欢迎关注『OpenCV DNN @ Youcans』系列,持续更新中
本系列从零开始,详细讲解使用 Flask 框架构建 OpenCV DNN 模型的 Web 应用程序。
在上节的基础上,本节介绍使用OpenCV DNN对实时视频进行目标检测。DNN目标检测的基本步骤也是加载图像、模型设置和模型推理。
3.10 OpenCV DNN+Flask实时监控目标检测
在上节的基础上,本节介绍使用OpenCV DNN对实时视频进行目标检测。DNN目标检测的基本步骤也是加载图像、模型设置和模型推理。
我们使用TensorFlow深度学习框架在MS COCO数据集上训练的MobileNet SSD(单次检测器)模型。与其他目标检测模型相比,SSD 模型通常更快。此外,MobileNet 主干网还降低了计算密集度。因此,对于使用OpenCV DNN进行目标检测,MobileNet是一个很好的模型。
MS COCO数据集(https://cocodataset.org/)是当前基于深度学习的对象检测模型的基准数据集。MS COCO包括80类日常物品,从人到汽车,再到牙刷。可以使用文本文件加载 MS COCO 数据集中的所有标签。
1、加载MobileNet SSD模型
在VideoStream类初始化程序中,使用readNet()函数加载MobileNet SSD模型。model为预训练权重文件的路径,即冻结计算图(frozen graph)的路径。Config为模型配置文件的路径,即protobuf文本文件的路径。Framework为加载模型的框架名称,本例中是TensorFlow。
# 加载 DNN 模型:MobileNet SSD 模型
model = cv2.dnn.readNet(model='./models/frozen_inference_graph.pb',
config='./models/ssd_mobilenet_v2_coco.pbtxt',
framework='TensorFlow')
2、导入分类名称文件
然后导入读取分类名称文件object_detection_classes_coco.txt,该文件将每个类别名称存储在列表class_names中,用新行分隔每个类别。例如:
[‘person’, ‘bicycle’, ‘car’, ‘motorcycle’, ‘airplane’, ‘bus’, ‘train’, ‘truck’, ‘boat’, ‘traffic light’, … ‘book’, ‘clock’, ‘vase’, ‘scissors’, ‘teddy bear’, ‘hair drier’, ‘toothbrush’, ‘’]
为每个类别随机设置不同颜色COLORS,用于使用指定颜色为每个类别绘制边界框,以便在图像中通过边界框的颜色来区分不同类别。元组COLORS包括3个整数值,表示颜色分量。
# 读取 COCO 类别名称
with open('object_detection_classes_coco.txt', 'r') as f:
class_names = f.read().split('\n')
# 为每个类别随机设置不同的颜色
COLORS = np.random.uniform(0, 255, size=(len(class_names), 3))
3、处理视频帧进行目标检测
本例程在主线程中处理视频帧进行目标检测,使用一个线程update_frame()实时获取新的视频帧。
在主线程中的生成器函数gen_frames()逐帧获取图片,使用MobileNet SSD(单次检测器)模型进行目标检测,将图像编码后返回给客户端。客户端浏览器收到视频流以后,在img标签定义的图片中逐帧显示,从而实现视频播放。
生成器函数gen_frames() 处理视频帧进行目标检测的步骤如下:
(1)由视频帧 frame 创建blob对象;
(2)使用MobileNet SSD模型,进行目标检测;
(3)对检测到的目标进行筛选,确定目标类别和边界框;
(4)在视频帧上绘制边界框,并标注类别名称;
(5)将图像编码后返回给客户端。
例程如下。
# 创建 blob
blob = cv2.dnn.blobFromImage(image=image, size=(300, 300), mean=(104, 117, 123), swapRB=True)
# 基于 DNN 模型的目标检测
start = time.time()
self.model.setInput(blob) # 模型输入图像
output = self.model.forward() # 模型前向推理
end = time.time()
fps = 1 / (end - start) # 计算帧处理速率 FPS
# 目标检测结果的后处理
for detection in output[0, 0, :, :]:
