K近邻算法(K-Nearest Neighbors, KNN)是一种常用的非参数化的监督学习算法,用于分类和回归任务。本文将深入解析KNN的原理,从距离度量到K值选择,帮助读者全面理解KNN的工作原理和应用。
1. KNN算法概述
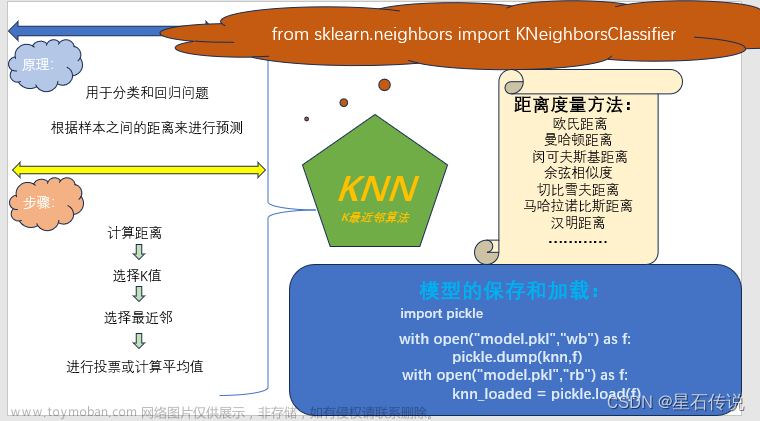
KNN算法基于一个简单的思想:相似的样本具有相似的类别。它通过计算新样本与训练集中各个样本的距离,并选择最近邻的K个样本来进行分类或回归。
2. 距离度量
在KNN算法中,距离度量是判断样本之间相似性的重要指标。常用的距离度量方法有欧氏距离、曼哈顿距离和闵可夫斯基距离等。根据具体问题的特点和数据的属性,选择适当的距离度量方法非常重要。
3. K值选择
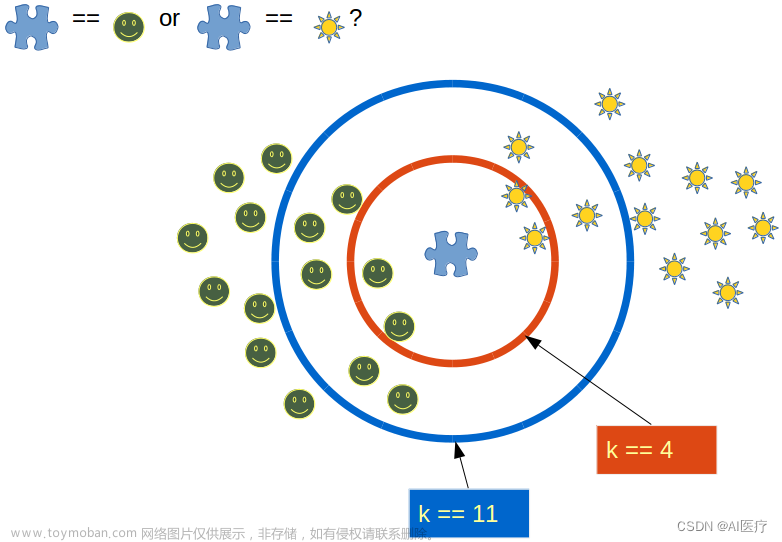
K值是KNN算法中的一个重要参数,它决定了用于分类或回归的邻居数量。选择合适的K值对于模型的性能至关重要。较小的K值会导致模型对噪声敏感,而较大的K值会导致模型过于保守。
4. 分类任务
在KNN算法中,分类任务是最常见的应用场景。当给定一个新样本时,KNN算法通过计算其与训练集样本的距离,并选取最近的K个邻居样本。然后,根据邻居样本的类别进行投票,将新样本归为票数最多的类别。
5. 回归任务
除了分类任务,KNN算法也可以应用于回归任务。在回归任务中,KNN算法计算新样本与训练集样本的距离,并选择最近的K个邻居样本。然后,根据邻居样本的数值进行加权平均,得到新样本的预测值。
6. KNN的优缺点
KNN算法的优点:
- 简单易理解,无需训练阶段。
- 能够处理多类别和多特征的问题。
- 在样本分布较为均匀的情况下表现良好。
KNN算法的缺点:文章来源:https://www.toymoban.com/news/detail-499279.html
- 对于大规模数据集,计算样本之间的距离较为耗时。
- 对于高维数据,距离计算容易受到维度灾难的影响。
- 对于不平衡数据集,分类结果可能偏向于样本较多的类别。
7. KNN算法应用
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建KNN模型
model = KNeighborsClassifier(n_neighbors=3)
# 训练模型
model.fit(X_train, y_train)
# 预测结果
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
代码中,首先加载了一个经典的鸢尾花数据集(Iris),将数据集划分为训练集和测试集。然后创建一个KNN分类模型,并使用训练集进行训练。最后,使用测试集进行预测,并计算准确率来评估模型的性能。文章来源地址https://www.toymoban.com/news/detail-499279.html
到了这里,关于K近邻算法(K-Nearest Neighbors, KNN)原理详解与应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!