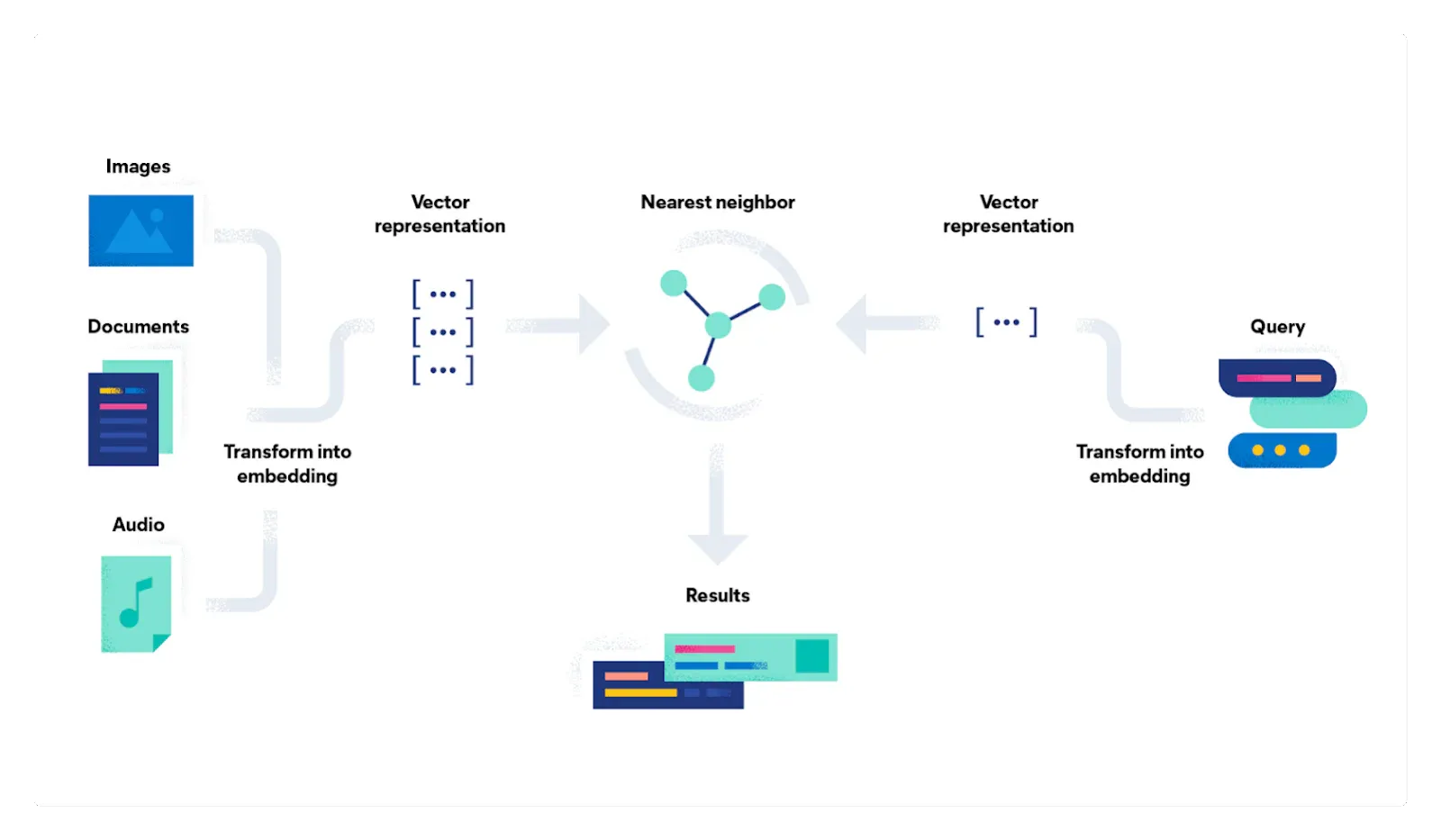
Elastic Learned Sparse EncodeR(或 ELSER)是一种由 Elastic 训练的 NLP 模型,使你能够使用稀疏向量表示来执行语义搜索。 语义搜索不是根据搜索词进行字面匹配,而是根据搜索查询的意图和上下文含义检索结果。


