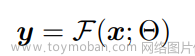前言
哈喽,各位小伙伴们大家好,说到AI绘画,可谓是近几年来异军突起,犹如洪水猛兽一般,各种的本土化,商业化。但是相信也有很多朋友跟我一样,对AI绘画的原理一知半解,甚至根本不知道它是怎么工作的。这样只靠着在网上复制粘贴别人的prompt,是没有点好处的,如果你是想用它来提高你的工作效率,提升产品质量,小编我认为,有必要好好了解一下SD的工作原理,于是乎,这篇文章就诞生了。
本文也是旨在以通俗易懂的语言,转述给大家讲解Stable Diffusion生成原理。
通过本文,你将掌握以下知识:
1 Stable Diffusion原理介绍
-
什么是扩散(Diffusion)?
-
扩散(Diffusion)是怎么能被稳定(Stable)控制的?(以文生图为例)
-
CLIP:我们输入的文字prompt是如何起作用的?
-
UNET:扩散模型的工作原理
-
理解VAE的编解码过程
Stable Diffusion原理介绍
1.什么是扩散(Diffusion)?
首先,大家要明确一点的是,我们常说的什么Stable Diffusion,它的本质上其实是一种算法,而我们通过Stable Difuusion web UI在浏览器上打开的页面,其实就是stable diffusion的可视化界面,说的简单一点可以理解为部署在本地的应用,它消耗你当前设备的算力,通过算法降噪和加噪的操作。
Stable Diffusion的中文直译又称稳定扩散算法。在图像领域中,扩散算法是通过一定规则去噪(反向扩散)或加噪(正向扩散)的过程。
如下图演示的就是以prompt为a red flower做扩散的过程,我们可以从SD的工作流程中清楚的看到,从最开始的灰色噪点块、逐渐去噪到最终的清晰的整个过程:

2.扩散(Diffusion)是怎么能被稳定(Stable)控制的?
这里以文生图为例,给大家看一下Stable Diffusion的原理:
我们把SD抽象理解为一个大函数Fsd(prompt),即:
我们输入一段自然语义prompt,经过一系列函数运算和变化,最终输出得到的一张图片的过程。

3.CLIP-prompt生效的关键算法
在实际使用SD时,我们往往会选择文生图的模式去达到,生产出符合我们预期的产品。那么,在我们输入了一串prompt后,这段prompt是如何起作用的呢?
CLIP,让我们输入的prompt起作用的关键算法。它是Text Encoder算法的一种,Text Encoder从字面意思理解:是把文字转化为代码的一种算法,他的主要功能是把自然语义prompt转变为词特性向量(Embedding)。
举个例子,我在生成一张图片时输入了一串prompt:cute girl ,CLIP算法作自然语义处理的时候会根据之前被程序员调试了成百上千的训练,罗列出cute girl可能具有的哪些特征,通过不断地去噪从而得到一张符合语义的图片。
比如他们可能有big eyes,可能有Sonw white skin等等,然后这些可能得特征被转化为77个等长的token词向量,每个向量(Embedding)包含768个维度。

话到这里,可能会有小伙伴问了,同样的prompt,为什么你生成的图片就好看一些,我的生成出来就很丑很模糊?那是因为,当我们输入同一个prompt,我们的text encoder过程是一样,也就是你得到的词向量是一致的,但是后面的去噪算法依赖模型不同,生成的效果千差万别。
那么接下来我们来讲一下SD里非常重要的UNET算法。
4.UNET-扩散模型的工作原理
UNET,是一种根据词向量的扩散算法,他的工作原理如下图所示,在上面说到的CLIP算法会根据我们输入的prompt输出对应机器能识别的词向量(Embedding),这个Embedding也可以理解为一个函数,里面包含(Q、K、V)三个参数就好了。
这三个参数会根据我们输入的对应扩散步长,作用于UNET去噪算法的每一步,比如下图中,我设置了去噪步长为20步,可以很清楚的看到这张图逐渐扩散生成的效果。

这里需要注意的是,UNET去噪的时候,原理比上图描述的复杂很多,我们在实际操作SD生成产品时,往往关注它的出图时间会主观上认为,SD是一步一步去噪,就能得到对应效果的,这个观点是错误的。
有一点必须要知道,如果SD的工作原理仅仅是一步一步的去噪的话,效果往往是达到不到我们所看到的效果的,并不能精确得到描述文本的图片。
所以在这里我会稍微深入一些(注意,这里是参考了国外论坛上网友的说法以及官方文档),介绍一下Classifier Free Guidance引导方法:
为了保证我们出图的最终质量,保证prompt最终的精确性。在UNET分步去噪的时候,假设我设置的去噪步长为20,他会在每一步都生成一个有prompt特征引导的图和一个没有prompt特征引导的图,两者相减,就得到了每一个去噪步骤中单纯由文字引导的特征信号,然后将这个特征信号大很多倍,这就加强了文本引导。同时,在第N+1步去噪结束后,它还会用第N+1步去噪的信息特征减去第N部的特征,然后继续方法很多倍,这样保证prompt在每一步都能有足够权重比参与运算。
上面那一段大家看不懂也没关系,直白来说,就是用了上面提到的这个方法加强了prompt的权重。这个方法在Stable Diffusion web UI中也被直译为提示词相关性,也就是CFG,是一个常用参数,他的数值决定了生成的图与提示词的相关程度。

以上就是文生图的内容了。
下面我粗略的介绍一下图生图,我们在使用Stable Diffusion web UI的时候用图生图的功能,往往是给一张图,然后再输入一段prompt,假如这里将扩散步数还是设置成N=20,这时候,它的原理是先把我们提供的图进行逐步加噪,逐步提取图片信息,使它变成一张完全的噪点图,再让prompt起作用,结合上面的UNET算法逐步去噪,得到既有素材图片特征也有prompt特征的最终效果图。
5.理解VAE的编解码过程
最后我们简单来理解一下VAE编解码的过程,VAE全称变分自编码器,这里大家不需要做太多理解,只需要知道他是一个先压缩后解压的算法就好了。需要注意的是,我们上面写的UNET算法不是直接在图片上进行的,而是在”负空间“进行的,大家理解为在代码层面即可。
VAE的原理如下图所示,

假如我们要生成的图是512x512的,VAE算法在一开始的时候,会把它压缩到八分之一,变成64x64,然后采用在全流程中走到UNET算法的时候,会把图形数据带在噪点图中,这个过程叫Encoder,然后再走完UNET算法后,我们得到了一个带有所有图片特征的噪点图,此时VAE再进行Decoder过程,把这张图解析并放大成512x512。文章来源:https://www.toymoban.com/news/detail-500031.html
好了,以上就是SD的全部工作原理了,觉得文章对你有帮助不妨点个关注吧,后续我也会持续跟进和分享其他跟AI绘画有关的文章。文章来源地址https://www.toymoban.com/news/detail-500031.html
到了这里,关于超详细,AI绘画里你不得不知道的SD算法详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!