# 提取检测的置信度
confidence = detection[2]
# 当置信度高于阈值时才绘制边界框
if confidence > 0.5:
class_id = detection[1] # 获取类别的id
if class_id >= 90: class_id = 89 # 防止类别id超出范围
class_name = self.class_names[int(class_id) - 1] # 将id映射为类别标签
color = self.COLORS[int(class_id)] # 该类别的颜色设置
# color = (0, 255, 0)
# 获取矩形边界框的参数 (x, y, w, h)
x_box = int(detection[3] * w_img)
y_box = int(detection[4] * h_img)
w_box = int(detection[5] * w_img)
h_box = int(detection[6] * h_img)
# 在图像上绘制检测目标的矩形边界框
cv2.rectangle(image, (x_box, y_box), (w_box, h_box), color, thickness=2)
# 在图像上添加类别名称
cv2.putText(image, class_name, (x_box, y_box - 5), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 2)
# 在图像上添加 FPS 文本
# cv2.putText(image, f"{fps:.2f} FPS", (20, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
4、新建一个Flask项目
新建一个Flask项目cvFlask10,本项目的框架与cvFlask09相同。
cvFlask10项目的文件树如下。
---文件名\
|---models\
| |--- object_detection_classes_coco.txt
| |--- ssd_mobilenet_v2_coco.pbtxt
| |--- ssd_mobilenet_v2_coco_frozen.pb
|---templates\
| |---index4.html
| |---index5.html
|--- cvFlask10.py
|--- vedio_01.mp4
5、Python 程序文件
任务逻辑由Python程序文件cvFlask10.py实现,完整代码如下。
# cvFlask10.py
# OpenCV+Flask 图像处理例程 10
# OpenCV+Flask+threading+MobileNet SSD
# OpenCV 实时读取摄像头,MobileNetSSD 模型目标检测,浏览器实时播放监控视频
# Copyright 2023 Youcans, XUPT
# Crated:2023-5-18
# coding:utf-8
from flask import Flask, Response, request, render_template
import threading
import time
import numpy as np
import cv2
app = Flask(__name__) # 实例化 Flask 对象
# 定义视频流类
class VideoStream:
def __init__(self, source): # 传入视频源
# 创建视频捕获对象,调用笔记本摄像头
# cam = cv2.VideoCapture(0, cv2.CAP_DSHOW) # 修改 API 设置为视频输入 DirectShow
self.video_cap = cv2.VideoCapture(0) # 创建视频读取对象
self.success, self.frame = self.video_cap.read() # 读取视频帧
threading.Thread(target=self.update_frame, args=()).start()
# 加载 DNN 模型:MobileNet SSD V2 模型
self.model = cv2.dnn.readNet(model="./models/ssd_mobilenet_v2_coco_frozen.pb",
config="./models/ssd_mobilenet_v2_coco.pbtxt",
framework='TensorFlow')
# 读取 COCO 类别名称文件
with open("./models/object_detection_classes_coco.txt", 'r') as f:
self.class_names = f.read().split('\n')
# 为每个类别随机设置不同的颜色
self.COLORS = np.random.uniform(0, 255, size=(len(self.class_names), 3))
def __del__(self):
self.video_cap.release() # 释放视频流
def update_frame(self):
while True:
self.success, self.frame = self.video_cap.read()
def get_frame(self):
image = self.frame
h_img, w_img, _ = image.shape
# 创建 blob
blob = cv2.dnn.blobFromImage(image=image, size=(300, 300), mean=(104, 117, 123), swapRB=True)
# 基于 DNN 模型的目标检测
start = time.time()
self.model.setInput(blob) # 模型输入图像
output = self.model.forward() # 模型前向推理
end = time.time()
fps = 1 / (end - start) # 计算帧处理速率 FPS
# 目标检测结果的后处理
for detection in output[0, 0, :, :]:
# 提取检测的置信度
confidence = detection[2]
# 当置信度高于阈值时才绘制边界框
if confidence > 0.5:
class_id = detection[1] # 获取类别的id
if class_id >= 90: class_id = 89 # 防止类别id超出范围
class_name = self.class_names[int(class_id)-1] # 将id映射为类别标签
color = self.COLORS[int(class_id)] # 该类别的颜色设置
# color = (0, 255, 0)
# 获取矩形边界框的参数 (x, y, w, h)
x_box = int(detection[3] * w_img)
y_box = int(detection[4] * h_img)
w_box = int(detection[5] * w_img)
h_box = int(detection[6] * h_img)
# 在图像上绘制检测目标的矩形边界框
cv2.rectangle(image, (x_box,y_box), (w_box,h_box), color, thickness=2)
# 在图像上添加类别名称
cv2.putText(image, class_name, (x_box,y_box-5), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 2)
# 在图像上添加 FPS 文本
# cv2.putText(image, f"{fps:.2f} FPS", (20, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
ret, buffer = cv2.imencode('.jpg', image) # 编码为 jpg 格式
frame_byte = buffer.tobytes() # 转换为 bytes 类型
return frame_byte
# 生成视频流的帧
def gen_frames(video_source):
video_stream = VideoStream(video_source) # 从视频文件获取视频流
while True:
frame = video_stream.get_frame() # 获取视频帧
if frame is None:
# video_stream.__del__() # 释放视频流
break
yield (b'--frame\r\n' b'Content-Type: image/jpeg\r\n\r\n'
+ frame + b'\r\n') # 生成视频流的帧
@app.route('/video_feed')
def video_feed():
video_source = request.args.get('video_source', 'camera') # 从网页获取视频源
# 通过将一帧帧的图像返回,就达到了看视频的目的。multipart/x-mixed-replace是单次的http请求-响应模式,如果网络中断,会导致视频流异常终止,必须重新连接才能恢复
return Response(gen_frames(video_source), mimetype='multipart/x-mixed-replace; boundary=frame')
