算子任务分 :
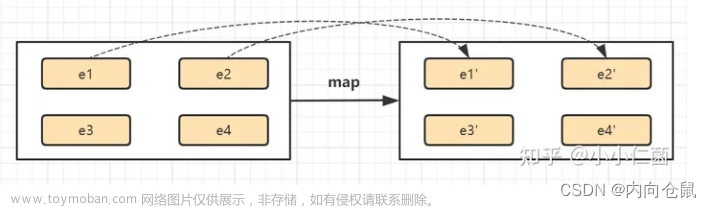
- 无状态 : 根据输入转换为输出 , 如 : map , filter , flatMap
- 有状态 : 根据输入 , 状态 转换为输出 , 如 : 聚合算子 , 窗口算子
有状态算子的处理流程 :
- 算子任务接收到上游发来的数据
- 获取当前状态
- 根据业务逻辑进行计算,更新状态
- 得到计算结果,输出发送到下游任务

状态分类
Flink 状态分 :
- 托管状态 (Managed State) : 状态的存储访问、故障恢复、重组统一由 Flink 管理,只用调接口
- 原始状态 (Raw State) : 自定义,需开辟一块内存,由自我管理,实现状态的序列化 , 故障恢复
托管状态分 :
- 算子状态 (Operator State) : 状态对同个任务共享 , 能作用到所有算子
- 按键分区状态 (Keyed State) : 状态只对同 Key 共享 , 必须 keyBY 后才能用
算子状态 :

按键分区状态 :文章来源:https://www.toymoban.com/news/detail-499074.html
 文章来源地址https://www.toymoban.com/news/detail-499074.html
文章来源地址https://www.toymoban.com/news/detail-499074.html
到了这里,关于Flink 状态概述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[flink 实时流基础]源算子和转换算子](https://imgs.yssmx.com/Uploads/2024/04/847286-1.png)



