🎇[数据结构]栈和队列的应用🎇

🍰一.栈在括号匹配中的应用
🚀1.原理
对于编译器来说,我们在大多数 I D E IDE IDE 内进行编码时,都会提示括号的匹配标志,可能用不同颜色或者距离差加以区分,那么,编译器中是如何实现这些操作的呢?

其实思路很简单,我们可以用 栈 来完成:
考虑以下括号序列:

单身数组:视左括号为男嘉宾,右括号为女嘉宾,男嘉宾会有一个愿望,如果当前女嘉宾与男嘉宾的愿望一致,则牵手成功,男嘉宾就会离开单身数组
活动内容:
愿望
①
①
①: 当计算机接收到了左括号
1
1
1,它希望有一个右括号
8
8
8与之匹配
愿望
②
②
②: 再获得左括号
2
2
2,其希望有一个右括号
7
7
7与之对应
愿望
③
③
③: 再是左括号
3
3
3,希望有一个右括号
4
4
4与之匹配
此时,单身数组内存入了左括号:
1
2
3
1\ 2\ 3
1 2 3

于是,再接收下一个括号 4 4 4,发现可以和此时数组中最后一个元素括号 3 3 3 进行匹配,于是将括号 3 , 4 3,4 3,4 完成匹配,离开了单身数组,并将愿望 ③ ③ ③移除愿望清单中

继续遍历括号,接收到左括号 5 5 5,加入数组,此时左括号 5 5 5 希望有一个右括号 6 6 6 与之匹配 (愿望 ③ ③ ③)
此时,接收下一个括号为右括号 6 6 6,发现可以和数组中最后一个元素括号 5 5 5 进行匹配,于是 5 5 5和 6 6 6完成配对,离开单身数组

之后分别为右括号 7 , 8 7,8 7,8,分别满足了愿望 ② ② ②和愿望 ① ① ①,因此,所有男女嘉宾全部配对成功(栈空)

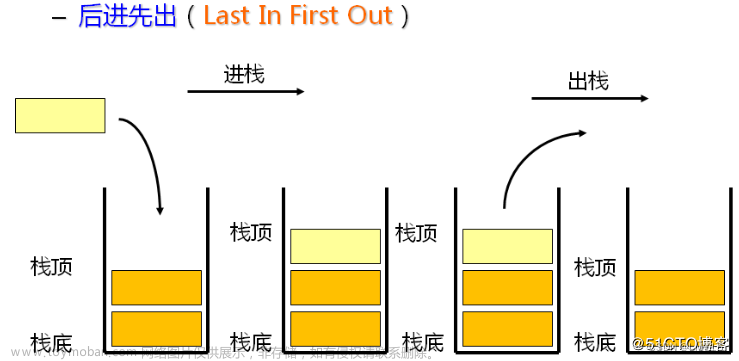
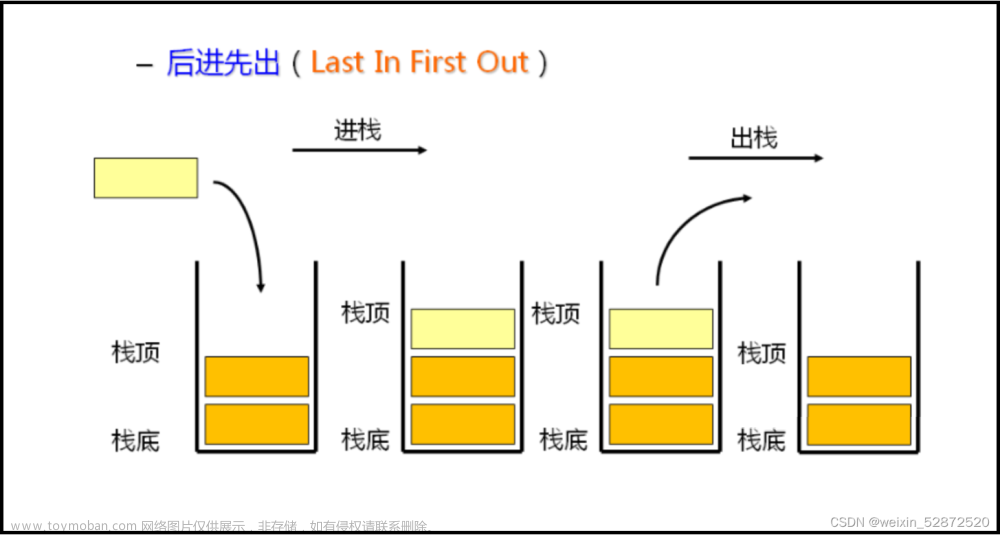
不难发现,最后一个愿望往往会最先被实现,即最后加入的左括号会最先进行匹配,满足先进后出:栈 ( L I F O ) (LIFO) (LIFO)
算法实现:
- 构造一个空栈用于存放左括号
- 不断加入左端括号,直到遇到右端括号时停止,进行匹配
- 不断重复,直到所有的左右括号全部匹配,则成功
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YPmNcxpJ-1687505993011)(2023-04-19-15-45-27.png)]
匹配不成功的情况:
1.当前扫描到的左右括号不匹配
2.右括号为单身括号
存在还没有匹配的右括号

