutor
在调用完 ThreadPoolExecutor 的构造函数后,仍然可以通过设置函数来修改大多数传递给它的构造函数的参数(例如线程池的基本大小、最大大小、存活时间、线程工厂以及拒绝执行处理器)。
如果 Executor 是通过 Executors 中的某个工厂方法创建的(newSingleThreadExecutor除外),那么可以将结果的类型转换为 ThreadPoolExecutor ,然后再进行设置。
下面来看一下具体的示例:
ExecutorService exec = Executors.newCachedThreadPool();
if (exec instanceof ThreadPoolExecutor)
((ThreadPoolExecutor) exec).setCorePoolSize(10);
else
throw new AssertionError("Oops, bad assumption");
在 Executors 中包含一个 unconfigurableExecutorService 工厂方法,该方法对一个现有的 ExecutorService 进行包装,使其只暴露出 ExecutorService 的方法,因此不能对它进行配置。
另外 newSingleThreadExecutor 工厂方法,也返回按这种方式封装的 ExecutorService,而不是最初的 ThreadPoolExecutor,所以也不能对它进行配置。
知识点:我们可以在自己的
Executor中使用上面这种方式以防止执行策略被修改。如果将ExecutorService暴露给不信任的代码,有不希望对其进行修改,就可以通过unconfigurableExecutorService来包装它。
2. 扩展 ThreadPoolExecutor
ThreadPoolExecutor 是可扩展的,它提供了几个可以在子类中改写的方法:beforeExecute、afterExecute 和 terminated,这些方法可以用于扩展 ThreadPoolExecutor 的行为。
在执行任务的线程中将调用 beforeExecute 和 afterExecute 等方法,在这些方法中还可以添加日志、计时、监视或统计信息收集的功能。无论任务是从 run 中正常返回,还是抛出一个异常返回,afterExecute 都会被调用(如果任务完成后带有一个 Error,那么就不会调用 afterExecute)。如果 beforeExecute 抛出一个 RuntimeException,那么任务将不被执行,并且 afterExecute 也不会被调用。
在线程池完成关闭操作时调用 terminated,也就是在所有任务都已经完成并且所有工作者线程也已经关闭后。 terminated 可以用来释放 Executor 在其生命周期内分配的各种资源,此外还可以执行发送通知、记录日志或者收集 finalize 统计信息等操作。
下面我们来看一下如下的示例【给线程池添加统计信息】:
public class TimingThreadPool extends ThreadPoolExecutor {
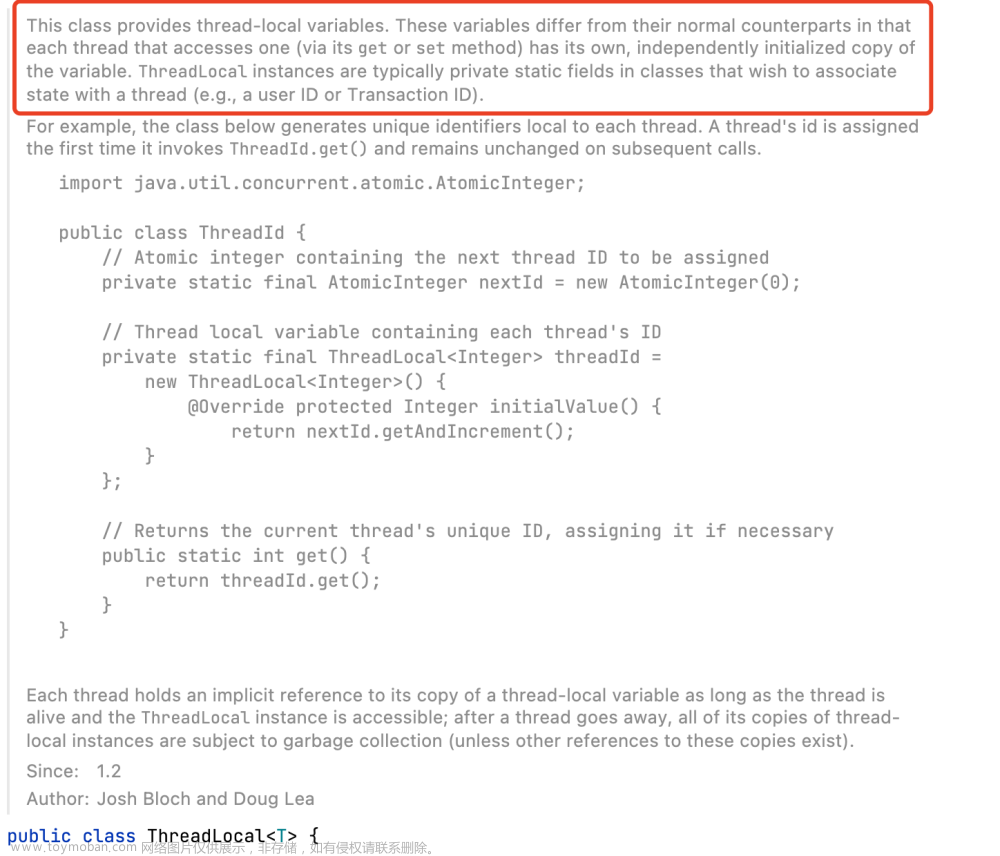
private final ThreadLocal<Long> startTime = new ThreadLocal<>();
private final Logger LOGGER = Logger.getLogger("TimingThreadPool");
private final AtomicLong numTasks = new AtomicLong();
private final AtomicLong totalTime = new AtomicLong();
public TimingThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
public TimingThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);
}
public TimingThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler);
}
public TimingThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
LOGGER.fine(String.format("Thread %s: start %s", t, r));
startTime.set(System.nanoTime());
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
try {
long endTime = System.nanoTime();
long taskTime = endTime - startTime.get();
numTasks.incrementAndGet();
totalTime.addAndGet(taskTime);
LOGGER.fine(String.format("Thread %s: end %s, time= %dns", t, r, taskTime));
} finally {
super.afterExecute(r, t);
}
}
@Override
protected void terminated() {
try {
LOGGER.info(String.format("Terminated: avg time=%dns", totalTime.get() / numTasks.get()));
} finally {
super.terminated();
}
}
}
上面的 TimingThreadPool 中给出了一个自定义的线程池,它通过 beforeExecute、afterExecute 和 terminated 等方法来添加日志记录和统计信息收集。为了测量任务的运行时间, beforeExecute 必须记录开始时间并把它保存到一个 afterExecute 可以访问的地方。因为这些方法将在执行任务的线程中调用,因此 beforeExecute 可以把值保存到一个 ThreadLocal 变量中,然后由 afterExecute 来读取。另外,在 TimingThreadPool 中使用了两个 AtomicLong 变量,分别用于记录已处理的任务数和总的处理时间,并通过 terminated 来输出包含平均任务时间的日志消息。
总结
本篇介绍了 ThreadPoolExecutor 配置和扩展相关的信息,相关示例代码请访问 GitHub:thread-pool-demo ;文章来源:https://www.toymoban.com/news/detail-498174.html
下一篇《线程池的使用》最后一篇,将介绍递归算法的并行化改造,其中会对我们《Java并发编程学习11-任务执行Demo》介绍的页面绘制程序进行一系列改进,敬请期待!!!文章来源地址https://www.toymoban.com/news/detail-498174.html
到了这里,关于Java并发编程学习16-线程池的使用(中)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!