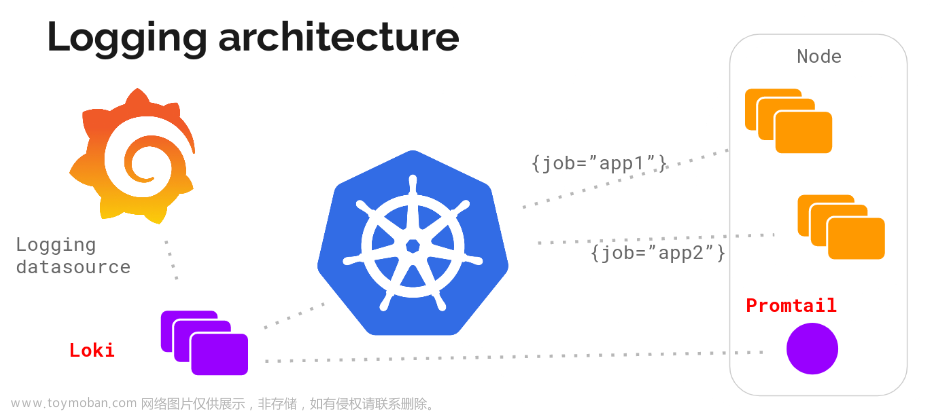
当我们在k8s上运行程序时,习惯的会使用ELK来收集和查询程序运行日志。今天我们介绍一款新的专为日志收集而生的神器:Grafana loki。Grafana Loki 是一组组件,可以组合成一个功能齐全的日志堆栈。
与其他日志记录系统不同,Loki 仅构建索引有关日志的元数据:标签(就像 Prometheus 标签)。 然后,日志数据本身被压缩并以块的形式存储在 S3 或 GCS 等对象存储中,甚至存储在本地文件系统中。 小索引和高度压缩的块简化了操作并显着降低了 Loki 的成本。
基本介绍

agent(也称为客户端)用于获取日志,将日志转换为流,并通过 HTTP API 将流推送到 Loki。 Promtail agent专为 Loki 安装而设计,但许多其他agent也可以与 Loki 无缝集成。

Loki 索引流。 每个流标识一组与一组唯一标签相关联的日志。 一组高质量的标签是创建既紧凑又允许高效查询执行的索引的关键。
LogQL 是 Loki 的查询语言。
Loki 基本特性
-
用于索引日志的高效内存使用
通过在一组标签上建立索引,索引可以比其他日志聚合产品小得多。 更少的内存使得操作成本更低。
-
多租户
Loki 允许多个租户使用一个 Loki 实例。 不同租户的数据与其他租户完全隔离。 通过在代理中分配租户 ID 来配置多租户。
-
LogQL,Loki 的查询语言
Prometheus 查询语言 PromQL 的用户会发现 LogQL 熟悉且灵活,可以针对日志生成查询。 该语言还有助于从日志数据生成指标,这是一个远远超出日志聚合的强大功能。
-
可扩展性
Loki 可以作为单个二进制文件运行; 所有组件都在一个进程中运行。
Loki 专为可扩展性而设计,因为 Loki 的每个组件都可以作为微服务运行。 配置允许单独扩展微服务,允许灵活的大规模安装。
-
灵活性
许多代理(客户端)都有插件支持。 这允许当前的可观察性结构将 Loki 添加为他们的日志聚合工具,而无需切换可观察性堆栈的现有部分。
-
Grafana 集成
Loki 与 Grafana 无缝集成,提供完整的可观察性堆栈。
部署模式
作为一个应用程序,Loki 由许多组件微服务构建而成,旨在作为可水平扩展的分布式系统运行。 Loki 的独特设计将整个分布式系统的代码编译成一个单一的二进制或 Docker 镜像。 该单个二进制文件的行为由 -target 命令行标志控制,并定义三种操作模式之一。
每个部署的二进制实例的配置进一步指定了它运行的组件。
Loki 旨在根据您的需求变化轻松地在不同模式下重新部署集群,无需更改配置或更改最少的配置。
单体模式
最简单的运行模式设置-target=all。这就是单体模式; 它以单个二进制文件或 Docker 镜像的形式在单个进程中运行所有 Loki 的微服务组件。

单体模式对于快速开始使用 Loki 进行实验以及每天最多约 100GB 的小读/写量非常有用。
通过使用共享对象存储并将环部分配置为在所有实例之间共享状态,将单体模式部署横向扩展到更多实例。
可以通过使用 memberlist_config 配置和共享对象存储运行两个 Loki 实例来配置高可用性。
以循环方式将流量路由到所有 Loki 实例。
查询并行化受实例数量和定义的查询并行度的限制。
简单的可扩展部署模式
如果您的日志量每天超过几百 GB,或者您希望分离读写关注点,Loki 提供了简单的可扩展部署模式。 这种部署模式可以扩展到每天数 TB 的日志甚至更多。 考虑用于超大型 Loki 安装的微服务模式方法。

在这种模式下,Loki 的组件微服务被捆绑到两个目标中:-target=read 和 -target=write。 BoltDB 压缩器服务将作为读取目标的一部分运行。
分离读写路径有以下好处:
- 通过提供专用节点提高写入路径的可用性
- 单独可扩展的读取路径以按需添加/删除查询性能
