论文笔记 | 谷歌 Soft Prompt Learning
ptuning -> Prefix-Tuning -> soft promt -> p tuning v2
"The Power of Scale for Parameter-Efficient Prompt Tuning" EMNLP 2021 Google Brain
人能理解的不一定是模型需要的,所以不如让模型自己训练所需的prompt。
External Links:
- 论文作者:Brian Lester, Rami Al-Rfou
- Google Blog: "Guiding Frozen Language Models with Learned Soft Prompts"
- Github Repo
- Jeff Dean 的推文
Motivation
As models become larger, storing and serving a tuned copy of the model for each downstream task becomes impractical.
- 基于prompt的大模型application范式非常有前景,但是hand-craft prompts费时费力,受长度限制,且不一定效果好。
- 因此提出tunable soft prompts,使用隐式的"learnable vectors"代替显式的"tokens"作为prompts。
- soft prompts相比于比离散的文本prompt,可以蕴含更质密的信息 (成千上万个examples)
Approach

Prompts are typically composed of a task description and/or several canonical examples. Prompt tuning only requires storing a small task-specific prompt for each task, and enables mixed-task inference using the original pretrained model
大致流程:
- 每个任务训练一个prompt vector
- prompt的初始化是从vocabulary embedding采样
- 初始化prompt
 as a fixed-length sequence of vectors (e.g., 20 tokens long), 然后和输入
as a fixed-length sequence of vectors (e.g., 20 tokens long), 然后和输入  拼接,交给模型。根据模型生成的内容
拼接,交给模型。根据模型生成的内容  计算loss,反向传播更新 prompt vectors,而不更新模型的参数。
计算loss,反向传播更新 prompt vectors,而不更新模型的参数。
一些小细节:
- 对T5的实验进行了特别设计:
- Span Corruption: T5原本的模型
- Span Corruption + Sentinel: 在prompt前加入sentinel,以适应T5的预训练模式
- LM Adaptation: 用语言模型对T5做了二次预训练
- JAX-based T5X framewok
- prompt的长度5~100
- 大学习率(0.3)
和Adapter Learning的区别:
Adapters modify the actual function that acts on the input representation, parameterized by the neural network, by allowing the rewriting of activations at any given layer. Prompt tuning modifies behavior by leaving the function fixed and adding new input representations that can affect how subsequent input is processed.
和前作们的区别:
- 把Prefix-Tuning的reparametrization去掉了,以及只在encoder的输入前放soft prompts
- 不使用P-tuning中prompt的穿插放置方式
Results
- Benchmark:SuperGLUE (8个NLU任务,没有生成类任务)
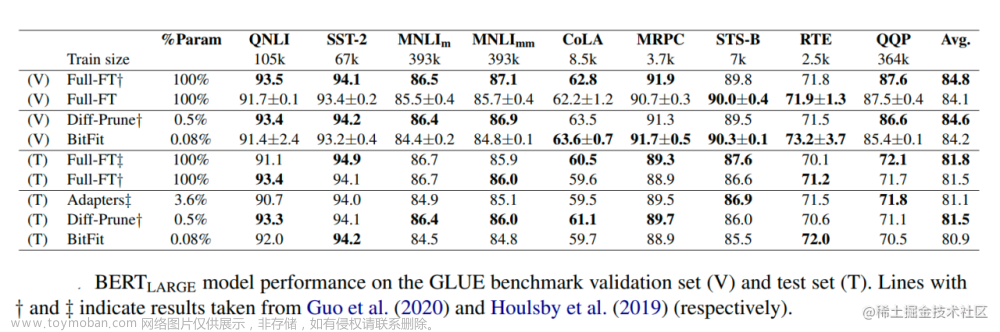
prompt tuning beats GPT-3 prompt design by a large margin, with prompt tuned T5-Small matching GPT-3 XL (over 16 times larger), and prompt-tuned T5-Large beating GPT-3 175B (over 220 times larger).

Prompt tuning比hand-craft prompts好,但在小模型上仍不如model tuning
- 消融实验:prompt长度在20就很好;用vocab sampled embedding初始化就很好;用LM objective预训练的模型更适合prompt learning

- 与prompt learning前作们相比,需要训练的参数更少

- prompt tuning相比model tuning,更不容易过拟合

在cross-domain数据集进行训练和zero-shot测试文章来源:https://www.toymoban.com/news/detail-500867.html
- 训练N种prompt表示,就可以做Prompt Ensembling(类似于bag of models),用来提高性能。
 文章来源地址https://www.toymoban.com/news/detail-500867.html
文章来源地址https://www.toymoban.com/news/detail-500867.html
- 通过分析prompt vector在embedding空间的近邻可以发现,学到的prompt和任务/数据集有很强的关联。
延伸阅读
- Prompt learning前作: Prefix Tuning, WARP, P-Tuning, soft words
- automatic prompt generation: Jiang et al., 2020; Shin et al., 2020
- Task Adaptors: Houlsby et al., 2019, MAD-X
- prompt tuning experiments in FLAN
- the BigScience T0 model
到了这里,关于论文笔记 | 谷歌 Soft Prompt Learning ,Prefix-Tuning的 -> soft promt -> p tuning v2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!