决策树是一种常用的机器学习算法,用于解决分类和回归问题。它基于树形结构进行决策,通过一系列的分裂和判断条件来预测目标变量的值。本文将详细解析决策树的原理,从基本概念到建立模型的过程
1. 决策树基本概念
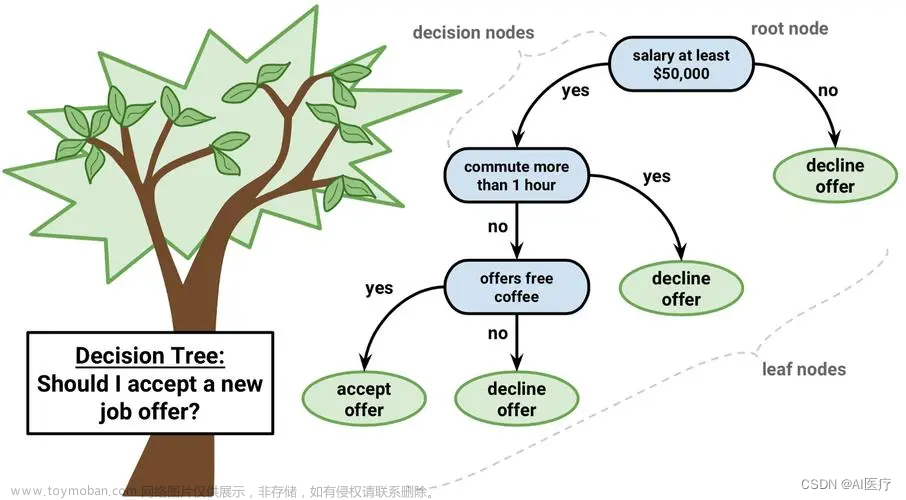
决策树由节点和边组成,其中节点表示特征或属性,边表示特征的取值。决策树的根节点代表最重要的特征,分支节点代表中间特征,叶节点代表最终的分类或回归结果
2. 决策树构建过程
决策树的构建过程包括特征选择、节点分裂和停止条件。具体步骤如下:
- 特征选择:选择最佳的特征作为当前节点的判别标准。常用的特征选择方法有信息增益、信息增益率、基尼系数等
- 节点分裂:根据选择的特征将当前节点分裂成多个子节点。不同的分裂算法有不同的准则,如ID3、C4.5、CART等
- 停止条件:当满足某个停止条件时,停止分裂并将当前节点标记为叶节点。常见的停止条件有节点样本数小于阈值、节点纯度达到一定程度等
3. 决策树分类和回归
决策树可以用于分类问题和回归问题。
- 分类问题:在分类问题中,决策树通过将输入特征映射到类别标签来进行分类。叶节点代表不同的类别
- 回归问题:在回归问题中,决策树通过将输入特征映射到数值输出来进行预测。叶节点代表数值输出
4. 决策树优缺点
决策树算法的优点:
- 简单直观:决策树易于理解和解释,可以可视化展示决策过程
- 适用性广泛:决策树可以处理离散型和连续型特征,适用于分类和回归问题
- 鲁棒性:决策树对异常值和缺失数据具有较好的鲁棒性
决策树算法的缺点:文章来源:https://www.toymoban.com/news/detail-499362.html
- 容易过拟合:决策树倾向于过分拟合训练数据,可能导致泛化能力较差
- 不稳定性:数据的细微变动可能导致完全不同的决策树结构
5. 决策树代码实例
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X_train, y_train)
# 预测结果
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
代码中,首先加载了一个经典的鸢尾花数据集(Iris),然后将数据集划分为训练集和测试集。接下来,创建了一个决策树分类模型,并使用训练集进行训练。最后,使用测试集进行预测,并计算准确率来评估模型的性能文章来源地址https://www.toymoban.com/news/detail-499362.html
到了这里,关于决策树(Decision Tree)原理解析:从基本概念到建立模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Machine Learning] decision tree 决策树](https://imgs.yssmx.com/Uploads/2024/02/665843-1.png)




![大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍](https://imgs.yssmx.com/Uploads/2024/02/580122-1.png)