3.左括号为单身括号
存在还有没有匹配的左括号

🚀2.代码实现
🔆1.初始化
void InitStack(SqStack& S) {
S.top = -1;//初始化栈顶指针
}
🔆2.入栈
bool Push(SqStack& S, Elemtype x) {
if (S.top == Maxsize - 1) //栈满
return false;
S.data[++S.top] = x;
return true;
}
🔆3.出栈
bool Pop(SqStack& S, Elemtype& x) {
if (S.top == -1)
return false;
x = S.data[S.top--];
return true;
}
🔆4.判断括号是否匹配
step:
- 遍历给定的括号字符型数组
- 如果为左括号,则加入栈中
- 如果为右括号,先将当前栈中的栈顶元素出栈,与之匹配
- 当所有括号遍历完,且栈为空,则匹配成功
代码实现:
bool bracketcheck(char str[], int length) {
SqStack S;
InitStack(S); //初始化一个栈
for (int i = 0; i < length; i++) {
if (str[i] == '(' || str[i] == '[' || str[i] == '{') {
Push(S, str[i]);
}
else {
if (isEmpty(S)) //遇到右括号,且当前栈为空
return false;
Elemtype topElem; //接收栈顶元素
Pop(S, topElem); //弹出栈顶元素
if (str[i] == ')' && topElem != '(')
return false;
if (str[i] == ']' && topElem != '[')
return false;
if (str[i] == '}' && topElem != '{')
return false;
}
}
return isEmpty(S); //如果全部匹配,且栈空,则成功
}
完整代码实现:
#include<iostream>
#define Maxsize 10
#define Elemtype char
using namespace std;
typedef struct {
Elemtype data[Maxsize]; //静态数组存放栈中元素
int top; //定义栈顶指针
}SqStack;
void InitStack(SqStack& S) {
S.top = -1;//初始化栈顶指针
}
bool Push(SqStack& S, Elemtype x) {
if (S.top == Maxsize - 1) //栈满
return false;
S.data[++S.top] = x;
return true;
}
bool Pop(SqStack& S, Elemtype& x) {
if (S.top == -1)
return false;
x = S.data[S.top--];
return true;
}
bool isEmpty(SqStack S) {
if (S.top == -1)
return true;
return false;
}
bool bracketcheck(char str[], int length) {
SqStack S;
InitStack(S); //初始化一个栈
for (int i = 0; i < length; i++) {
if (str[i] == '(' || str[i] == '[' || str[i] == '{') {
Push(S, str[i]);
}
else {
if (isEmpty(S)) //遇到右括号,且当前栈为空
return false;
Elemtype topElem; //接收栈顶元素
Pop(S, topElem); //弹出栈顶元素
if (str[i] == ')' && topElem != '(')
return false;
if (str[i] == ']' && topElem != '[')
return false;
if (str[i] == '}' && topElem != '{')
return false;
}
}
return isEmpty(S); //如果全部匹配,且栈空,则成功
}
int main() {
int SampleNum;
char str[Maxsize];
cout << "请输入括号的个数:" << endl;
cin >> SampleNum;
cout << "请输入待匹配的括号:" << endl;
cin >> str;
if (bracketcheck(str, SampleNum))
cout << "匹配成功" << endl;
else
cout << "匹配失败" << endl;
system("pause");
return 0;
}
输出结果:

