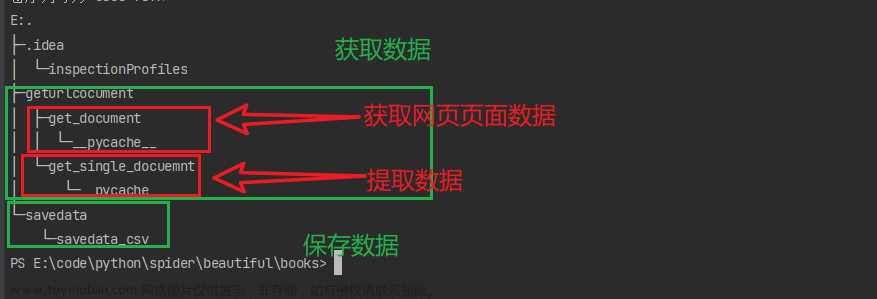
前几天爬取豆瓣的时候,以为豆瓣是没有反爬的,直到碰到了豆瓣阅读...
这里是官网:https://read.douban.com/ebooks/?dcs=original-featured&dcm=normal-nav
需求:爬取里面13个图书类别,每个类别500本,最后保存到excel表中

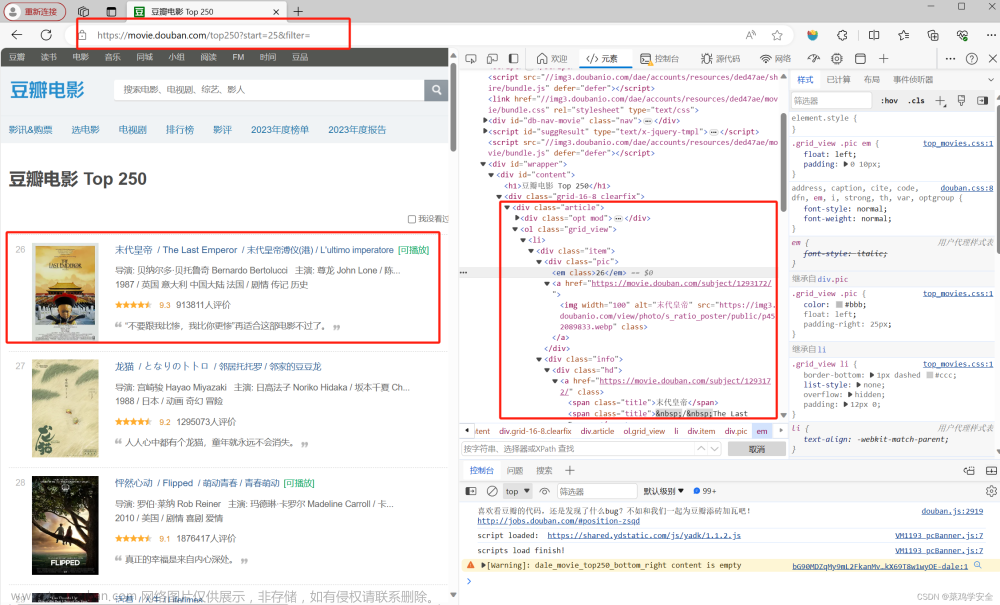
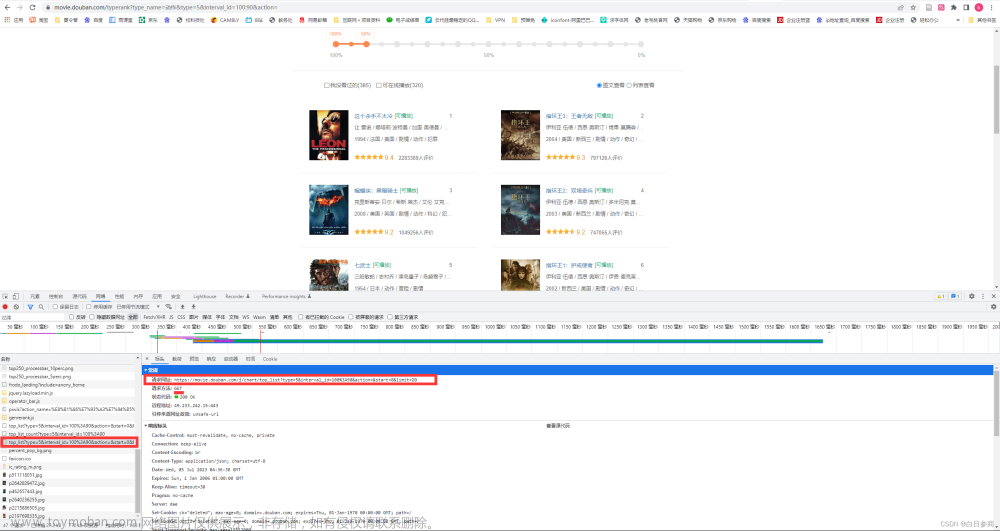
这是包含书本链接url的负载 ,如果有大佬可以逆向出来,就可以不用selenium
用到的工具:asyncio,aiohttp,time,openpyxl,lxml,selenium
import asyncio
import aiohttp
import time
import openpyxl
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By先导入包
def chu(q):
url = []
option = webdriver.ChromeOptions()
option.add_experimental_option('detach', True)
driver = webdriver.Chrome(chrome_options=option)#初始化一个Chrome对象
driver.get('https://read.douban.com/ebooks/?dcs=original-featured&dcm=normal-nav')
#请求url
time.sleep(2)
#等待页面加载
page = driver.page_source
tree = etree.HTML(page)#解析页面源代码
#豆瓣会对频繁访问的ip进行登陆验证,所以这里使用try防止报错
try:
#如果没有登陆验证的话
lei_url = tree.xpath('//ul[@class="list kinds-list tab-panel"]//a/@href')
#获取每个类别的url
lei = driver.find_element(By.XPATH,f'//ul[@class="list kinds-list tab-panel"]/li/a[@href="{lei_url[q]}"]')
lei.click()
#模拟点击,进入类别相应的页面
except:
#如果有登录验证的话
login = input('请在网页上进行登录,登录完成后输入1:')
#手动登录,因为需要滑块验证码,本人技术层次没那么高
time.sleep(2)
#等待页面加载
lei_url = tree.xpath('//ul[@class="list kinds-list tab-panel"]//a/@href')
lei = driver.find_element(By.XPATH, f'//ul[@class="list kinds-list tab-panel"]/li/a[@href="{lei_url[q]}"]')
lei.click()
#和上面同样的做法
count = 1
while count <31:
time.sleep(2)
#等待页面加载
page = driver.page_source
tree = etree.HTML(page)
#获取每本书的url
print('正在抓取url')
url.append(tree.xpath('//ul[@class="works-list"]/li/@to'))
time.sleep(1)
driver.find_element(By.XPATH,'//div[@class="paginator-full"]//a[@class="page-next"]').click()
#模拟点击,进入下一页,循环,直到满30页
count += 1
driver.quit()
return urlselenium模拟采集url,返回的数据是一个列表,每20个url为一个元素,方便后面进行异步操作。
接下来进行对书本信息进行采集
book_page = []
#用来存储书本信息
async def pa_book(url#传入url,q#判断书本类别):
#使用异步函数,大大节省运行时间
count = 0
b = []
header = {
'User-Agent': '你的ua',
'Cookie': '浏览器里自行复制'
}#豆瓣cookie是固定的,我们复制下来一段,保持登陆状态
async with aiohttp.ClientSession() as session:
#初始化一个session对象
async with await session.get(url=url,headers=header) as resp:
#对页面发起请求
tree = etree.HTML(await resp.text())
#用xpath进行解析
try:
#因为有些书本信息不全,防止报错,我们直接使用try
o = 0
zuozhe = tree.xpath('//div[@class="article-meta"]//text()')
prise = tree.xpath('//s[@class="original-price-count"]/text()')[0]
mingzi = tree.xpath('//span[@itemprop="itemListElement"]//span[@itemprop="name"]/text()')[0]