简单的可扩展部署模式需要在 Loki 前面有一个负载均衡器,它将 /loki/api/v1/push 流量定向到写入节点。 所有其他请求都转到读取节点。 应以循环方式发送流量。
Loki 的简单可扩展部署可以扩展到每天数 TB 的日志甚至更多。
微服务模式
微服务部署模式将 Loki 的组件实例化为不同的进程。 调用每个进程并指定其目标:
- ingester
- distributor
- query-frontend
- query-scheduler
- querier
- index-gateway
- ruler
- compactor

将组件作为单独的微服务运行允许通过增加微服务的数量来扩展。 定制的集群对各个组件具有更好的可观察性。 微服务模式部署是最高效的 Loki 安装。 但是,它们的设置和维护也是最复杂的。
对于非常大的 Loki 集群或需要更多控制扩展和集群操作的集群,建议使用微服务模式。
微服务模式最适合 Kubernetes 部署。 有 Jsonnet 和分布式 Helm chart安装。
基本组成

Distributor
分发服务器负责处理客户端传入的流。 它是日志数据写入路径中的第一站。 一旦分发者收到一组流,每个流都会被验证其正确性并确保它在配置的租户(或全局)限制内。 然后将有效块分成批次并并行发送到多个摄取器。
重要的是,负载均衡器位于分发器的前面,以便正确地平衡分发给它们的流量。
分发器是无状态组件。 这使得从摄取器(写入路径上最关键的组件)扩展和卸载尽可能多的工作变得容易。 独立扩展这些验证操作的能力意味着 Loki 还可以保护自己免受拒绝服务攻击(无论是恶意的还是非恶意的),否则这些攻击可能会使摄取器过载。 他们就像前门的保镖,确保每个人都穿着得体并收到邀请。 它还允许我们根据复制因子扇出写入。
验证
distributor采取的第一步是确保所有传入数据均符合规范。 这包括检查标签是否是有效的 Prometheus 标签,以及确保时间戳不会太旧或太新,或者日志行不会太长。
预处理
目前,分发者改变传入数据的唯一方法是规范化标签。 这意味着使 {foo=“bar”, bazz=“buzz”} 等同于 {bazz=“buzz”, foo=“bar”},或者换句话说,对标签进行排序。 这允许 Loki 确定性地缓存和散列它们。
限流
分发者还可以根据每个租户的最大比特率对传入日志进行速率限制。 它通过检查每个租户的限制并将其除以当前的分销商数量来做到这一点。 这允许在集群级别为每个租户指定速率限制,并使我们能够向上或向下扩展分发器,并相应地调整每个分发器的限制。 例如,假设我们有 10 个分发者,租户 A 的速率限制为 10MB。 每个分发者在限制之前最多允许 1MB/秒。 现在,假设另一个大租户加入集群,我们需要再启动 10 个分发者。 现在的 20 个分发者将他们对租户 A 的速率限制调整为(10MB / 20 个分发者)= 500KB/s! 这就是全局限制如何使 Loki 集群的操作更加简单和安全。
注意:分发者使用hood下的环组件在其对等体中注册自己并获得活跃分发者的总数。 这是与环中摄取器使用的不同“密钥”,来自分发者自己的环配置。
转发
一旦分发器执行了它的所有验证职责,它就会将数据转发到最终负责确认写入的摄取器组件。
复制因子
为了减少在任何单个摄取器上丢失数据的机会,分发器会将写入转发到它们的 replication_factor。 通常,这是 3。复制允许 ingester 重新启动和推出而不会导致写入失败,并为某些情况添加额外的数据丢失保护。 松散地,对于推送到分发器的每个标签集(称为流),它将散列标签并使用结果值查找环中的 replication_factor 摄取器(这是公开分布式哈希表的子组件)。 然后它将尝试将相同的数据写入所有这些数据。 如果少于法定数量的写入成功,这将出错。 法定人数定义为 floor(replication_factor / 2) + 1。因此,对于 3 的 replication_factor,我们需要两次写入成功。 如果少于两次写入成功,则分发器返回错误并重试写入。