本教程中的说明向你展示了如何使用 ELSER 对数据执行语义搜索。
提示:在使用 ELSER v1 进行语义搜索期间,仅考虑每个字段的前 512 个提取的标记。 有关详细信息,请参阅此页面。
要求
要使用 ELSER 执行语义搜索,你必须在集群中部署 NLP 模型。 请参阅 ELSER 文档以了解如何下载和部署模型。
创建索引映射
首先,必须创建目标索引的映射 —— 包含模型根据你的文本创建的标记的索引。 目标索引必须有一个具有 rank_features 字段类型的字段来索引 ELSER 输出。
PUT my-index
{
"mappings": {
"properties": {
"ml.tokens": {
"type": "rank_features"
},
"text_field": {
"type": "text"
}
}
}
}注意:
- 包含预测的字段是 rank_features 字段。
- 用于创建稀疏向量表示的 text 字段。
有关 rank_features 字段的使用,请详细阅读文章 “Elasticsearch:Rank feature query - 排名功能查询”。
使用推理处理器创建摄取管道
创建一个带有推理处理器的摄取管道,以使用 ELSER 对管道中摄取的数据进行推理。
PUT _ingest/pipeline/elser-v1-test
{
"processors": [
{
"inference": {
"model_id": ".elser_model_1",
"target_field": "ml",
"field_map": {
"text": "text_field"
},
"inference_config": {
"text_expansion": {
"results_field": "tokens"
}
}
}
}
]
}text_expansion 推理类型需要在推理摄取处理器中使用。
加载数据
在此步骤中,你将加载稍后在推理摄取管道中使用的数据,以从中提取 token。
使用 msmarco-passagetest2019-top1000 数据集,它是 MS MACRO Passage Ranking 数据集的子集。 它包含 200 个查询,每个查询都附有相关文本段落的列表。 所有独特的段落及其 ID 都已从该数据集中提取并编译成一个 tsv 文件。
使用机器学习 UI 中的数据可视化工具下载文件并将其上传到你的集群。 将名称 id 分配给第一列,将 text 分配给第二列。 索引名称是 test-data。 上传完成后,n你可以看到一个名为 test-data 的索引,其中包含 182469 个文档。
关于如何加载这个数据,请详细阅读文章 “Elasticsearch:如何部署 NLP:文本嵌入和向量搜索”。


通过推理摄取管道摄取数据
通过使用 ELSER 作为推理模型的推理管道重新索引数据,从文本创建 tokens。
POST _reindex?wait_for_completion=false
{
"source": {
"index": "test-data"
},
"dest": {
"index": "my-index",
"pipeline": "elser-v1-test"
}
}该调用返回一个任务 ID 以监控进度:
GET _tasks/<task_id>你还可以打开经过训练的模型 UI,选择 ELSER 下的 Pipelines 选项卡以跟踪进度。 完成该过程可能需要几分钟时间。


我们通过如下的命令来查看被写入的文档:
GET my-index/_search
使用 text_expansion 查询进行语义搜索
要执行语义搜索,请使用 text_expansion 查询,并提供查询文本和 ELSER 模型 ID。 下面的示例使用查询文本 “How to avoid muscle soreness after running?”:
GET my-index/_search
{
"query":{
"text_expansion":{
"ml.tokens":{
"model_id":".elser_model_1",
"model_text":"How to avoid muscle soreness after running?"
}
}
}
}上面搜索的结果是:


结果是根据相关性排序的 my-index 索引中与你的查询文本含义最接近的前 10 个文档。 结果还包含为每个相关搜索结果提取的 token 及其权重。
"hits":[
{
"_index":"my-index",
"_id":"978UAYgBKCQMet06sLEy",
"_score":18.612831,
"_ignored":[
"text.keyword"
],
"_source":{
"id":7361587,
"text":"For example, if you go for a run, you will mostly use the muscles in your lower body. Give yourself 2 days to rest those muscles so they have a chance to heal before you exercise them again. Not giving your muscles enough time to rest can cause muscle damage, rather than muscle development.",
"ml":{
"tokens":{
"muscular":0.075696334,
"mostly":0.52380747,
"practice":0.23430172,
"rehab":0.3673556,
"cycling":0.13947526,
"your":0.35725075,
"years":0.69484913,
"soon":0.005317828,
"leg":0.41748235,
"fatigue":0.3157955,
"rehabilitation":0.13636169,
"muscles":1.302141,
"exercises":0.36694175,
(...)
},
"model_id":".elser_model_1"
}
}
},
(...)
]将语义搜索与其他查询相结合
你可以将 text_expansion 与复合查询中的其他查询结合使用。 例如,在布尔或全文查询中使用过滤器子句,可能会或可能不会使用与 text_expansion 查询相同的查询文本。 这使你能够合并来自两个查询的搜索结果。
来自 text_expansion 查询的搜索命中往往得分高于其他 Elasticsearch 查询。 这些分数可以通过使用 boost 参数增加或减少每个查询的相关性分数来规范化。 text_expansion 查询的召回率可能很高,因为相关性较低的结果很长。 使用 min_score 参数修剪那些不太相关的文档。
GET my-index/_search
{
"query": {
"bool": {
"should": [
{
"text_expansion": {
"ml.tokens": {
"model_text": "How to avoid muscle soreness after running?",
"model_id": ".elser_model_1",
"boost": 1
}
}
},
{
"query_string": {
"query": "toxins",
"boost": 4
}
}
]
}
},
"min_score": 10
} 文章来源:https://www.toymoban.com/news/detail-500101.html
文章来源:https://www.toymoban.com/news/detail-500101.html
说明:文章来源地址https://www.toymoban.com/news/detail-500101.html
- text_expansion 和 query_string 查询都在 bool 查询的 should 子句中。
- text_expansion 查询的提升值为 1,这是默认值。 这意味着该查询结果的相关性分数没有提高。
- query_string 查询的提升值为 4。 此查询结果的相关性分数增加,导致它们在搜索结果中排名更高。
- 仅显示分数等于或高于 10 的结果。
到了这里,关于Elasticsearch:使用 ELSER 进行语义搜索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!