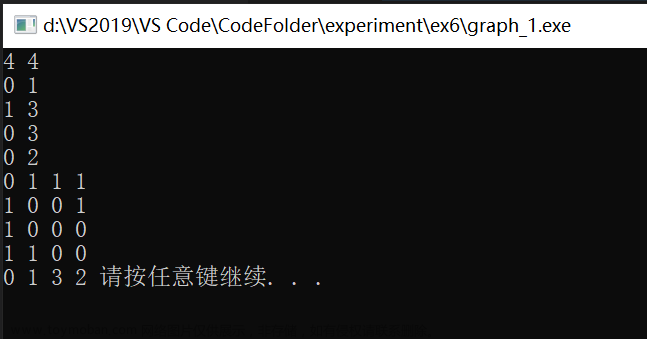
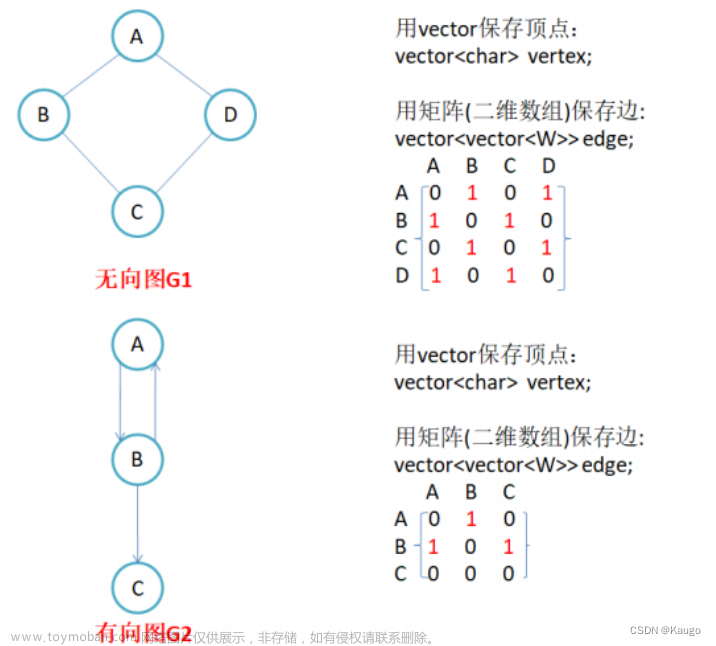
广度优先遍历又称为广度优先搜索,简称BFS
如果说图的深度优先遍历(图的深度优先遍历相关内容:图的深度优先遍历)类似树的前序遍历,那么图的广度优先遍历就类似于树的层序遍历。
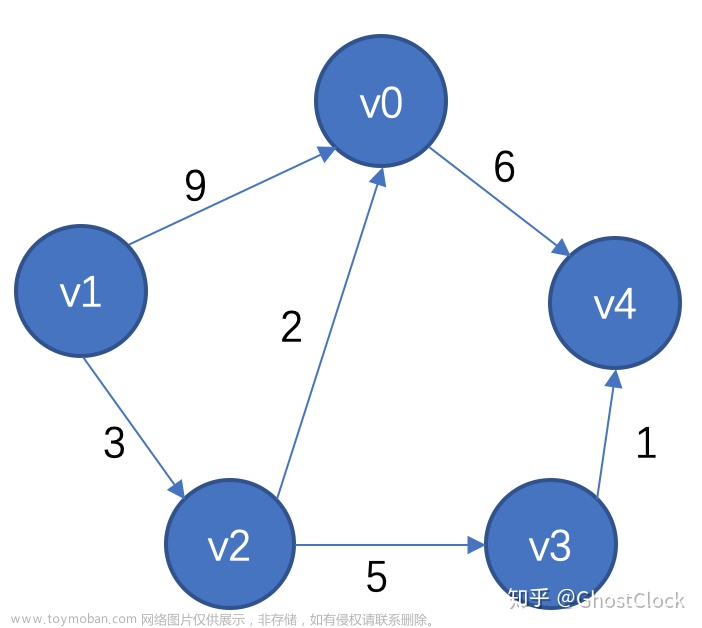
具体遍历过程如下图所示:

就如上面的第三个图上所编写的序号进行遍历
我们要实现这样的遍历方法需要一个辅助队列,将处理过后的顶点(比如输出顶点)放入队列中,在找邻接点时找的便是队列顶部的顶点的邻接点,将队列顶部的顶点出队列后获得出队列的顶点的下标,根据下标找到该顶点的所有邻接点,再将所有邻接点依次放到队列中,循环往复直到队列中没有顶点,就遍历完了一个连通图。
上面图的队列的变化过程:

当然我们需要一个标志数组,在遍历到顶点后,标记该顶点已被遍历过,避免重复遍历到相同的顶点。
代码展示:
ps:该代码包括了队列以及无向网图的创建过程,所以我们需要注意的是邻接矩阵的广度遍历算法:BFSTraverse函数。有关队列的创建以及相关操作可看这里:循环队列,邻接表和邻接矩阵的创建细节可看这里:邻接矩阵,邻接表
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
typedef char VertexType;//顶点类型
typedef int EdgeType;//边上的权值类型
#define MAXVEX 20//最大顶点数(开辟储存顶点的一维数组的空间大小)
#define INFINITY 10000//用10000来代表无穷(在储存边的二维数组中,对没有该边存在的表格,权值设为无穷)
//定义图的结构体(图由储存顶点的一维数组和储存边的二维数组,以及记录图中结点数和边数的int类型的变量组成)
struct MGraph
{
VertexType vexs[MAXVEX];//储存顶点的一维数组
EdgeType arc[MAXVEX][MAXVEX];//储存边的二维数组
int Num_vex, Num_arc;//图中的顶点数和边数
};
//定义队列的结构体
struct Queue
{
//队列储存顶点下标
//作为队列的数组
int data[MAXVEX];
//头指针
int front;
//尾指针
int rear;
};
//初始化队列
void InitQueue(Queue& q)
{
q.front = 0;
q.rear = 0;
}
//入队列
void EnQueue(Queue& q, int& index)
{
//判断队列是否已满
if ((q.rear + 1) % MAXVEX == q.front)
return;
//将数据index放入队列
q.data[q.rear] = index;
q.rear = (q.rear + 1) % MAXVEX;
}
//出队列
//将出队列的数据赋给index
void OutQueue(Queue& q, int& index)
{
index = q.data[q.front];
q.front = (q.front + 1) % MAXVEX;
}
//判断队列是否为空
bool Juge_Queue(Queue& q)
{
if (q.front == q.rear)
//为空返回false
return false;
//不为空返回true
return true;
}
//无向网图的创建
void Create_MGraph(MGraph& G)
{
int m, n;
cout << "请输入图的顶点数和边数" << endl;
cin >> G.Num_vex >> G.Num_arc;
cout << "请依次输入图的顶点:" << endl;
for (int i = 0; i < G.Num_vex; i++)
{
cin >> G.vexs[i];
}
//初始化储存边的二维数组
for (int i = 0; i < G.Num_vex; i++)
for (int j = 0; j < G.Num_vex; j++)
{
G.arc[i][j] = INFINITY;
}
//向二维数组中输入对应边的权值
for (int k = 0; k < G.Num_arc; k++)
{
cout << "请依次输入边(Vm,Vn)的下标m,n" << endl;
