前言
数据类型
搜索引擎是对数据的检索,所以我们先从生活中的数据说起。我们生活中的数据总体分为两种:
- 结构化数据
- 非结构化数据
结构化数据: 也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据: 又可称为全文数据,不定长或无固定格式,不适于由数据库二维表来表现,包括所有格式的办公文档、XML、HTML、Word 文档,邮件,各类报表、图片和咅频、视频信息等。
如果要更细致的区分的话,XML、HTML 可划分为半结构化数据。因为它们也具有自己特定的标签格式,所以既可以根据需要按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理
数据搜索
根据两种数据分类,搜索也相应的分为两种:
- 结构化数据搜索
- 非结构化数据搜索
对于结构化数据,因为它们具有特定的结构,所以我们一般都是可以通过关系型数据库(MySQL,Oracle 等)的二维表(Table)的方式存储和搜索,也可以建立索引。
对于非结构化数据,也即对全文数据的搜索主要有两种方法:
- 顺序扫描
- 全文检索
顺序扫描: 通过文字名称也可了解到它的大概搜索方式,即按照顺序扫描的方式查询特定的关键字。
全文搜索: 将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这种方式就构成了全文检索的基本思路。**这部分从非结构化数据中提取出的然后重新组织的信息,我们称之为索引。**这种方式的主要工作量在前期索引的创建,但是对于后期搜索却是快速高效的。
Lucene
对于这种非结构化数据的处理需要依赖全文搜索,而目前市场上开放源代码的最好全文检索引擎工具包就属于 Apache 的 Lucene了。但是 Lucene 只是一个工具包,它不是一个完整的全文检索引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
目前以 Lucene 为基础建立的开源可用全文搜索引擎主要是 Solr 和 Elasticsearch。Solr 和 Elasticsearch 都是比较成熟的全文搜索引擎,能完成的功能和性能也基本一样。但是 ES 本身就具有分布式的特性和易安装使用的特点,而 Solr 的分布式需要借助第三方来实现,例如通过使用 ZooKeeper 来达到分布式协调管理。
倒排索引
不管是 Solr 还是 Elasticsearch 底层都是依赖于 Lucene,而 Lucene 能实现全文搜索主要是因为它实现了倒排索引的查询结构。
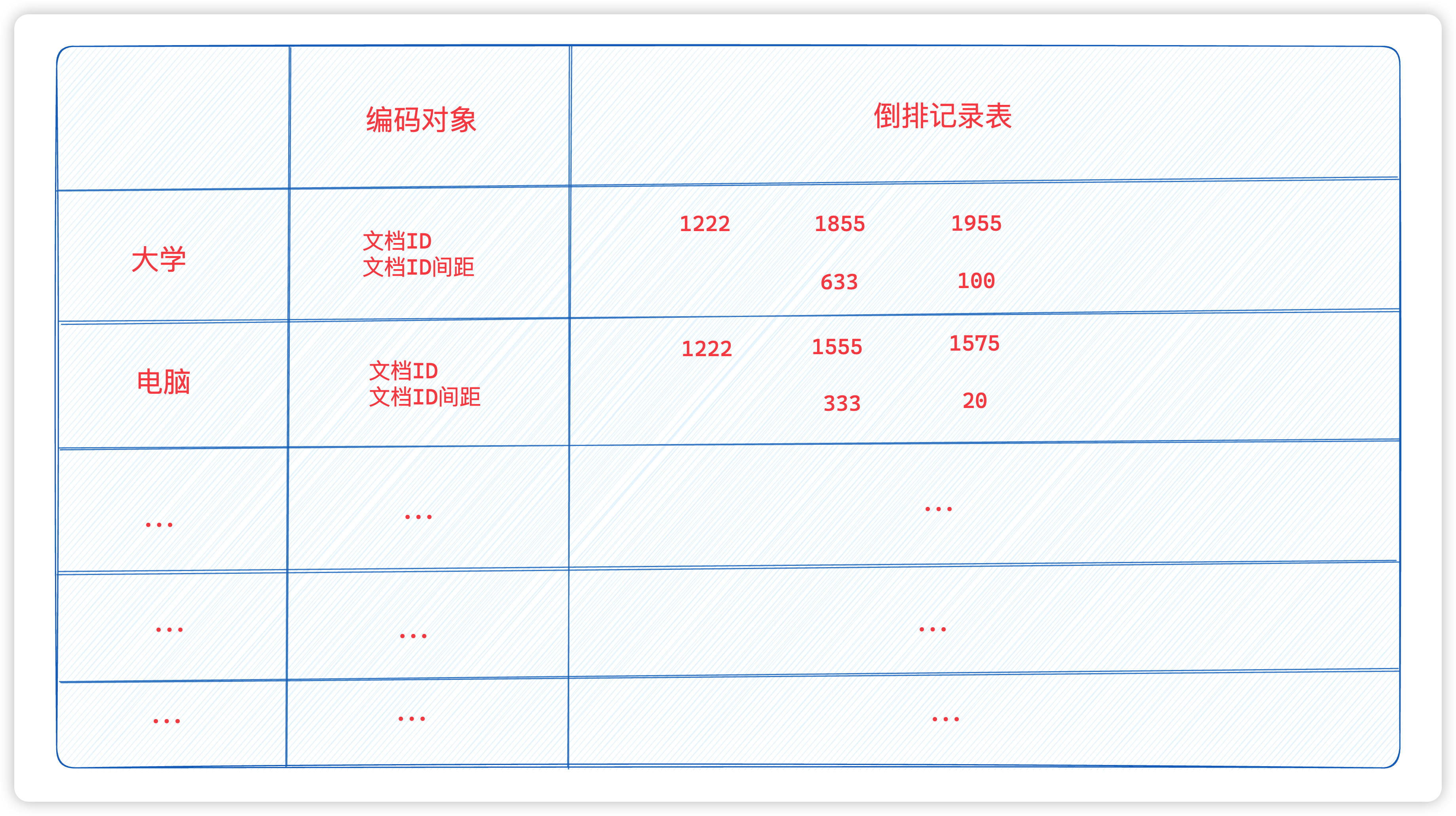
如何理解倒排索引呢? 假如现有三份数据文档,文档的内容如下分别是:
- Java is the best programming language.
- PHP is the best programming language.
- Javascript is the best programming language.
为了创建倒排索引,需要通过分词器将每个文档的内容域拆分成单独的词(我们称它为词条或 Term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
这种结构由文档中所有不重复词的列表构成,对于其中每个词都有一个文档列表与之关联。这种由属性值来确定记录的位置的结构就是倒排索引。带有倒排索引的文件我们称为倒排文件。
名词解释
- 词条(Term): 索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
- 词典(Term Dictionary): 或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
