绪论:中文用几个字节保存
不知道你们的大学老师有没有说过中文是用两个字节保存,直到我了解了字符编码,然后留下了这几行代码
#include<string.h>
#include<stdio.h>
int main()
{
wchar_t w = 'a'; //宽字节
char c = 'a'; // 多字节
char *pc;
wchar_t *pw;
pc = "abc中"; //多字节字符串的赋值
pw = L"abc中"; //宽字节字符串的赋值
int clen = strlen(pc); //求多字节字符串的长度 clen=5
int wlen = wcslen(pw); //求宽字节字符串的长度 wlen=4;
printf("strlen:%d,wcslen:%d\n", clen, wlen);
return0;
}
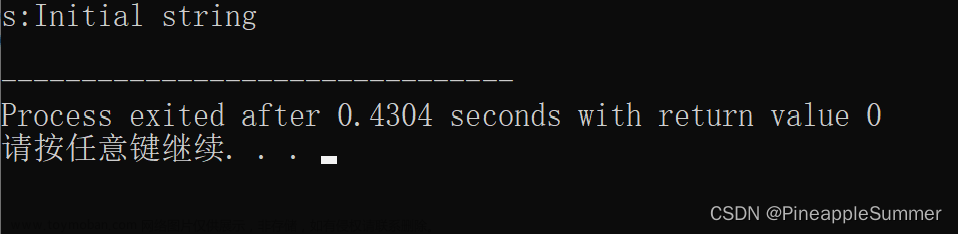
strlen:5,wcslen:4
结果很明显,不同的编码方式,中文所占字节也不一样 ,而这就要从Windows下的字符集说起。
说起Windows下的编程,可能大家的印象都是:微软从来都“特立独行”,什么都要来自己的一套,连类型都不例外。C语言下预设的一些基本类型,微软几乎都typedef过,如BYTE,WORD,DWORD等。那么,今天我们来简单聊聊Windows编程下的字符集和字符串类型。
之所以要聊一聊这个,是因为在过年前有一个同学来我们公司面试,我们让面试的同学写一段代码,其中有一个功能是输出一段文字,结果输出内容始终都不对。那么现在开始简单的梳理一下,Windows下常见的这些字符串类型。
一、ASCII和UNICODE
在很久很久以前,天地一片混沌之时,操作系统大部分都是英文系统。当时的人们认为,我们只要用很少的二进制位数,就可以表示大部分我们需要的字符,这也就是ASCII编码规范。然鹅,现实总是很骨感,很快人们发现,短短七八位的二进制位数根本不能满足全宇宙人民的需要,于是UNICODE应运而生,它致力于整理一套统一的规范来表示所有我们用到的字符。我们可以认为UNICODE是兼容ASCII的,只是它会占用更多的空间。每一个字符对应一个UNICODE编码,至于编码如何布局(布局是指每个二进制位的含义),我们又规定了诸多编码规范,其中最为出名的就是utf-8和utf-16。
如果不考虑国际化,统一用ascii,那么每个字符将占用8位,也就是一个字节的大小。如果用utf-16来表示字符串,那么每个字符至少是16位,也就是2个字节。这也就决定了,字节的基本长度到底是一个字节,还是两个字节。
在Windows中,内部是以utf-16来保存字符串的。它支持两套API,用来兼容ASCII和UNICODE,分别以A和W结尾。例如,MessageBoxA表示它接受ASCII类型的字符串,而MessageBoxW表示接受UNICODE字符串。
在代码中,若是定义UNICODE和_UNICODE,则Windows API将会展开为带W的函数,否则将展开为带A的函数。例如,定义了UNICODE的情况下,MessageBox会被展开为MessageBoxW。
二、char和wchar_t
同时支持ASCII和UNICODE,这给C程序员带来了无尽的麻烦。这不得不定义一种新类型来表示UNICODE,这便是wchar_t。char众所周知,表示的是一个字符,如'a', '1'都是char。wchar_t表示的是一个“宽字符”,它的长度比char要大,在vs下为16位,和short一致。在定义一个宽字符组成的字符串时,要在字面值前加上L,如L'a',表示的就是一个宽字符a。
C语言中的字符串,其实就是以0结尾的一串字符。而字符又分为窄字符(char)和宽字符(wchar_t)。同样的,在字符串字面值前加上L表示的是宽字符串,如L"hello"。
我们在对字符串进行操作时,必须要小心翼翼,了解它到底是宽字符串还是窄字符串。例如,在获取字符串长度时,窄字符串是strlen,而宽字符串是wcslen。我一直都搞不懂为什么不按照strlen的命名规则来,命名为wstrlen呢,这样多容易记。好在两个函数明确写出了一个接受的参数是const char*,另外一个是const wchar_t*,如果传入了错误的字符串类型,则会得到一个错误。不幸的是,有些函数可能接受的是一个void*,如果你传入了错误的字符串类型,则可能要花大把时间来定位问题。
三、LPCSTR和LPCWSTR
这两个是Windows API中最为常见的两种字符串类型。LP表示Long Pointer,指针。C表示const,STR表示窄字符串,WSTR表示宽字符串,那么翻译过来就是:
LPCSTR = constchar*
LPCWSTR = constwchar_t*
很多初学者在定义了UNICODE的情况下,调用一些API,却传入了LPCSTR,这样就会得到一个编译错误。解决的方式就是在字面值前加上L。
四、TCHAR,LPCTSTR
如果我们希望编写编码集无关的代码,我们很可能会写出以下代码:
#ifndef _UNICODE
LPCSTR szStr = "hello";
#else
LPCWSTR szStr = L"hello";
#endif
有没有办法来自动区分是否是用ASCII还是UNICODE?微软提供了TCHAR,以及TCHAR字符串类型LPCTSTR。
简单来说,TCHAR和LPCTSTR会根据当前字符集来选择字符类型。使用_T宏将字符串包围起来,如_T("hello"),如果是UNICODE字符集,将会被展开为L"hello",否则不变。
那么以上代码可以改为:
LPCTSTR szStr = _T("hello");
五、更多类型,如OLECHAR,BSTR,CString,QString
OLECHAR和BSTR用于COM编程,它们都有相应的函数来创建、控制和销毁。CString是ATL中封装的一个字符串类型,多用于MFC项目。QString是Qt中强大的字符串类。
六、建议
之前提到有一个同学来面试,他使用了LPCTSTR来保存一个字符串,然后用std::cout来输出字符串,结果只得到了一个指针的地址。原来他在vs设置里,将字符集调成了UNICODE,那么其实他定义的是个宽字符串,得有wcout才能得到正确的结果。
以下是建议:
1.尽量使用UNICODE字符集。它对程序效率有提升(因为Windows是用utf-16保存字符串),不会在底层进行字符集的转换。
2.尽量使用同一体系下的字符串。例如,如果是C风格的Windows编程,那么就尽量不要std和Windows风格字符串混用。可以参考Windows核心编程,里面介绍了如何用Windows API来操控字符串。同样,也尽量不要混用LCPSTR,CString以及QString等,除非你知道中间到底发生了什么。
如果有可能的话,可以看看Qt中QString的源代码,使用它几乎可以满足所有字符串的要求。文章来源:https://www.toymoban.com/news/detail-499550.html
最后说一下,字符串看似简单,其实里面蕴藏的知识不少,希望大家阅读了本文之后,能对字符串类型有个基本的了解。文章来源地址https://www.toymoban.com/news/detail-499550.html
到了这里,关于浅谈Windows的各种“字符串”的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!