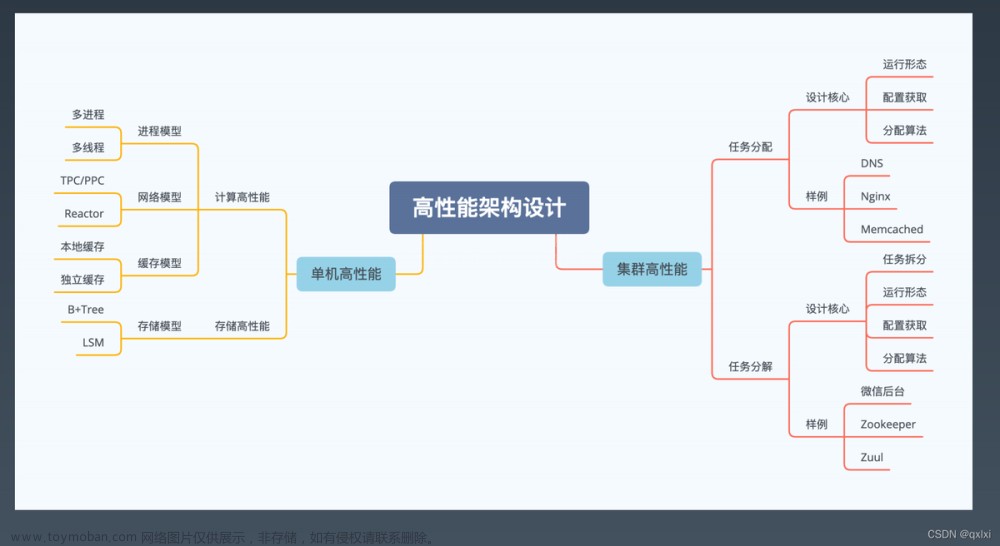
实验目的
- 叙述支持向量机算法的基本思想;
- 描述支持向量机算法的整个分类过程;
实验内容
- 利用支持向量机对给定数据集进行分类识别;
- 对比支持向量机在不同参数设定下的分类性能;
- 对支持向量机算法的分类性能进行评估。
实验步骤
1、支持向量机算法
1.1 支持向量机算法的基本思想
支持向量机(Support Vector Machine,简称SVM)是一种常见的机器学习算法,其基本思想是在高维空间中构建一个超平面,用于分类或回归任务。
具体而言,SVM首先将数据映射到高维空间,并在该空间中找到一个最优的超平面,使得该超平面能够将不同类别的数据点有效地分开。其中,对于最优超平面的定义是使得间隔最大化,即离超平面最近的数据点到超平面的距离最大化。这些最靠近超平面的样本点被称为支持向量。
SVM最终分类的过程是将新的数据点映射到高维空间,并根据其位置与最优超平面的关系来进行分类。如果新数据点在超平面正侧,则属于正类;反之则属于负类。
1.2 支持向量机算法的分类过程
支持向量机算法的分类过程主要包括以下几个步骤:
- 数据预处理:对原始数据进行特征提取和特征选择,将数据转化为合适的形式。
- 特征映射:将原始的特征空间通过某个映射函数映射到高维特征空间,使得数据在该空间中线性可分。
- 最优超平面的选择:在高维特征空间中寻找一个最优的超平面来将不同类别的样本点分开。其中最优超平面满足:离超平面最近的样本点到超平面的距离最大化。
- 支持向量的确定:确定最优超平面上的支持向量,即距离超平面最近的数据点。
- 分类:将新的样本点投影到高维特征空间中,并根据其位置(在最优超平面的哪一侧)和超平面来进行分类,即按照所在的类别标签进行打标。
具体而言,在分类过程中,我们使用 SVM 学习得到的最优超平面对新样本进行分类。首先将新样本映射到高维特征空间中。然后,计算测试样本与最优超平面之间的距离(距离的计算是以超平面上的支持向量计算的)。如果该距离小于某个预设阈值,则将该测试样本分类为正类;否则,将该测试样本分类为负类。这个预设阈值就是 SVM 的决策边界(discriminative boundary)所对应的距离(或称为"裕度",margin)。因此 SVM 对新样本的分类结果取决于它与决策边界(即分离超平面)之间的距离。
总之,SVM 通过特征映射和最优超平面的选择,将不同类别的样本点分开,并在测试时,通过计算距离来对新的样本点进行分类。超平面实现分类效果、以及各个参数之间关系可参考图一。