- 倒排表(Post list): 一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。每条记录称为一个倒排项(Posting),倒排表记录的不单是文档编号,还存储了词频等信息。
- 倒排文件(Inverted File): 所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
**由此可知,倒排索引主要由词典和倒排文件组成。**词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘上。
索引管理的引入
一般在增加文档时,会动态创建一个customer的index,而这个index实际上以及自动创建了它里面的字段(name)的类型。可以分析一下自动创建的mapping:
{
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
如果需要对这个建立索引的过程做更多的控制:比如想要确保这个索引有数量适中的主分片,并且在我们索引任何数据之前,分析器和映射已经被建立好。那么就会引入两点:第一个禁止自动创建索引,第二个是手动创建索引。
#禁止自动创建索引
#可以通过在 config/elasticsearch.yml 的每个节点下添加下面的配置:
action.auto_create_index: false
索引的格式
请求体里面传入设置或类型映射,如下所示:
PUT /my_index
{
"settings": { ... any settings ... },
"mappings": {
"properties": { ... any properties ... }
}
}
- settings: 用来设置分片,副本等配置信息
- mappings: 字段映射,类型等
- properties: 由于type在后续版本中会被Deprecated, 所以无需被type嵌套
索引管理操作
手工创建索引
创建一个user 索引test-index-users,其中包含三个属性:name,age, remarks; 存储在一个分片一个副本上。
PUT /test-index-users
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"remarks": {
"type": "text"
}
}
}
}
# 插入数据
POST /test-index-users/_doc
{
"name":"zhangsan",
"age":"18",
"remarks":"hello world"
}
如果输入类型不匹配,就会看到对应的不匹配的错误。
修改索引
# 修改副本数量为0
PUT /test-index-users/_settings
{
"settings": {
"number_of_replicas": 0
}
}
打开/关闭索引
关闭索引
一旦索引被关闭,那么这个索引只能显示元数据信息,不能够进行读写操作。
关闭索引命令为:POST /test-index-users/_close

打开索引
打开索引命令:POST /test-index-users/_open
打开之后就看可以写入正常。
删除索引
将创建的test-index-users删除。命令:DELETE /test-index-users
删除索引之后,再看mapping的索引的信息,就会发现之前新建索引所附加的字段信息没有了。
ES中的mapping有点类似与RDB中“表结构”的概念,在MySQL中,表结构里包含了字段名称,字段的类型还有索引信息等。在Mapping里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在ES中一个字段可以有对个类型。
1)先获取基础配置信息
GET /bank/_settings

2)获取映射mapping信息