pingjia = tree.xpath('//span[@class="amount"]/text()')[0]
#存入信息
b.append(mingzi)
b.append(mane[q])
b.append(zuozhe[zuozhe.index('类别') + 1])
b.append(zuozhe[zuozhe.index('作者') + 1])
b.append(zuozhe[zuozhe.index('出版社') + 1])
b.append(zuozhe[zuozhe.index('提供方') + 1])
b.append(zuozhe[zuozhe.index('字数') + 1])
b.append(zuozhe[zuozhe.index('ISBN') + 1])
b.append(pingjia)
b.append(prise)
book_page.append(b)
except:
#跳过不全的书本
count += 1
这样书本信息就采集好了,接下来存入excel表中
我们需要准备一个名称为书籍.xlsx.的文件不然会报错
def cun():
w = 2
wb = openpyxl.load_workbook('书籍.xlsx')
ws = wb['Sheet1']
top = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
for o in book_page:
count = 0
for j,i in zip(o,top):
ws[f'{i}{w}'] = j
count +=1
w = w+1
#这个很简单写写循环就可以了
wb.save('书籍.xlsx')最后一步代码运行
for q in range(14):
p = 1
for url in chu(q):
task = []
for i in url:
task.append(pa_book(f'https://read.douban.com{i}',q))
#注册进循环里
print(f'正在爬取第{p}页------------')
p += 1
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task))
#运行
time.sleep(2)
#等待2秒防止访问被拒
print('success')
cun()
#存入数据完整代码实现
import asyncio
import aiohttp
import time
import openpyxl
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
start_time = time.time()
mane = ['小说', '文学', '人文社科', '经济管理', '科技科普', '计算机与互联网', '成功励志', '生活', '少儿', '艺术设计', '漫画绘本', '教育考试', '杂志']
def chu(q):
url = []
option = webdriver.ChromeOptions()
option.add_experimental_option('detach', True)
driver = webdriver.Chrome(chrome_options=option)
driver.get('https://read.douban.com/ebooks/?dcs=original-featured&dcm=normal-nav')
time.sleep(2)
page = driver.page_source
tree = etree.HTML(page)
try:
lei_url = tree.xpath('//ul[@class="list kinds-list tab-panel"]//a/@href')
lei_name = tree.xpath('//ul[@class="list kinds-list tab-panel"]//a/text()')
lei = driver.find_element(By.XPATH,f'//ul[@class="list kinds-list tab-panel"]/li/a[@href="{lei_url[q]}"]')
lei.click()
except:
login = input('请在网页上进行登录,登录完成后输入1:')
time.sleep(2)
lei_url = tree.xpath('//ul[@class="list kinds-list tab-panel"]//a/@href')
lei_name = tree.xpath('//ul[@class="list kinds-list tab-panel"]//a/text()')
lei = driver.find_element(By.XPATH, f'//ul[@class="list kinds-list tab-panel"]/li/a[@href="{lei_url[q]}"]')
lei.click()
count = 1
while count <9:
time.sleep(2)
page = driver.page_source
tree = etree.HTML(page)
print('正在抓取url')
url.append(tree.xpath('//ul[@class="works-list"]/li/@to'))
time.sleep(1)
driver.find_element(By.XPATH,'//div[@class="paginator-full"]//a[@class="page-next"]').click()