🍰二.栈在递归中的应用
🚀1.原理
对于递归,相信大家已经不陌生了,简单来说,就是函数在中调用自身的过程,就是递归
它通常用于将大规模的复杂问题一层层地转化为小问题,即不断降低问题规模,但是一种追求代码的简洁性而牺牲运算效率的算法
实现递归所需的空间复杂度很高,当我们使用递归函数时,计算机内部会为我们开辟一个函数调用栈,递归到的每一层都会存入这个栈中,用于记录当前层变量的状态,由此,当问题规模很大时,往往需要开辟一大片连续的内存空间,所以,递归的适用条件为:
①可以把原始问题转化为属性相同的小问题; ②问题规模较小
所以,我们可以理解为,递归的本质就是栈

🚀2.栈与递归
如下,为递归的应用场景:


由此总结出,递归的缺陷为:
① ① ①空间要求过大,容易溢出; ② ② ②在递归过程中会有许多重复的计算,导致时间开销过大
可以看到,对于这两道典型的递归函数例题,其实都需要栈,我们在平时写的递归中不容易发现,是因为计算机在内部为我们实现了栈的功能
所以,我们尝试主动模拟该过程,即通过构建栈来实现
e . g e.g e.g 以斐波那契数列为例:
其定义为:

1.递归实现:
//斐波那契数列的递归实现
int fib(int n) {
if (n == 0)
return 0;
else if (n == 1)
return 1;
else
return fib(n - 1) + fib(n - 2);
}
2.栈实现:
🔱思路分析:
其实要用栈实现,我们只需要模拟其入栈和出栈的过程
🎯 因为数列中的每一项都是由前面两个项所得来的,所以我们可以构造斐波那契数列的二叉树
最后加到结果上的其实都是叶子结点,这里我们定义叶子结点为 n = 1 或 n = 2 n=1 或 n=2 n=1或n=2 时,因为: f i b ( 1 ) = f i b ( 2 ) = 1 fib(1)=fib(2)=1 fib(1)=fib(2)=1

step:
- 构造一个空栈,并将根结点传入
- 每一轮都弹出栈顶元素,判断是否为叶子结点 ( n = 1 ∣ ∣ n = 2 ) (n=1 || n=2) (n=1∣∣n=2)
- ① ① ① 若弹出的为叶子结点,则结果 r e s + = 1 res+=1 res+=1 (因为叶子节点的值只有 1 1 1);
② ② ② 若弹出的不是叶子结点,则将该结点的两个子结点压入栈中;- 重复 ②,③ ②,③ ②,③操作,直到栈为空,返回结果
递归栈:

✅ 功能函数实现:
//斐波那契数列的栈实现
int fib_Stack(int n) { //求解fib(n)的值
Stack S;
InitStack(S);
int res = 0;
Push(S, n);
while (!Stackempty(S)) //当栈不为空
{
int x = Pop(S);
if (x == 1 || x == 2) { //叶子结点
res += 1; //因为fib(1)=fib(2)=1
}
else //此时还不能加,则将两个子节点压入栈
{
Push(S, x - 1);
Push(S, x - 2);
}
}
return res;
}
完整代码实现:
#include<iostream>
#define Maxsize 50
using namespace std;
typedef struct {
int data[Maxsize];
int top;
}Stack;
//初始化
void InitStack(Stack& S) {
S.top = -1;
}
//判空
bool Stackempty(Stack& S) {
if (S.top == -1)
return true;
return false;
}
//判满
bool Stackover(Stack& S) {
if (S.top >= Maxsize)
return true;
return false;
}
//出栈
int Pop(Stack& S) {
if (Stackempty(S)) //为空
{
cout<<"栈空" << endl;
return '\0';
}
return S.data[S.top--];
}
//入栈
bool Push(Stack& S, int x) {
if (Stackover(S))
return false;
S.data[++S.top] = x;
return true;
}
//斐波那契数列的递归实现
int fib(int n) {
if (n == 0)
return 0;
else if (n == 1)
return 1;
else
return fib(n - 1) + fib(n - 2);
}
//斐波那契数列的栈实现
int fib_Stack(int n) { //求解fib(n)的值
Stack S;
InitStack(S);
int res = 0;
Push(S, n);
while (!Stackempty(S)) //当栈不为空
{
int x = Pop(S);
if (x == 1 || x == 2) { //叶子结点
res += 1; //因为fib(1)=fib(2)=1
}
else //此时还不能加,则将两个子节点压入栈
{
Push(S, x - 1);
Push(S, x - 2);
}
}
return res;
}
int main() {
int n;
cout << "请输入要求解的fib数列的项数(>=1):" << endl;
cin >> n;
cout << "递归求解结果为:" << fib(n) << endl;
cout << "栈求解结果为:" << fib_Stack(n) << endl;
system("pause");
return 0;
}
输出结果:
🍰三.栈在表达式中的应用
🚀1.中缀转后缀表达式
🔆1.原理
表达式求值是程序设计语言中一个最基本的问题,对于现实生活中一般的计算式,我们可以快速得出结果,但计算机处理却十分麻烦,因为存在计算符号之间的优先级,因此,我们需要一种特殊的方法,可以不用括号,也能得到结果,我们基于栈来实现
那这和栈有什么关系呢?让我们继续探究
1.中缀表达式 :运算符在两个操作数中间
这是我们最熟悉最常用的表达式:

不难发现,对于中缀表达式而言,加括号与不加括号的结果是不一样的,计算机在处理这些括号的时候很糟心,因为它还需要找到与之相匹配的括号,再检查内部是否还有括号,当数据量足够大时,程序难以进行
那么,我们就需要一个既不用括号,又可以完整地表示出正确含义的表达式

改进:
1.后缀表达式:运算符在两个操作数后面
2.前缀表达式:运算符在两个操作数前面
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BdgFFwJV-1687505993015)(2023-04-21-10-19-13.png)]
🔆2.实现
运算规则:
- 确定中缀表达式中各个运算符的运算顺序
- 选择下一个运算符,按照 [ [ [左操作数 右操作数 运算符 ] ] ] 的方式进行组合,成为一个新的表达式
- 重复 ② ② ②,直到运算符全部被处理
step:
我们可以看到,当确定完优先级之后,我们从优先级最高的开始计算:
- 找到 ①,此时左右操作数为
1
1
1 和
1
1
1,因此,我们按照构造规则改为
11
+
11+
11+ ,视为一个整体:
( ( 15 / ( 7 − ( 11 + ) ) ∗ 3 ) − ( 2 + ( 1 + 1 ) ) ((15 / (7-(11+))*3)-(2+(1+1)) ((15/(7−(11+))∗3)−(2+(1+1)) - 再找到 ②,此时左右操作数为
7
7
7 和
11
+
11+
11+,因此,我们改为
7
(
11
+
)
−
7(11+)-
7(11+)−
( ( 15 / 7 ( 11 + ) − ) ∗ 3 ) − ( 2 + ( 1 + 1 ) ) ((15/7(11+)-)*3)-(2+(1+1)) ((15/7(11+)−)∗3)−(2+(1+1)) - 再找到 ③,此时左右操作数变为了
15
15
15 和
711
+
−
711+-
711+−,同样地,我们得到:
( ( 15 ( 711 + − ) / ) ∗ 3 ) − ( 2 + ( 1 + 1 ) ) ((15(711+-)/)*3)-(2+(1+1)) ((15(711+−)/)∗3)−(2+(1+1))
… - 以此类推,我们就可以得到上述的最终表达式
后缀表达式的关键:不断合体为一个操作数
注意:
但是其实,后缀表达式并不唯一,这里有两个括号,如果我们先计算第二个括号内的数,再计算第一个括号内的数,最后加起来,其实结果是一样的
由此,我们需要有条件去约束它:
后缀表达式中的左优先原则:
只要左边的运算符能先计算,就优先计算左边的,这样就确保了表达式的唯一性