GET /bank/_mapping

Kibana管理索引
Kibana管理索引,可以通过Management->Stack Management->Data->Index Management ->选择对应索引->点击Mappings 可查看索引结构

索引模版
前言
上面介绍了索引的一些操作,特别是手动创建索引,但是批量和脚本化必然需要提供一种模板方式快速构建和管理索引,也就是索引模板(Index Template),它是一种告诉Elasticsearch在创建索引时如何配置索引的方法。
索引模版
在创建索引之前可以先配置模板,这样在创建索引(手动创建索引或通过对文档建立索引)时,模板设置将用作创建索引的基础。
模板类型
模板有两种类型:索引模板和组件模板。
- 组件模板是可重用的构建块,用于配置映射,设置和别名;它们不会直接应用于一组索引。
- 索引模板是可以包含组件模板的集合,也可以直接指定设置,映射和别名。
索引模板中的优先级
- 可组合模板优先于旧模板。如果没有可组合模板匹配给定索引,则旧版模板可能仍匹配并被应用。
- 如果使用显式设置创建索引并且该索引也与索引模板匹配,则创建索引请求中的设置将优先于索引模板及其组件模板中指定的设置。
- 如果新数据流或索引与多个索引模板匹配,则使用优先级最高的索引模板。
内置索引模板
Elasticsearch具有内置索引模板,每个索引模板的优先级为100,适用于以下索引模式:文章来源:https://www.toymoban.com/news/detail-498436.html
logs-*-*metrics-*-*synthetics-*-*
所以在涉及内建索引模板时,要避免索引模式冲突。文章来源地址https://www.toymoban.com/news/detail-498436.html
案例
创建索引模版
PUT _component_template/component_template1
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
}
}
}
}
}
PUT _component_template/runtime_component_template
{
"template": {
"mappings": {
"runtime": {
"day_of_week": {
"type": "keyword",
"script": {
"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"
}
}
}
}
}
}
- 创建使用组件模板的索引模板
PUT _index_template/template_1
{
"index_patterns": ["bar*"],
"template": {
"settings": {
"number_of_shards": 1
},
"mappings": {
"_source": {
"enabled": true
},
"properties": {
"host_name": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z yyyy"
}
}
},
"aliases": {
"mydata": { }
}
},
"priority": 500,
"composed_of": ["component_template1", "runtime_component_template"],
"version": 3,
"_meta": {
"description": "my custom"
}
}
- 创建一个匹配
bar*的索引bar-test
PUT /bar-test
到了这里,关于ES-索引管理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!