警告:还有一种边缘情况,如果三个摄取器中有两个执行写入,我们就会确认写入,这意味着在 2 个写入成功的情况下,我们只能在遭受数据丢失之前丢失一个摄取器。
不过,复制因素并不是防止数据丢失的唯一因素,可以说,如今它的主要目的是允许写入在推出和重新启动期间不间断地继续进行。 ingester 组件现在包括一个预写日志,该日志将传入的写入持久保存到磁盘,以确保只要磁盘未损坏,它们就不会丢失。 复制因子和 WAL 的互补性确保数据不会丢失,除非两种机制都出现重大故障(即多个摄取器死亡并丢失/损坏其磁盘)。
哈希
分发者使用一致的散列和可配置的复制因子来确定哪些摄取服务实例应该接收给定的流。
流是与租户和唯一标签集相关联的一组日志。 使用租户 ID 和标签集对流进行哈希处理,然后使用哈希查找将流发送到的摄取器。
Consul中存储了一个哈希环,用于实现一致性哈希; 所有摄取者都使用他们拥有的一组令牌将自己注册到哈希环中。 每个令牌都是一个随机的无符号 32 位数字。 连同一组令牌,摄取器将它们的状态注册到哈希环中。 状态 JOINING 和 ACTIVE 都可以接收写入请求,而 ACTIVE 和 LEAVING ingesters 可以接收读取请求。 在进行哈希查找时,分发者仅对处于适合请求状态的摄取器使用令牌。
为了进行哈希查找,分发者找到最小的适当令牌,其值大于流的哈希值。 当复制因子大于 1 时,下一个属于不同摄取器的后续标记(在环中顺时针方向)也将包含在结果中。
这种散列设置的效果是,ingester 拥有的每个令牌都负责一系列散列。 如果存在三个值分别为 0、25 和 50 的令牌,则将哈希值 3 提供给拥有令牌 25 的摄取器; 拥有令牌 25 的摄取器负责 1-25 的哈希范围。
一致性
由于所有分发者共享对同一个哈希环的访问权限,因此可以将写入请求发送给任何分发者。
为确保一致的查询结果,Loki 在读取和写入时使用 Dynamo 风格的仲裁一致性。 这意味着在响应发起发送的客户端之前,分发器将等待至少一半加其中一个将样本发送到的摄取器的肯定响应。
Ingester
ingester 服务负责在写入路径上将日志数据写入长期存储后端(DynamoDB、S3、Cassandra 等),并在读取路径上返回日志数据用于内存中的查询。
摄取器包含一个生命周期管理器,它管理哈希环中摄取器的生命周期。 每个 ingester 的状态为 PENDING、JOINING、ACTIVE、LEAVING 或 UNHEALTHY:
弃用:WAL(预写日志)取代此功能
- PENDING 是 Ingester 等待来自另一个正在离开的 Ingester 的切换时的状态。
- JOINING 是 Ingester 当前正在将其令牌插入环并初始化自身时的状态。 它可能会收到对其拥有的令牌的写入请求。
- ACTIVE 是 Ingester 完全初始化时的状态。 它可能会收到对其拥有的令牌的写入和读取请求。
- LEAVING 是 Ingester 关闭时的状态。 它可能会收到对它仍在内存中的数据的读取请求。
- UNHEALTHY 是 Ingester 无法向 Consul 发送心跳时的状态。 UNHEALTHY 由分发者在定期检查环时设置。
ingester 接收的每个日志流都在内存中构建成一组许多“块”,并以可配置的时间间隔刷新到后备存储后端。
在以下情况下,块将被压缩并标记为只读:
-
当前块已达到容量(可配置值)。
-
没有更新当前块已经过去了太多时间
-
发生刷写。
每当一个块被压缩并标记为只读时,一个可写块就会取而代之。
如果 ingester 进程突然崩溃或退出,所有尚未刷新的数据都将丢失。 Loki 通常配置为复制每个日志的多个副本(通常是 3 个)以减轻这种风险。