cin >> m >> n;
cout << "请输入边(" << G.vexs[m-1] << "," << G.vexs[n-1] << ")的权值" << endl;
cin >> G.arc[m - 1][n - 1];
//由于是无向网图,所以存在边(m,n),就存在边(n,m)所以我们还应该向二维数组的(n,m)位置输入权值
G.arc[n - 1][m - 1] = G.arc[m - 1][n - 1];
}
}
//邻接矩阵的广度遍历算法
void BFSTraverse(MGraph& G)
{
//标志数组
//false表示在顶点数组中该下标的顶点没有被遍历过
bool visited[MAXVEX];
//初始化标志数组
for (int i = 0; i < G.Num_vex; i++)
{
visited[i] = false;
}
//定义队列q
Queue q;
//初始化队列
InitQueue(q);
//找出一个连通中用于开始遍历的顶点
//遍历所有结点为了避免图中有不连通的情况,要是图中顶点都是连通的可以不用for循环这一步(但你要先定义一个首次遍历的顶点i)
for (int i = 0; i < G.Num_vex; i++)
{
if (!visited[i])
{
//遍历到了标志改为true
visited[i] = true;
//输出遍历到的顶点
cout << G.vexs[i] << " ";
//将遍历到的顶点的下标放入队列
//为了一会找该顶点的邻接点
EnQueue(q, i);
//找邻接点
//队列不为空就一直寻找邻接点
while (Juge_Queue(q))
{
int index;
OutQueue(q, index);
for (int j = 0; j < G.Num_vex; j++)
{
if (G.arc[index][j] != INFINITY && !visited[j])
{
visited[j] = true;
cout << G.vexs[j] << " ";
EnQueue(q, j);
}
}
}
}
}
}
int main()
{
MGraph G;
Create_MGraph(G);
BFSTraverse(G);
system("pause");
return 0;
}上面程序中所包含的BFSTraverse函数是用于遍历邻接矩阵的,而遍历邻接表也只是因为邻接表与邻接矩阵构造不同而有细微的差异,具体思路没有变化。
这里我们就只展示遍历的函数文章来源:https://www.toymoban.com/news/detail-499574.html
邻接表遍历:文章来源地址https://www.toymoban.com/news/detail-499574.html
/标志数组
//false表示对应下标的顶点数组中的顶点没有被遍历过
bool visited[MAXSIZE];
//邻接表的广度优先遍历
void BFSTraverse(GraphAdiList& G)
{
Queue q;
//初始化队列q
InitQueue(q);
//初始化标志数组
for (int i = 0; i < G.numVertex; i++)
{
visited[i] = false;
}
//找到第一个用来遍历的顶点
for (int i = 0; i < G.numVertex; i++)
{
if (visited[i] == false)
{
visited[i] = true;
cout << G.Adjext[i].vetex << " ";
//入队列
//将下标i入队列
EnQueue(q, i);
while (Judge_Queue(q) == true)
{
int index;
//出队列
OutQueue(q, index);
//边表结点指针s用来遍历边表
EdgeNode* s = G.Adjext[index].FirstEdge;
while (s)
{
if (visited[s->adjvex] == false)
{
visited[s->adjvex] = true;
cout << G.Adjext[s->adjvex].vetex << " ";
EnQueue(q, s->adjvex);
s = s->next;
}
}
}
}
}
}到了这里,关于广度优先遍历(邻接表,邻接矩阵)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!