也就是中缀表达式中运算符的优先符的计算顺序与后缀表达式中运算符从左往右的出现顺序相同

前缀表达式中的右优先原则:
对于前缀表达式,是从右往左来反映运算符的优先级的,其余和后缀表达式类似,就不再赘述了
我们通过上述方法,已经解决了手算问题,那么我们现在思考,这一过程在计算机上该如何实行呢?
准备:
转为后缀表达式时,需要根据操作符 o p op op 的优先级来进行栈的动态变化,我们用 i c p icp icp[栈内优先数]来表示当前扫描到运算符未进栈时的优先级,该 运算符进栈后的优先级为 i s p isp isp[栈外优先数]
| 操作符 | ( | *,/ | +,- | ) |
|---|---|---|---|---|
| i s p isp isp | 1 | 5 | 3 | 6 |
| i c p icp icp | 6 | 4 | 2 | 1 |
🎯 运算规则:(基于只有加减乘除)
-
初始化一个栈,用于保存 运算符
-
从左向右处理中缀表达式中的各个元素,直到末尾
-
在处理各个元素时,会遇到以下情况:
a. 遇到 操作数,直接加入后缀表达式字符串 b e h i n d behind behind;b. 遇到 界限符→括号:
遇到左括号 ′ ( ′ '(' ′(′,直接入栈;
遇到右括号 ′ ) ′ ')' ′)′,不断将操作符弹出,加入后缀表达式,直到遇到 ‘(’,结束;注意:弹出的括号不加入表达式
c. 遇到 运算符:
依次弹出栈内优先级高于或等于当前运算符的所有运算符,加入后缀表达式,若遇到 ′ ( ′ '(' ′(′ 或栈空则停止,最后将当前运算符加入栈中; -
在处理完所有元素后,依次弹出栈内剩余元素,加入后缀表达式 b e h i n d behind behind
🍰 e . g e.g e.g 对于表达式: ( A − B ) ∗ C − D (A-B)*C-D (A−B)∗C−D
① 遍历中缀表达式,第一个是运算符
(
(
(,直接压入栈中,第二个是操作符
A
A
A,直接加入后缀表达式,第三个是运算符
−
-
−,因为
i
c
p
(
−
)
>
i
s
p
(
(
)
icp(-)>isp(()
icp(−)>isp((),也就是优先级比
(
(
( 高,所以直接压入栈中,再在后缀表达式中加入操作符
B
B
B,此时,
b
e
h
i
n
d
=
A
B
behind=AB
behind=AB:
② 下一个是运算符
)
)
),于是,不断弹出栈中元素,直到遇到
(
(
(,将除了括号外的其他运算符依次加到表达式后面,此时,
b
e
h
i
n
d
=
A
B
−
behind=AB-
behind=AB−:
③ 之后,将运算符 ∗ * ∗ 入栈, b e h i n d behind behind 后加入 C C C,当遇到 − - − 时,由于减号的优先级小于乘号,所以,弹出 ∗ * ∗,并将 − - − 入栈,此时, b e h i n d = A B − C ∗ behind=AB-C* behind=AB−C∗:

④ 最后,加入中缀表达式中的最后一个运算符 D D D,再将栈内元素全部弹出,加入到 b e h i n d behind behind,最终表达式为 : b e h i n d = A B − C ∗ D − behind=AB-C*D- behind=AB−C∗D−
✅ 功能函数实现:
//功能函数
string change(string middle) {
Stack S;
InitStack(S);
string behind = "";
char op;//运算符
//遍历中序表达式中的所有元素
for (int i = 0; i < middle.length(); i++)
{
char x = middle[i];
//1.数字或其他
if (!isOp(x))
behind += middle[i];
//2.左括号
else if (x == '(') //左括号进入时优先级最高,直接压入栈
Push(S, x);
//3.右括号
else if (x == ')') //右括号进入时优先级低,一直出栈直到遇到左括号
{
while (!Stackempty(S)) {
op = Pop(S);
if (op == '(') //如果为右括号则停下
break;
else
behind += op; //否则一直弹出运算符
}
}
//4.运算符
else
{
//4.1运算符为乘除
if (x == '*' || x == '/')
{
while (!Stackempty(S)) {
op = Pop(S); //将运算符弹出栈
if (op == '(')
break;
else
{
if (op == '+' || op == '-') //如果为加或减(优先级小)则重新将他们压回去
{
Push(S, op);
break; //不要忘了break,不然就死循环了,一直出栈入栈...
}
else //遇到乘或除
behind += op; //加入该弹出运算符
}
}
}
//4.2运算符为加减
else if (x == '+' || x == '-')
{
while (!Stackempty(S)) {
op = Pop(S);
if (op == '(')
break;
else
{
behind += op;
//因为加减不管遇到加减还是乘除,都不能满足优先级大,所以都要弹出并加入后缀表达式
}
}
}
Push(S, x); //这是包含在情况4中的 表示将当前运算符压入栈
}
}
//当中序表达式中元素全部被便遍历完了之后,弹出栈中所有元素
while (!Stackempty(S))
behind += Pop(S);
return behind;
}
int main() {
string middle;
cin >> middle;
cout << change(middle) << endl;
system("pause");
return 0;
}
完整代码实现:
#include<iostream>
#define Maxsize 50
using namespace std;
typedef struct {
char data[Maxsize]; //栈是存运算符的,所以为字符型
int top; //栈顶
}Stack;
//初始化
void InitStack(Stack& S) {
S.top = -1;
}
//栈满
bool Stackover(Stack& S) {
if (S.top >= Maxsize)
return true;
else
return false;
}
//栈空
bool Stackempty(Stack& S) {
if (S.top == -1)
return true;
else
return false;
}
//入栈
void Push(Stack& S, char x) { //将x压入栈中
if (!Stackover(S)) //如果栈不满
S.data[++S.top] = x;
else
cout << "加入" << x << "时栈满" << endl;
}
//出栈
char Pop(Stack& S) {
if (!Stackempty(S))
return S.data[S.top --];
else {
cout << "弹出失败,栈空" << endl;
return '\0';
}
}
//判断是否为运算符
bool isOp(char x) {
if (x == '(' || x == ')' || x == '+' || x == '-' || x == '*' || x == '/')
return true;
else
return false;
}
//功能函数
string change(string middle) {
Stack S;
InitStack(S);
string behind = "";
char op;//运算符
//遍历中序表达式中的所有元素
for (int i = 0; i < middle.length(); i++)
{
char x = middle[i];
//1.数字或其他
if (!isOp(x))
behind += middle[i];
//2.左括号
else if (x == '(') //左括号进入时优先级最高,直接压入栈
Push(S, x);
//3.右括号
else if (x == ')') //右括号进入时优先级低,一直出栈直到遇到左括号
{
while (!Stackempty(S)) {
op = Pop(S);
if (op == '(') //如果为右括号则停下
break;
else
behind += op; //否则一直弹出运算符
}
}
//4.运算符
else
{
//4.1运算符为乘除
if (x == '*' || x == '/')
{
while (!Stackempty(S)) {
op = Pop(S); //将运算符弹出栈
if (op == '(')
break;
else
{
if (op == '+' || op == '-') //如果为加或减(优先级小)则重新将他们压回去
{
Push(S, op);
break; //不要忘了break,不然就死循环了,一直出栈入栈...
}
else //遇到乘或除
behind += op; //加入该弹出运算符
}
}
}
//4.2运算符为加减
else if (x == '+' || x == '-')
{
while (!Stackempty(S)) {
op = Pop(S);
if (op == '(')
break;
else
{
behind += op;
//因为加减不管遇到加减还是乘除,都不能满足优先级大,所以都要弹出并加入后缀表达式
}
}
}
Push(S, x); //这是包含在情况4中的 表示将当前运算符压入栈
}
}
//当中序表达式中元素全部被便遍历完了之后,弹出栈中所有元素
while (!Stackempty(S))
behind += Pop(S);
return behind;
}
int main() {
string middle;
cin >> middle;
cout << change(middle) << endl;
system("pause");
return 0;
}
输出结果:

🚀2.后缀表达式的计算
将中缀表达式转为后缀表达式后,还需要计算后缀表达式,才能得到最终结果
计算法则:
从左向右扫描,每遇到一个运算符,就让运算符之前最近的两个数运算,运算之后,立即返回结果,合体为一个操作数


由此,我们可以得到结论:
对于表达式的转换和计算:
✅ 相同点:都要构造一个栈实现
✅ 不同点:
- 对于表达式的转换而言,我们是构造一个存放运算符的栈,而操作数不会进入栈
- 而对于计算而言,我们需要构造一个存储操作符运算结果的栈,也就是本质是存放操作数,而运算符只是用于栈内元素的计算,不会存入栈
所以,转换 → 运算符栈,计算 → 操作符栈 所以,转换→运算符栈 ,计算→操作符栈 所以,转换→运算符栈,计算→操作符栈
🔱思路分析:
step:
- 从左往右扫描下一个元素,直到处理完所有元素
- 若扫描到 操作符,则压入栈,并回到 ①;
-
若扫描到 运算符,则弹出两个栈顶元素,执行运算,运算结果压回到栈顶;
结果 = [ =[ =[后出栈元素 运算符 先出栈元素 ] ] ]注意:这里先出栈的是右操作符
- 重复执行,直到表达式内元素全部被遍历完
e . g e.g e.g 我们来看如下的表达式
在得到了后缀表达式之后:

计算图解如下:
r e s : res: res:

功能函数代码:
//计算后缀表达式
void Caculate(string behind[],int len)
{
Stack S; //创建栈,用于保存操作数
InitStack(S);
for (int i = 0; i < len; i++)
{
//如果是运算数将其压入栈
if (!isOp(behind[i]))
{
Push(S, atoi(behind[i].c_str()));
}
//如果是操作符依次弹出两个操作数
else
{
double num1 = Pop(S); //右操作数
double num2 = Pop(S); //左操作数
//执行相应运算,将运算结果压入栈中
if (behind[i] == "+")
{
Push(S, num1 + num2);
}
else if (behind[i] == "-")
{
Push(S, num2 - num1);
}
else if (behind[i] == "*")
{
Push(S, num1 * num2);
}
else if (behind[i] == "/")
{
Push(S, num2 / num1);
}
}
}
//最终栈顶元素即为结果
cout <<"结果为:" << Pop(S) << endl;
}
完整代码实现:
#include<iostream>
#include<string>
#define Maxsize 50
using namespace std;
typedef struct {
double data[Maxsize];
int top; //栈顶
}Stack;
//初始化
void InitStack(Stack& S) {
S.top = -1;
}
//栈满
bool Stackover(Stack& S) {
if (S.top >= Maxsize)
return true;
else
return false;
}
//栈空
bool Stackempty(Stack& S) {
if (S.top == -1)
return true;
else
return false;
}
//入栈
void Push(Stack& S, double x) { //将x压入栈中
if (!Stackover(S)) //如果栈不满
S.data[++S.top] = x;
else
cout << "加入" << x << "时栈满" << endl;
}
//出栈
double Pop(Stack& S) {
if (!Stackempty(S))
return S.data[S.top--];
else {
cout << "弹出失败,栈空" << endl;
return '\0';
}
}
bool isOp(string x) {
if (x == "+" || x == "-" || x == "*" || x == "/")
return true;
else
return false;
}
//计算后缀表达式
void Caculate(string behind[],int len)
{
Stack S; //创建栈,用于保存操作数
InitStack(S);
for (int i = 0; i < len; i++)
{
//如果是运算数将其压入栈
if (!isOp(behind[i]))
{
Push(S, atoi(behind[i].c_str()));
}
//如果是操作符依次弹出两个操作数
else
{
double num1 = Pop(S); //右操作数
double num2 = Pop(S); //左操作数
//执行相应运算,将运算结果压入栈中
if (behind[i] == "+")
{
Push(S, num1 + num2);
}
else if (behind[i] == "-")
{
Push(S, num2 - num1);
}
else if (behind[i] == "*")
{
Push(S, num1 * num2);
}
else if (behind[i] == "/")
{
Push(S, num2 / num1);
}
}
}
//最终栈顶元素即为结果
cout <<"结果为:" << Pop(S) << endl;
}
int main()
{
//1.输入后缀表达式
string behind[Maxsize];
int len=0;
string x;
while (cin >> x) {
behind[len++] = x;
if (cin.get() == '\n')
break;
}
//2.计算后缀表达式
Caculate(behind,len);
system("pause");
return 0;
}
输出结果:

🍰四.队列在层序遍历中的应用
✨ 树是一种非常重要的数据结构,它在计算机科学中的应用非常广泛,我们在学习树的过程中,常常会遇到树的遍历,树的遍历分为三种方式:前序遍历、中序遍历和后序遍历,而在树的层次遍历中,我们需要使用 队列 这种数据结构
树的层次遍历是一种非常重要的遍历方式,它的遍历顺序是从树的根节点开始,一层一层地遍历,直到遍历完所有的节点,在这个过程中,每一层的节点都按照从左到右的顺序进行遍历
图解:

step:
- 根节点入队
- 若队空,即所有结点都已经处理完,则结束遍历;
- 若队不空,队列中的第一个结点出队,并对其进行访问,令其左右孩子入队(如果没有则跳过)
- 不断重复,直到队为空,则得到层序遍历结果
代码实现:
void levelTraverse(TreeNode *root) {
queue<TreeNode*> q;
q.push(root);
while(!q.empty()) {
TreeNode* node = q.front();
q.pop();
cout << node->val << " ";
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
}
🍰五.队列在计算机系统中的应用
✨在目前的计算机技术中,大量的外部设备,例如打印机和扫描仪等设备的工作速度比主机更为缓慢。它们也许需要一段时间来完成它们的工作。这就导致了一个问题,尽管它们接收到来自主机发送的任务,但是它们可能并没有准备好去处理它们。这会导致一些任务被阻塞,系统的处理速度也会变慢。这时,许多计算机系统使用队列来解决这个问题
✅ 对于主机与打印机速度不匹配的问题:
在一个计算机系统中,多个用户可能同时请求打印机去工作。这可能导致打印机出现资源竞争的情况,最终导致任务的延迟和其他问题。如果没有一个好的管理机制去控制多个请求的呈现,这些请求可能会让打印机出现超负荷运行。这时,管理员将可以使用队列来管理打印机任务。当有新的打印请求时,管理员会将它们排队,等候被处理。打印机接收每个任务,并从队列中按照优先级或其他条件按顺序地处理任务
✅ 对于CPU资源的竞争的问题:
数量庞大的用户同时使用计算机资源时,也会发生类似的竞争情况。这种竞争会极大地影响系统的整体性能和稳定性。当多个用户同时请求计算机资源时,管理员也可以将请求加入到一个队列中,依照前面的例子,以解决这个问题。每个请求会在队列中等候被处理,管理员会按照特定的规则对其进行排序。然后,当计算机资源可用时,管理员可以按照队列中请求的顺序,将它们授予用户访问权限
文章来源:https://www.toymoban.com/news/detail-499138.html
 文章来源地址https://www.toymoban.com/news/detail-499138.html
文章来源地址https://www.toymoban.com/news/detail-499138.html
到了这里,关于【数据结构】栈和队列的应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!