@app.route('/')
def index_camera(): # 实时视频监控
# <img src="{{ url_for('video_feed', video_source='camera') }}">
return render_template('index4.html')
@app.route('/vidfile')
def index_vidfile(): # 播放视频文件
# <img src="{{ url_for('video_feed', video_source='vedio_01.mp4') }}">
return render_template('index5.html')
if __name__ == '__main__':
# 启动一个本地开发服务器,激活该网页
print("URL: http://127.0.0.1:5000")
app.run(host='0.0.0.0', port=5000, debug=True, threaded=True) # 绑定 IP 地址和端口号
6、视频流的网页模板
视频流的网页模板index4.html和index5.html位于templates文件夹,内容与cvFlask09项目完全相同。
网页index4.html位于templates文件夹,具体内容如下。
<!DOCTYPE html>
<html>
<head>
<title>Video Streaming Demonstration</title>
</head>
<body>
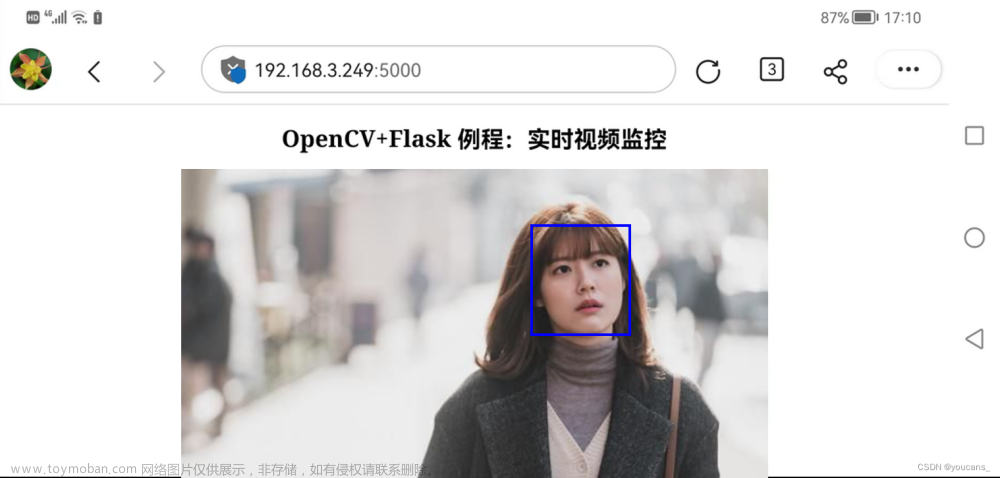
<h2 align="center">OpenCV+Flask 例程:实时视频监控</h2>
<div style="text-align:center; padding-top:inherit">
<img src="{{ url_for('video_feed', video_source='camera') }}" width="600"; height="360">
</div>
</body>
</html>
网页index5.html位于templates文件夹,具体内容如下。
<!DOCTYPE html>
<html>
<head>
<title>Video Streaming Demonstration</title>
</head>
<body>
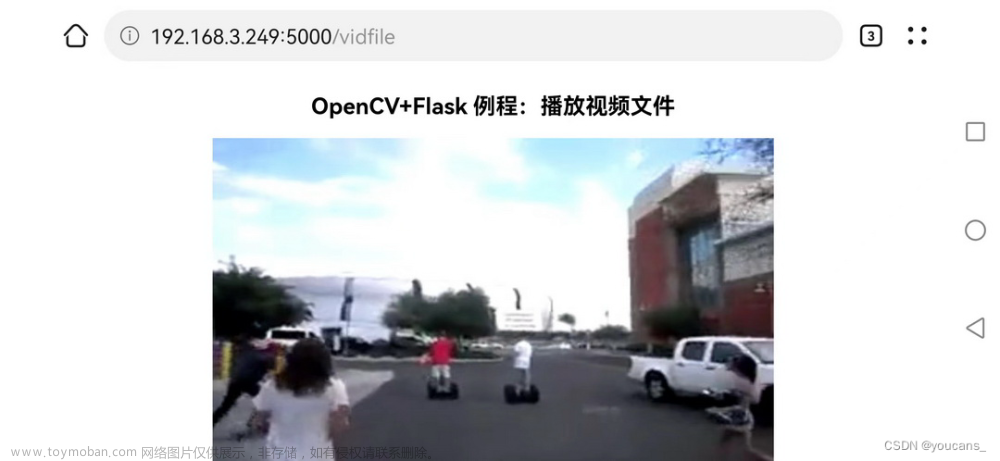
<h2 align="center">OpenCV+Flask 例程:播放视频文件</h2>
<div style="text-align:center; padding-top:inherit">
<img src="{{ url_for('video_feed', video_source='vedio_01.mp4') }}" width="600"; height="360">
</div>
</body>
</html>
7、Flask 视频监控目标检测程序运行
进入cvFlask10项目的根目录,运行程序cvFlask10.py,启动流媒体服务器。
在局域网内设备(包括移动手机)的浏览器打开http://192.168.3.249:5000就可以播放实时视频监控画面。

进一步地,我们添加两个控制按钮“Start”和“Stop”,用来控制开始和停止播放视频流。
在 Flask 应用中添加控制按钮需要修改前端和后端代码。前端需要添加按钮以及发送请求的 JavaScript 代码,后端则需要添加处理这些请求的路由。
我们在前端添加 “start” 和 “stop” 按钮,这两个按钮在被点击时会发送请求到 “/start” 和 “/stop” 路由。
【本节完】文章来源:https://www.toymoban.com/news/detail-499154.html
版权声明:
欢迎关注『OpenCV DNN @ Youcans』系列
youcans@xupt 原创作品,转载必须标注原文链接:
【OpenCV DNN】Flask 视频监控目标检测教程 10
(https://blog.csdn.net/youcans/article/details/131365824)
Copyright 2023 youcans, XUPT
Crated:2023-06-24文章来源地址https://www.toymoban.com/news/detail-499154.html
到了这里,关于【OpenCV DNN】Flask 视频监控目标检测教程 10的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!