1. Install zookeeper
1) download zookeeper from https://zookeeper.apache.org/releases.html#download
2) extract binary
$ tar xvf apache-zookeeper-3.8.1-bin.tar.gz -C ~/bigdata/3) configurate zoo.cfg
$ cd ~/bigdata/zookeeper-3.8.1/conf
$ cp zoo_sample.cfg zoo.cfg
$ vi zoo.cfg # edit zoo.cfg
$ diff -u zoo_sample.cfg zoo.cfg
--- zoo_sample.cfg 2023-01-26 00:31:05.000000000 +0800
+++ zoo.cfg 2023-06-16 18:19:01.510722864 +0800
@@ -9,7 +9,7 @@
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
-dataDir=/tmp/zookeeper
+dataDir=/home/sunxo/bigdata/zookeeper-3.8.1/tmp
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
@@ -25,7 +25,7 @@
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
-#autopurge.purgeInterval=1
+autopurge.purgeInterval=14) start zookeeper
$ cd ~/bigdata/zookeeper-3.8.1
$ mkdir tmp # as config in zoo.cfg
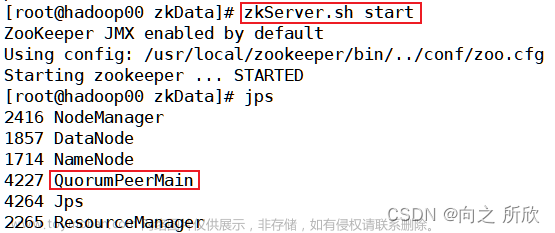
$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/bigdata/zookeeper-3.8.1/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED5) try zookeeper
$ netstat -lnpt | grep -i TCP | grep `jps | grep -w QuorumPeerMain | awk '{print $1}'`
tcp6 0 0 :::2181 :::* LISTEN 240750/java
tcp6 0 0 :::42277 :::* LISTEN 240750/java
tcp6 0 0 :::8080 :::* LISTEN 240750/java
$ bin/zkCli.sh -server 127.0.0.1:2181
[zk: 127.0.0.1:2181(CONNECTED) 0] ls /
[zookeeper]Note: use following command to stop zookeeper
$ cd ~/bigdata/zookeeper-3.8.1
$ bin/zkServer.sh stop2. Install Hadoop
1) download Hadoop from https://hadoop.apache.org/releases.html
2) extract binary
$ tar xvf hadoop-2.10.2.tar.gz -C ~/bigdata/3) configurate
$ cd $HADOOP_HOME/etc/hadoop
$ vi hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
$ diff -u hadoop-env.sh.orig hadoop-env.sh
...
# The java implementation to use.
-export JAVA_HOME=${JAVA_HOME}
+export JAVA_HOME=/opt/jdk
$ cat core-site.xml
...
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ubuntu:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/sunxo/bigdata/hadoop-2.10.2/data/tmp</value>
</property>
</configuration>
$ cat hdfs-site.xml
...
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>ubuntu:50070</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>ubuntu:50010</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>ubuntu:50075</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>ubuntu:50020</value>
</property>
</configuration>
$ cat mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>ubuntu:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>ubuntu:19888</value>
</property>
</configuration>
$ cat yarn-site.xml
...
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ubuntu</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
</configuration>
4) format the filesystem
$ cd $HADOOP_HOME
$ mkdir data/tmp # as config in core-site.xml
$ bin/hdfs namenode -format
...
23/06/16 15:39:53 INFO common.Storage: Storage directory /home/sunxo/bigdata/hadoop-2.10.2/data/tmp/dfs/name has been successfully formatted5) start hadoop / yarn
$ cd $HADOOP_HOME
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
$ sbin/mr-jobhistory-daemon.sh start historyserver6) try hadoop
#!/bin/sh
mr() {
cd $HADOOP_HOME
mkdir -p input
echo test apache hadoop hadoop sqoop hue mapreduce sqoop oozie http > input/in.txt
hdfs dfs -rm -f -r input
hdfs dfs -mkdir input
hdfs dfs -put input/in.txt input
hdfs dfs -rm -f -r output
hadoop jar $jarfile wordcount input output
hdfs dfs -cat output/*
}
jarfile=$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.2.jar
mr$ cd $HADOOP_HOME
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/sunxo # build user home on hdfs
$ ./mr.sh
...
apache 1
hadoop 2
http 1
hue 1
mapreduce 1
oozie 1
sqoop 2
test 1Note: use followings commands to stop hadoop / yarn
$ cd $HADOOP_HOME
$ sbin/mr-jobhistory-daemon.sh stop historyserver
$ sbin/stop-yarn.sh
$ sbin/stop-dfs.sh3. Install hbase
1) download HBase from https://hbase.apache.org/downloads.html
2) extract binary
$ tar xvf hbase-2.4.16-bin.tar.gz -C ~/bigdata/3) configurate
$ cd $HBASE_HOME/conf
$ vi hbase-env.sh hbase-site.xml
$ diff -u hbase-env.sh.orig hbase-env.sh
$ diff -u hbase-site.xml.orig hbase-site.xml
...
# The java implementation to use. Java 1.8+ required.
-# export JAVA_HOME=/usr/java/jdk1.8.0/
+export JAVA_HOME=/opt/jdk
...
# Tell HBase whether it should manage it's own instance of ZooKeeper or not.
-# export HBASE_MANAGES_ZK=true
+export HBASE_MANAGES_ZK=false
$ cat hbase-site.xml
...
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ubuntu:8020/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
</configuration> 4) start hbase
$ cd $HBASE_HOME
$ bin/start-hbase.sh5) try hbase
$ cd $HBASE_HOME
$ bin/hbase shell
> create_namespace 'manga'
Took 0.1748 seconds
> list_namespace
NAMESPACE
default
hbase
manga
3 row(s)
Took 0.0209 secondsNote: use followings commands to stop hbase
$ cd $HBASE_HOME
$ bin/stop-hbase.shreference:文章来源:https://www.toymoban.com/news/detail-498603.html
https://zookeeper.apache.org/doc/r3.8.1/zookeeperStarted.html
https://hadoop.apache.org/docs/r2.10.2/hadoop-project-dist/hadoop-common/SingleCluster.html#Pseudo-Distributed_Operation
https://hbase.apache.org/book.html#quickstart文章来源地址https://www.toymoban.com/news/detail-498603.html
到了这里,关于搭建HBase伪分布式集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!