1.3 支持向量机算法的模型构建过程
SVM(Support Vector Machine)的模型构建流程通常包括以下步骤:
- 数据收集与预处理:收集相关数据并进行数据清洗、变换、标准化等预处理工作,以保证数据质量和可用性。
- 特征选择与提取:选择合适的特征变量作为模型输入,或者从现有特征中提取新的特征变量。特征选择和提取是 SVM 模型中非常关键的一环,它们往往对最终模型的表现产生重要影响。
- 训练数据集划分:将收集到的数据划分为训练数据集和测试数据集,以便在训练过程中验证模型的准确性和性能。
- 核函数和参数选择:选择合适的核函数和参数,这决定了 SVM 在特征空间中寻找决策边界的能力。常用的核函数有线性核、多项式核、高斯径向基核等,不同的核函数及其参数设定会影响模型的分类性能。
- SVM 模型训练:使用训练数据集进行模型训练,求解最优解,即找到合适的超平面和分类边界,使得两类样本之间的距离最大化,并且满足一定约束条件。
- 模型评估:使用测试数据集对模型进行性能评估,包括计算模型的准确率、召回率、F1 值等指标,以判断模型效果的好坏。
- 模型的调优和改进:根据评估结果,对模型进行调优和改进,包括优化模型参数、特征选择和提取方法等方面,以提高模型的泛化能力和分类性能。
- 模型应用:将优化后的 SVM 模型应用于实际问题中,进行样本分类和预测,以实现数据分析和决策支持等功能。图二展示了其中一个训练模型,图三则展示出常见的核函数。


2、使用Python语言编写支持向量机的源程序代码并分析其分类原理
2.1 支持向量机SVM模型代码
2.1.1 计算SVM中使用的核函数calcKernelValue()
用于计算核函数值的函数,其实现了线性核和径向基函数(RBF)核。该函数通过循环逐个计算每个样本与待测样本之间的核函数值,并将结果存储在一个数组中返回。这些核函数值将在后续步骤中用于计算支持向量机模型的决策边界和预测结果。
(1) 首先获取了输入矩阵 matrix_x 的总行数,即数据集中的样本数目 numSamples。
(2) 如果 kernelType 为 ‘linear’,那么就使用线性核函数计算 kernelValue,这里直接使用矩阵乘法计算所有训练样本与待计算样本的内积;
(3) 如果 kernelType 为 ‘rbf’,那么就使用径向基函数(RBF)核计算 kernelValue,这里计算每个训练样本与待计算样本之间的欧氏距离,并根据参数 sigma 计算出高斯核函数的值。
(4) 如果 kernelType 不是 ‘linear’ 或 ‘rbf’,则会抛出一个 NameError 异常。最后,该函数返回 kernelValue,即所有样本和待计算样本之间的核函数值。图4为SVM中核函数的具体实现:

2.1.2 向量机(SVM)模型的训练和测试
实现了一个支持向量机(SVM)模型的训练和测试。使用的是Sequential Minimal Optimization(SMO)算法来求解SVM的优化问题,其中包含了计算样本之间核函数值、选择优化参数、更新阈值等步骤。此外还有对于数据可视化和模型准确度计算的函数。需要注意的是,此段代码只适用二维数据的可视化。
这段代码定义了一个SVMStruct类,用于存储SVM模型的相关参数和数据,其中包括:
SVMStruct初始化:创建存储变量和数据的结构体,并且初始化一些变量值;
calcError函数:计算优化参数的误差值;
selectAlpha_j函数:选择第二个优化参数;
innerLoop函数:SMO算法中的内循环,用于更新alpha的值;
trainSVM函数:整个SVM模型的训练过程;
testSVM函数:使用测试集来测试训练好的SVM模型的准确度;
showSVM函数:用于在二维数据上可视化SVM模型的结果。
下图展示了其中innerLoop函数的核心代码:

2.1.3 SVM模型的测试代码
这段代码实现对SVM算法的测试,具体包括以下步骤:
- 从文件’testSet.txt’中读取数据,并将其处理为Numpy矩阵类型,其中前80个样本作为训练数据train_x、train_y,后20个样本作为测试数据test_x、test_y。
- 使用SVM.trainSVM函数在训练数据集上训练SVM模型,得到svmClassifier。
- 使用SVM.testSVM函数对测试数据集进行测试,得到分类准确率accuracy。
- 使用SVM.showSVM函数展示SVM模型在二维空间内的分类结果。
主要作用是对SVM算法的正确性进行验证,通过测试样例来检验实现是否正确和有效。
图6则展示了这段代码的测试结果。

SVM的优缺点:
优点:
1、在高维空间中⾮常高效;
2、即使在数据维度⽐样本数量⼤的情况下仍然有效;
3、在决策函数(称为支持向量)中使用训练集的子集,因此它也是⾼效利用内存的;
4、通用性:不同的核函数与特定的决策函数⼀⼀对应;
缺点:
1、SVM算法对于大规模数据处理较为困难,计算复杂度较高;
2、对于多分类问题,需要进行多次二分类,计算量较大;
3、对于不平衡数据集,SVM算法可能会出现过拟合的情况;
4、SVM算法在确定核函数类型、参数设置等方面存在一定的主观性和经验性。
实验小结
通过本次实验,我能够熟练叙述支持向量机算法的基本思想;描述支持向量机算法的整个分类过程。可以根据实验内容完成使用Python语言编写支持向量机算法的源程序代码并分析其分类原理。在实验过程中遇到了很多硬件或者是软件上的问题,请教老师,询问同学,上网查资料,都是解决这些问题的途径。最终将遇到的问题一一解决最终完成实验。文章来源:https://www.toymoban.com/news/detail-499700.html
支持向量机(SVM)算法在分类性能上的表现受到参数设定的影响较大,其中两个主要的参数是核函数类型和正则化参数。不同的参数设定可能会对SVM的分类性能产生不同的影响。以下是比较不同参数设定下SVM分类性能的方法:
核函数类型:
SVM算法采用核函数实现对数据特征空间的映射,从而实现非线性分类。通常情况下,我们可以使用多项式核函数、径向基函数等不同类型的核函数来处理不同的数据集。
正则化参数:
SVM中的正则化参数C对模型复杂度和泛化能力有重要影响。当C的值较小时,相当于对模型做了更强的正则化,更倾向于选择一个较小的分隔超平面,性能更加稳定,但容易产生欠拟合;当C的值较大时,相当于对模型的约束比较少,可能出现过拟合的情况。
因此,对比SVM在不同参数设定下的分类性能,需要进行实验比较:
1、选取几类不同的核函数类型,比较它们在相同的数据集上的分类性能;
2、在使用相同核函数的情况下,对C参数进行调整,比较它们的分类性能;
3、绘制学习曲线和验证曲线来判断模型是否过拟合或欠拟合。
通过以上实验比较,可以得出最优的SVM参数设定,以达到最好的分类性能。需要注意的是,SVM的参数设定与数据集密切相关,需要针对不同的数据集进行调整。文章来源地址https://www.toymoban.com/news/detail-499700.html
到了这里,关于【高性能计算】监督学习之支持向量机分类实验的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!