home page:segment-anything.com
code:segment-anything
1. 概述
介绍:SAM是最近提出的一种通用分割大模型,其表现出了强大的零样本泛化能力,视觉感知模型的通用化又前进了一步。为了达到文章标题字面意义“segment anything”,那么就需要该算法具有强大的物体语义感知能力,在模型的设计阶段就不能对其所使用的类别进行假设,更类似于常见的交互式分割方法。像交互式分割这样的方法,在现有的大模型体系下提示的相关操作被描述为prompt。在SAM算法中就支持点、框、mask和文本四种不同的prompt,它的零样本泛化能力也是基于此。说到要训练分割大模型,一个问题便是如何获取足够且高质量的数据,对此文章也提出了一种数据生产的pipeline,并且将收集到的训练数据也做了开源segment-anything-downloads(1100万图像数据,10亿mask GT)。
先放一张SAM模型的感知结果:
效果真的是很惊艳,要是再搭配上对应的文本模型,这样就具备具体语义和mask信息的感知能力了。
本文博文将围绕SAM模型运行原理和数据生产过程这两个关键点,依据现有公开出来的文章内容进行梳理。
2. SAM方法
2.1 数据生产
当前网络上公开的数据集量都是比较少的,对应导致其场景适应性只能展现在某些固定的领域场景下。那么要训练一个具备“通用”价值的模型,这些数据量是不足的,对此文章提出了对应的data engine去获取训练数据。其获取数据的方法可以划分为如下几个步骤:
- Step1:使用交互式分割这样的工具在初始数据集上完成人工标注。
- Step2:在人工标注基础上训练一个分割模型,新到的图片数据首先会经过这个模型完成预标注,之后人工在对其进行修补,可看作为半自动化标注。
- Step3:从第二步获取到相对足够的数据之后,再迭代一个更加强大模型,之后在图像上均匀采样点的方式去构建prompt,在新数据集下获得新的mask标注。
下图展示了SAM模型进行数据迭代的流程示意图:
最终SAM依据上述的方法获取了1100万训练数据和10亿数量级的mask标注。这个数量级的数据展现了丰富的数据多样性,将文章获取到的数据集于其它一些常见分割数据集进行对比:
图像尺寸分布对比:
则单从数据角度看SA-1B数据集的分布更全面,涵盖的内容更加丰富,这也会使得在此基础上训练出来的模型展现出更强的泛化能力。
2.2 SAM算法
2.2.1 算法pipeline
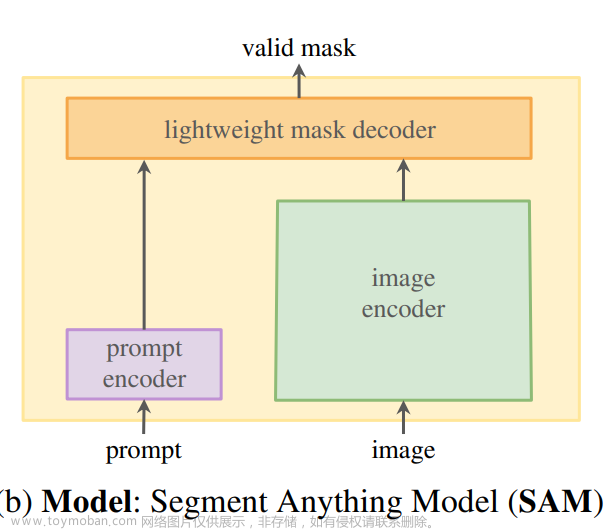
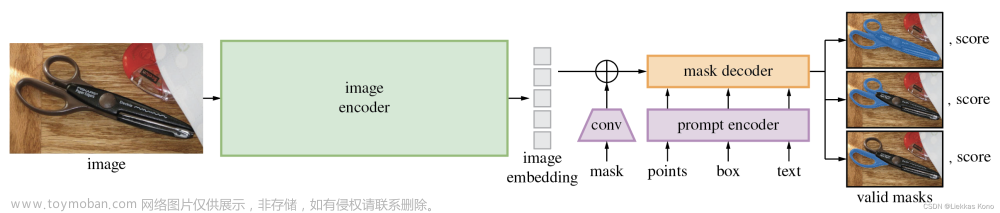
SAM算法定位是一种具备强大泛化能力的分割模型,也就是对于那些训练数据中未见过的数据也能进行分割,对此这个算法采取了prompt的机制,也就是支持下图中间部分的四个类型的输入(mask、points、box、text)。
同时上图也是SAM算法的原理框图,按照上面的框图可以将SAM算法划分成如下几个部分:
Image Encoder:
这里使用MAE自监督训练得到的ViT模型作为图像特征的抽取网络。
Prompt Encoder:
上文也提到了SAM算法支持的几种prompt方式,对于points、box位置编码的形式嵌入到网络中,对于mask则采用几层卷积的方式提取embedding,对于text则是采用CLIP中的文本编码器得到对应的embedding。
Mask Decoder:
这个部分负责输出具体的mask预测,这里的预测方式采用的是MaskFormer的方式,将不同的分割目标构建为不同的query,在此基础上预测mask和class。这里的mask decoder是一个轻量化的模型,它的层数为2,其结构见下图:
以往query只作为query只有self-attention和cross-attention操作,在上图中还会将query和image进行交换形成双向的attention操作,
Resolving ambiguity:
由于SAM所使用的数据具备细粒度的特点,这就导致了一个prompt可能会存在多个符合的mask,也就是存在歧义的情况,见下图所示:
对此,文章只提取3个mask来表示一个prompt需要分割的区域(3个mask为经验值,文中认为这个数量可以hold住大多数场景),也就是可以将这些mask划分为whole、part和sub-part三种情况。同时在预测mask的时候还会预测每个mask的IoU,在最后选择的时候会根据这个分数选择最后的mask输出。
Loss& Training:
对于mask分割部分采用focal+dice的形式,权重设置为20:1。SAM支持多种prompt输入,则在训练的过程也需要对这样的过程进行模拟。同时为了模拟实际使用中的交互分割过程,还为每个mask设计11轮的随机prompt采样。
2.2.2 SAM中实现的一些细节
如何使得网络输出带有多义性:
在之前的图例中展示了一个prompt在人的感官上会有多个mask与之匹配,则SAM模型应该也具备这样的能力,毕竟每个人的想法不太一样,既然众口难调,那么就给出模型认为正确的mask就好了。也就是说对于一个prompt模型设计3个mask token去预测对应的mask,这样可以避免只预测一个mask带来的输出结果收敛的情况。
那么对于多个prompt的情况,会在3个token的基础上添加一个token,且在输出的时候只输出新添加token的预测结果。
训练时prompt的生成:
这里讨论points、box和mask类型的prompt生成,对于text部分的prompt在后面内容进行讨论,对于points的采样范围是整个mask区域,对于box是在原本mask bounding box基础上添加noise。将上面两种类型prompt作为输入得到对应的mask预测,选择预测结果中IoU值预测最高的作为下一轮迭代的输入,这个迭代的输入可以为替换为mask prompt了。 则对于下一轮迭代的时候points采样会从预测mask于GT比较的error区域中再采样得到。文章来源:https://www.toymoban.com/news/detail-499539.html
text prompt生成:
在训练数据中选择那些较大的mask(大于
10
0
2
100^2
1002像素数),并通过尺寸扩增之后从图像中取出对应crop。这个crop输入到CLIP模型中去获取对应的text embedding(CLIP中图像和text是paired,有了图像可以得到对应的text描述)。再用这个text embedding作为SAM的prompt,去生成对应的mask预测。这样就使得SAM具备了text语义感知能力,下图展示了从text得到分割结果的示例: 文章来源地址https://www.toymoban.com/news/detail-499539.html
文章来源地址https://www.toymoban.com/news/detail-499539.html
到了这里,关于Segment Anything——论文笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[segment-anything]使用onnxruntime部署sam模型,速度提高30倍!](https://imgs.yssmx.com/Uploads/2024/02/461140-1.jpeg)