当持久存储提供程序发生刷新时,块将根据其租户、标签和内容进行哈希处理。 这意味着具有相同数据副本的多个摄取器不会将相同的数据写入后备存储两次,但如果对其中一个副本的任何写入失败,则会在后备存储中创建多个不同的块对象。 有关如何对数据进行重复数据删除的信息,请参阅查询器。
时间戳排序
Loki 可以配置为接受乱序写入。
当未配置为接受乱序写入时,摄取器会验证摄取的日志行是否有序。 当 ingester 收到不符合预期顺序的日志行时,该行将被拒绝并向用户返回错误。
ingester 验证日志行是按时间戳升序接收的。 每个日志都有一个时间戳,该时间戳比之前的日志晚出现。 当 ingester 收到不遵循此顺序的日志时,该日志行将被拒绝并返回错误。
来自每组唯一标签的日志在内存中构建成“块”,然后刷新到后备存储后端。
如果摄取进程突然崩溃或退出,则所有尚未刷新的数据都可能丢失。 Loki 通常配置有可以在重启时重播的预写日志以及每个日志的 replication_factor(通常为 3)以减轻这种风险。
当未配置为接受无序写入时,针对给定流(标签的唯一组合)推送到 Loki 的所有行必须具有比之前收到的行更新的时间戳。 但是,有两种情况可以处理具有相同纳秒时间戳的同一流的日志:
- 如果传入行与先前接收到的行完全匹配(匹配先前的时间戳和日志文本),则传入行将被视为完全重复并被忽略。
- 如果传入行与上一行具有相同的时间戳但内容不同,则接受日志行。 这意味着同一时间戳可能有两个不同的日志行。
Handoff - 已弃用以支持 WAL
默认情况下,当一个 ingester 正在关闭并试图离开哈希环时,它将等待查看是否有新的 ingester 在刷新之前尝试进入并尝试启动切换。 切换会将离开的摄取器拥有的所有令牌和内存块转移到新的摄取器。
在加入哈希环之前,ingesters 将在 PENDING 状态等待切换发生。 在可配置的超时后,处于 PENDING 状态且未收到传输的摄取器将正常加入环,插入一组新的令牌。
此过程用于避免在关闭时刷新所有块,这是一个缓慢的过程。
文件系统支持
虽然摄取器确实支持通过 BoltDB 写入文件系统,但这只适用于单进程模式,因为查询器需要访问相同的后端存储,而 BoltDB 只允许一个进程在给定时间锁定数据库。
前端查询
查询前端是提供查询器 API 端点的可选服务,可用于加速读取路径。 当查询前端就位时,传入的查询请求应定向到查询前端而不是查询器。 集群内仍然需要查询器服务,以便执行实际查询。
查询前端在内部执行一些查询调整并将查询保存在内部队列中。 在此设置中,查询器充当工作人员,从队列中提取作业、执行它们并将它们返回到查询前端以进行聚合。 查询器需要配置查询前端地址(通过 -querier.frontend-address CLI 标志)以允许它们连接到查询前端。
查询前端是无状态的。 但是,由于内部队列的工作方式,建议运行一些查询前端副本以获得公平调度的好处。 在大多数情况下,两个副本就足够了。
队列
查询前端排队机制用于:
-
确保在查询器中可能导致内存不足 (OOM) 错误的大型查询将在失败时重试。 这允许管理员为查询提供不足的内存,或者乐观地并行运行更多的小查询,这有助于降低 TCO。
-
通过使用先进/先出队列 (FIFO) 将多个大型请求分布到所有查询器,防止多个大型请求在单个查询器上传送。
-
通过公平地安排租户之间的查询,防止单个租户拒绝服务 (DOSing) 其他租户。
分片
查询前端将较大的查询拆分为多个较小的查询,在下游查询器上并行执行这些查询并将结果再次拼接在一起。 这可以防止大型(多天等)查询在单个查询器中导致内存不足问题,并有助于更快地执行它们。
缓存
指标查询
查询前端支持缓存指标查询结果并在后续查询中重用它们。 如果缓存的结果不完整,查询前端会计算所需的子查询并在下游查询器上并行执行。 查询前端可以选择将查询与其步骤参数对齐,以提高查询结果的可缓存性。 结果缓存与任何 loki 缓存后端(目前是 memcached、redis 和内存缓存)兼容。
日志查询 - 即将推出!