count += 1
driver.quit()
return url
book_page = []
async def pa_book(url,q):
count = 0
b = []
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'Cookie': 'bid=eLRBZmbY55Y; dbcl2="267875740:kPdFiwjWprY"; ck=ijB_; _ga=GA1.3.133779158.1679229659; _gid=GA1.3.10458227.1679229659; _pk_ref.100001.a7dd=%5B%22%22%2C%22%22%2C1679229659%2C%22https%3A%2F%2Faccounts.douban.com%2F%22%5D; _pk_ses.100001.a7dd=*; _ga=GA1.1.133779158.1679229659; __gads=ID=de972e154c2fef7a-22a0163bd5de0064:T=1679229662:RT=1679229662:S=ALNI_MaXNgyOFMsVTnhbnDSgMLFd_tnQ5w; __gpi=UID=00000bdc08bc9484:T=1679229662:RT=1679229662:S=ALNI_MY0Iz9JEbO8VuYeFJ3xJQOu75jnQw; _ga_RXNMP372GL=GS1.1.1679229658.1.1.1679229769.56.0.0; _pk_id.100001.a7dd=d883665af68561be.1679229659.1.1679229771.1679229659.'
}
async with aiohttp.ClientSession() as session:
async with await session.get(url=url,headers=header) as resp:
tree = etree.HTML(await resp.text())
try:
o = 0
zuozhe = tree.xpath('//div[@class="article-meta"]//text()')
prise = tree.xpath('//s[@class="original-price-count"]/text()')[0]
mingzi = tree.xpath('//span[@itemprop="itemListElement"]//span[@itemprop="name"]/text()')[0]
pingjia = tree.xpath('//span[@class="amount"]/text()')[0]
b.append(mingzi)
b.append(mane[q])
b.append(zuozhe[zuozhe.index('类别') + 1])
b.append(zuozhe[zuozhe.index('作者') + 1])
b.append(zuozhe[zuozhe.index('出版社') + 1])
b.append(zuozhe[zuozhe.index('提供方') + 1])
b.append(zuozhe[zuozhe.index('字数') + 1])
b.append(zuozhe[zuozhe.index('ISBN') + 1])
b.append(pingjia)
b.append(prise)
book_page.append(b)
except:
count += 1
def cun():
w = 2
wb = openpyxl.load_workbook('书籍.xlsx')
ws = wb['Sheet1']
top = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
for o in book_page:
count = 0
for j,i in zip(o,top):
ws[f'{i}{w}'] = j
count +=1
w = w+1
wb.save('书籍.xlsx')
for q in range(14):
p = 1
for url in chu(q):
task = []
for i in url:
task.append(pa_book(f'https://read.douban.com{i}',q))
print(f'正在爬取第{p}页------------')
p += 1
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task))
time.sleep(2)
print('success')
cun()
end_time = time.time()
run_time = -start_time+end_time
print(f'本次运行时间为{run_time}s')
我加了一个运行时间显示
注意:1.代码运行过程中如果停止那么信息会全部丢失,前功尽弃,可以通过修改循环次数来控制爬取量
2.还是会有封ip的风险,如果没有爬过豆瓣的可以一次性爬完,可以加代理ip文章来源:https://www.toymoban.com/news/detail-499618.html
本人爬虫萌新,纯粹练手,如有侵权请告知,希望大佬们多提建议文章来源地址https://www.toymoban.com/news/detail-499618.html
到了这里,关于selenium + 异步爬取豆瓣阅读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!