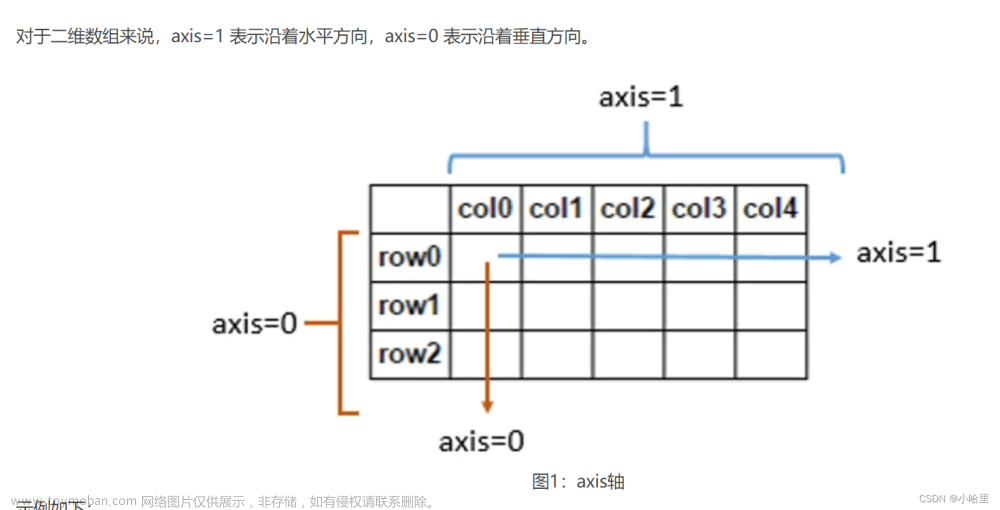
上一篇介绍的通用计算是关于多个numpy数组的计算,
本篇介绍的聚合计算一般是针对单个数据集的各种统计结果,同样,使用聚合函数,也可以避免繁琐的循环语句的编写。
元素的和
数组中的元素求和也就是合计值。
调用方式
聚合计算有两种调用方式,一种是面向对象的方式,作为numpy数组对象的方法来调用:
import numpy as np
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[8 3 4]
[4 4 1]
[6 6 3]]
arr.sum()
#运行结果
39
另一种是函数式调用的方式:
import numpy as np
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[8 3 4]
[4 4 1]
[6 6 3]]
np.sum(arr)
#运行结果
39
下面演示各种聚合计算的方法时,都采用函数式调用的方式,不再一一赘述了。
整体统计
整体统计就是统计数组所有值的和。
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
np.sum(arr)
#运行结果:30
按维度统计
比如上面的二维数组,按维度统计就是按行或者列来统计,而不是把所有值加在一起。
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
#统计每列的合计值
np.sum(arr, axis=0)
#运行结果:array([ 8, 14, 8])
#统计每行的合计值
np.sum(arr, axis=1)
#运行结果:array([10, 12, 8])
元素的积
元素的积的聚合统计就是各个元素相乘的结果。
对应的函数是:np.prod
整体统计
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
np.prod(arr)
#运行结果:3240
按维度统计
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
#统计每列的聚合值
np.prod(arr, axis=0)
#运行结果:array([ 6, 54, 10])
#统计每行的聚合值
np.prod(arr, axis=1)
#运行结果:array([18, 18, 10])
元素的平均值和中位数
平均值对应的函数是:np.mean,中位数对应的函数是:np.median。
整体统计
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
#平均值
np.mean(arr)
#运行结果:3.33333333
#中位数
np.median(arr)
#运行结果:2.0
按维度统计
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
#按列统计平均值
np.mean(arr, axis=0)
#运行结果:array([2.66666667, 4.66666667, 2.66666667])
#按行统计平均值
np.mean(arr, axis=1)
#运行结果:array([3.33333333, 4. , 2.66666667])
#按列统计中位数
np.median(arr, axis=0)
#运行结果:array([1., 3., 2.])
#按行统计中位数
np.median(arr, axis=1)
#运行结果:array([3., 2., 2.])
元素的标准差和方差
标准差对应的函数是:np.std,方差对应的函数是:np.var。
整体统计
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
#标准差
np.std(arr)
#运行结果:2.6246692913372702
#方差
np.var(arr)
#运行结果:6.888888888888889
按维度统计
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
#按列统计标准差
np.std(arr, axis=0)
#运行结果:array([2.3570226 , 3.09120617, 1.69967317])
#按行统计标准差
np.std(arr, axis=1)
#运行结果:array([2.05480467, 3.55902608, 1.69967317])
#按列统计方差
np.var(arr, axis=0)
#运行结果:array([5.55555556, 9.55555556, 2.88888889])
#按行统计方差
np.var(arr, axis=1)
#运行结果:array([ 4.22222222, 12.66666667, 2.88888889])
最大值和最小值
最大值对应的函数是:np.max,最小值对应的函数是:np.min。
整体统计
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
#最大值
np.max(arr)
#运行结果:9
#最小值
np.min(arr)
#运行结果:1
按维度统计
arr = np.random.randint(1, 10, (3, 3))
print(arr)
#运行结果
[[6 3 1]
[1 9 2]
[1 2 5]]
#按列统计最大值
np.max(arr, axis=0)
#运行结果:array([6, 9, 5])
#按行统计最大值
np.max(arr, axis=1)
#运行结果:array([6, 9, 5])
#按列统计最小值
np.min(arr, axis=0)
#运行结果:array([1, 2, 1])
#按行统计最小值
np.min(arr, axis=1)
#运行结果:array([1, 1, 1])
总结回顾
本篇介绍了最常用的聚合计算函数,聚合计算通常用于对数据进行处理和分析,以及实现高级的数据分析算法。
除了上面介绍的聚合计算函数,还有:文章来源:https://www.toymoban.com/news/detail-500645.html
- cumsum():计算数组中所有元素的累积和。
- cumprod():计算数组中所有元素的累积乘积。
- argmin():计算数组中最小值的下标。
- argmax():计算数组中最大值的下标。
- ... ...
具体请参考官方文档。文章来源地址https://www.toymoban.com/news/detail-500645.html
到了这里,关于【numpy基础】--聚合计算的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!