缓存日志(过滤器、正则表达式)查询正在积极开发中。
查询器
查询器服务使用 LogQL 查询语言处理查询,从摄取器和长期存储中获取日志。
查询器在回退到对后端存储运行相同的查询之前查询所有摄取器以获取内存中的数据。 由于复制因素,查询器可能会收到重复的数据。 为了解决这个问题,查询器在内部对具有相同纳秒时间戳、标签集和日志消息的数据进行重复数据删除。
Loki中的一致性哈系环
一致的哈希环被合并到 Loki 集群架构中,以
-
协助日志行的分片
-
实现高可用性
-
简化集群的水平放大和缩小。 对于必须重新平衡数据的操作,性能影响较小。
哈希环在以下情况下连接单一类型组件的实例
-
在整体部署模式下有一组 Loki 实例
-
简单可扩展部署模式下有多个读取组件或多个写入组件
-
微服务模式下一种组件有多个实例
并非所有 Loki 组件都通过哈希环连接。 这些组件需要连接成一个哈希环:
- index gateway
在定义了三个分发器和三个摄取器的架构中,这些组件的哈希环连接相同类型组件的实例。

环中的每个节点代表组件的一个实例。 每个节点都有一个键值存储,用于保存该环中每个节点的通信信息。 节点定期更新键值存储,以保持所有节点的内容一致。 对于每个节点,键值存储包含:
-
组件节点的 ID
-
组件地址,被其他节点用作通信通道
-
组件节点健康状况的指示
配置环
在 common.ring_config 块中定义环配置。
使用默认的成员列表键值存储类型,除非有令人信服的理由使用不同的键值存储类型。 memberlist 使用八卦协议将信息传播到所有节点,以保证键值存储内容的最终一致性。
分配器环、摄取器环和标尺环还有其他配置选项。 这些选项仅用于高级、专门用途。 这些选项在分发器的 distributor.ring 块、摄取器的 ingester.lifecycler.ring 块和标尺的 ruler.ring 块中定义。
关于分配环
分配环使用其键值存储中的信息来计算分配环中的分配器数量。 该计数进一步告知集群限制。
关于摄取环
键值存储中的摄取环信息由分发者使用。 该信息让分发器对日志行进行分片,确定分发器将日志行发送到哪个摄取器或一组摄取器。
关于查询调度器环
查询调度程序使用其键值存储中的信息来进行调度程序的服务发现。 这允许查询器连接到所有可用的调度器,并允许调度器连接到所有可用的查询前端,有效地创建一个有助于平衡查询负载的队列。
关于压缩器环
压缩器使用键值存储中的信息来识别将负责压缩的单个压缩器实例。 压缩器仅在负责的实例上启用,尽管压缩器目标在多个实例上。
关于规则环
规则环用于确定哪些规则评估哪些规则组。
关于索引网关环
索引网关环用于在统治者或查询者查询时确定哪个网关负责哪个租户的索引。
标签
标签是键值对,可以定义为任何东西! 我们喜欢将它们称为元数据来描述日志流。 如果您熟悉 Prometheus,您会经常看到一些标签,例如 job 和 instance,我将在接下来的示例中使用这些标签。
我们为 Grafana Loki 提供的抓取配置也定义了这些标签。 如果您正在使用 Prometheus,那么在 Loki 和 Prometheus 之间拥有一致的标签是 Loki 的超能力之一,这使得将您的应用程序指标与日志数据相关联变得异常容易。
Loki如何使用标签
Loki 中的标签执行一项非常重要的任务:它们定义一个流。 更具体地说,每个标签键和值的组合定义了流。 如果只有一个标签值发生变化,则会创建一个新流。
如果您熟悉 Prometheus,那么那里使用的术语就是系列; 但是,Prometheus 有一个额外的维度:指标名称。 Loki 简化了这一点,因为没有指标名称,只有标签,我们决定使用流而不是系列。
格式
Loki 对标签命名的限制与 Prometheus 相同:
它可能包含 ASCII 字母和数字,以及下划线和冒号。 它必须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
注意:冒号是为用户定义的记录规则保留的。 出口商或直接仪器不应使用它们。
Loki标签示例
这一系列示例将说明 Loki 中标签的基本用例和概念。
让我们举个例子:
scrape_configs:
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: syslog
__path__: /var/log/syslog
此配置将跟踪一个文件并分配一个标签:job=syslog。 你可以这样查询:
{job="syslog"}
这将在 Loki 中创建一个流。
现在让我们稍微扩展一下示例:
scrape_configs:
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: syslog
__path__: /var/log/syslog
- job_name: apache
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: apache
__path__: /var/log/apache.log
现在我们正在跟踪两个文件。 每个文件只有一个标签和一个值,因此 Loki 现在将存储两个流。
我们可以通过几种方式查询这些流:
{job="apache"} <- show me logs where the job label is apache
{job="syslog"} <- show me logs where the job label is syslog
{job=~"apache|syslog"} <- show me logs where the job is apache **OR** syslog
在最后一个示例中,我们使用正则表达式标签匹配器来记录使用具有两个值的作业标签的流。 现在考虑如何使用附加标签:
scrape_configs:
- job_name: system
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: syslog
env: dev
__path__: /var/log/syslog
- job_name: apache
pipeline_stages:
static_configs:
- targets:
- localhost
labels:
job: apache
env: dev
__path__: /var/log/apache.log
现在我们可以这样做,而不是正则表达式:
{env="dev"} <- will return all logs with env=dev, in this case this includes both log streams
希望现在您开始看到标签的力量。 通过使用单个标签,您可以查询多个流。 通过组合几个不同的标签,您可以创建非常灵活的日志查询。
标签是 Loki 日志数据的索引。 它们用于查找压缩的日志内容,这些内容以块的形式单独存储。 标签和值的每个唯一组合都定义了一个流,流的日志被分批、压缩并存储为块。
为了使 Loki 高效且具有成本效益,我们必须负责任地使用标签。 下一节将对此进行更详细的探讨。
Cardinality
前两个示例使用具有单个值的静态定义标签; 但是,有一些方法可以动态定义标签。 让我们使用 Apache 日志和可用于解析此类日志行的大量正则表达式来查看:
11.11.11.11 - frank [25/Jan/2000:14:00:01 -0500] "GET /1986.js HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
- job_name: system
pipeline_stages:
- regex:
expression: "^(?P<ip>\\S+) (?P<identd>\\S+) (?P<user>\\S+) \\[(?P<timestamp>[\\w:/]+\\s[+\\-]\\d{4})\\] \"(?P<action>\\S+)\\s?(?P<path>\\S+)?\\s?(?P<protocol>\\S+)?\" (?P<status_code>\\d{3}|-) (?P<size>\\d+|-)\\s?\"?(?P<referer>[^\"]*)\"?\\s?\"?(?P<useragent>[^\"]*)?\"?$"
- labels:
action:
status_code:
static_configs:
- targets:
- localhost
labels:
job: apache
env: dev
__path__: /var/log/apache.log
此正则表达式匹配日志行的每个组件并将每个组件的值提取到捕获组中。 在管道代码中,此数据被放置在一个临时数据结构中,允许在处理该日志行期间将其用于多种目的(此时临时数据将被丢弃)。 有关更多详细信息,请参阅 Promtail 管道文档。
从该正则表达式中,我们将使用两个捕获组根据日志行本身的内容动态设置两个标签:
动作(例如,action=“GET”, action=“POST”)
status_code(例如,status_code=“200”, status_code=“400”)
现在让我们来看几行示例:
11.11.11.11 - frank [25/Jan/2000:14:00:01 -0500] "GET /1986.js HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
11.11.11.12 - frank [25/Jan/2000:14:00:02 -0500] "POST /1986.js HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
11.11.11.13 - frank [25/Jan/2000:14:00:03 -0500] "GET /1986.js HTTP/1.1" 400 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
11.11.11.14 - frank [25/Jan/2000:14:00:04 -0500] "POST /1986.js HTTP/1.1" 400 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
在 Loki 中,将创建以下流:
{job="apache",env="dev",action="GET",status_code="200"} 11.11.11.11 - frank [25/Jan/2000:14:00:01 -0500] "GET /1986.js HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
{job="apache",env="dev",action="POST",status_code="200"} 11.11.11.12 - frank [25/Jan/2000:14:00:02 -0500] "POST /1986.js HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
{job="apache",env="dev",action="GET",status_code="400"} 11.11.11.13 - frank [25/Jan/2000:14:00:03 -0500] "GET /1986.js HTTP/1.1" 400 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
{job="apache",env="dev",action="POST",status_code="400"} 11.11.11.14 - frank [25/Jan/2000:14:00:04 -0500] "POST /1986.js HTTP/1.1" 400 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"
这四个日志行将成为四个独立的流并开始填充四个独立的块。
与这些标签/值组合相匹配的任何其他日志行都将添加到现有流中。 如果出现另一个唯一的标签组合(例如,status_code=“500”),则会创建另一个新流。
现在想象一下,如果你为 ip 设置一个标签。 来自用户的每个请求不仅成为唯一的流。 来自同一用户的具有不同操作或状态代码的每个请求都将获得自己的流。
快速计算一下,如果可能有四种常见操作(GET、PUT、POST、DELETE)和四种常见状态代码(尽管可能不止四种!),这将是 16 个流和 16 个单独的块。 如果我们为 ip 使用标签,现在将其乘以每个用户。 您可以很快拥有数千或数万个流。
这是高基数。 这可以杀死洛基。
当我们谈论基数时,我们指的是标签和值的组合以及它们创建的流的数量。 高基数使用具有大范围可能值的标签,例如 ip,或者组合许多标签,即使它们具有较小且有限的值集,例如使用 status_code 和 action。
高基数导致 Loki 建立一个巨大的索引(读:$$$$)并将数千个小块刷新到对象存储(读:慢)。 Loki 目前在该配置下的表现非常差,运行和使用的成本效益和乐趣将是最低的。
并行化的最佳 Loki 性能
现在您可能会问:如果使用大量标签或具有大量值的标签不好,我应该如何查询我的日志? 如果没有数据被索引,查询不会很慢吗?
当我们看到习惯于使用其他索引密集型解决方案的 Loki 用户时,他们似乎觉得有义务定义大量标签才能有效地查询他们的日志。 毕竟很多其他的日志记录解决方案都是关于索引的,这是普遍的思路。
在使用 Loki 时,您可能需要忘记您所知道的,看看如何通过并行化以不同方式解决问题。 Loki 的超能力是将查询分解成小块并并行分派它们,这样您就可以在短时间内查询大量日志数据。
这种蛮力方法可能听起来不太理想,但让我解释一下为什么会这样。
大索引既复杂又昂贵。 日志数据的全文索引通常与日志数据本身大小相同或更大。 要查询你的日志数据,你需要加载这个索引,为了性能,它应该在内存中。 这很难扩展,并且随着您摄取更多日志,您的索引会迅速变大。
现在让我们谈谈 Loki,其中的索引通常比您摄取的日志量小一个数量级。 因此,如果您在将流和流流失保持在最低限度方面做得很好,则与摄取的日志相比,索引增长非常缓慢。
Loki 将有效地保持您的静态成本尽可能低(索引大小和内存要求以及静态日志存储),并使查询性能成为您可以在运行时通过水平扩展来控制的东西。
要了解这是如何工作的,让我们回顾一下查询特定 IP 地址的访问日志数据的示例。 我们不想使用标签来存储 IP 地址。 相反,我们使用过滤器表达式来查询它:
{job="apache"} |= "11.11.11.11"
在幕后,Loki 将该查询分解为更小的部分(碎片),并为标签匹配的流打开每个块,并开始寻找该 IP 地址。
这些分片的大小和并行化的数量是可配置的,并且基于您提供的资源。 如果需要,您可以将分片间隔配置为 5 米,部署 20 个查询器,并在几秒钟内处理千兆字节的日志。 或者您可以发疯并提供 200 个查询器并处理数 TB 的日志!
较小的索引和并行暴力查询与较大/更快的全文索引之间的这种权衡使 Loki 能够比其他系统节省成本。 运行大型索引的成本和复杂性很高,而且通常是固定的——无论是否查询,您每天 24 小时都需要为此付费。文章来源:https://www.toymoban.com/news/detail-499940.html
这种设计的好处意味着您可以决定想要拥有多少查询能力,并且可以根据需要进行更改。 查询性能取决于您要花多少钱。 同时,数据被高度压缩并存储在 S3 和 GCS 等低成本对象存储中。 这将固定运营成本降至最低,同时仍然允许令人难以置信的快速查询能力。文章来源地址https://www.toymoban.com/news/detail-499940.html
到了这里,关于k8s日志收集组件 Grafana loki --- 理论篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!