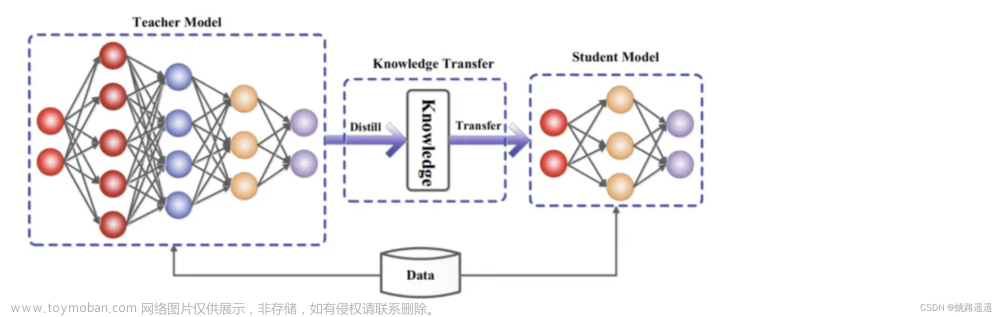
openai-cookbook/apps/enterprise-knowledge-retrieval at main · openai/openai-cookbook · GitHub
终于看到对于我解决现有问题的例子代码,对于企业私有知识库的集成。
我对"Retrieval"重新理解了一下,源自动词"retrieve",其基本含义是“取回”,“恢复”,或“检索”。在不同的上下文中,"retrieval"可以有稍微不同的含义。"Enterprise Knowledge Retrieval"中,"retrieval"指的就是从企业的知识库中查找和提取信息的过程。
GPT的很多应用需求和场景就是对企业自有知识库的问答、发掘、汇总、分析。这里openai提供了一个简单的例子。但现实的场景,企业知识还是很庞杂的,存储的方式多样、数量众多的拥有者,知识碎片化。要想做好内部的知识助理,或者面向客户的问答机器人,首先需要做好内部的知识管理,这个工作量还是很大的,管理成本也很高。说到这其实大家也不必太害怕,对于gpt应用如果我们专注于特定的场景,其实所需的知识库可能并不多,往往是几个文档就可以涵盖,这个时候做一些小的辅助工具就容易的多。
例子先可以看notebook,例子对一个集成知识库的过程和步骤做了完整的说明。下面是该过程的英文说明和翻译。个人觉得在存储上给了一个比较好的指导方向。
openai-cookbook/apps/enterprise-knowledge-retrieval/enterprise_knowledge_retrieval.ipynb at main · openai/openai-cookbook · GitHub
Enterprise Knowledge Retrieval
This notebook contains an end-to-end workflow to set up an Enterprise Knowledge Retrieval solution from scratch. 这个notebook代码包含了从头开始设置一个企业知识检索解决方案的端到端流程。
Problem Statement
LLMs have great conversational ability but their knowledge is general and often out of date. Relevant knowledge often exists, but is kept in disparate datestores that are hard to surface with current search solutions. 问题:大型语言模型(LLMs)具有很强的对话能力,但是它们的知识往往是通用的,且常常过时。相关的知识往往存在,但是存储在不同的数据仓库中,使用当前的搜索解决方案往往难以检索。
Objective
We want to deliver an outstanding user experience where the user is presented with the right knowledge when they need it in a clear and conversational way. To accomplish this we need an LLM-powered solution that knows our organizational context and data, that can retrieve the right knowledge when the user needs it.目标 我们希望能够提供出色的用户体验,当用户需要知识时,以清晰、对话的方式呈现正确的知识。为了实现这个目标,我们需要一个由大型语言模型(LLM)驱动的解决方案,它了解我们的组织背景和数据,能够在用户需要知识时检索到正确的知识。
Solution(解决方案)
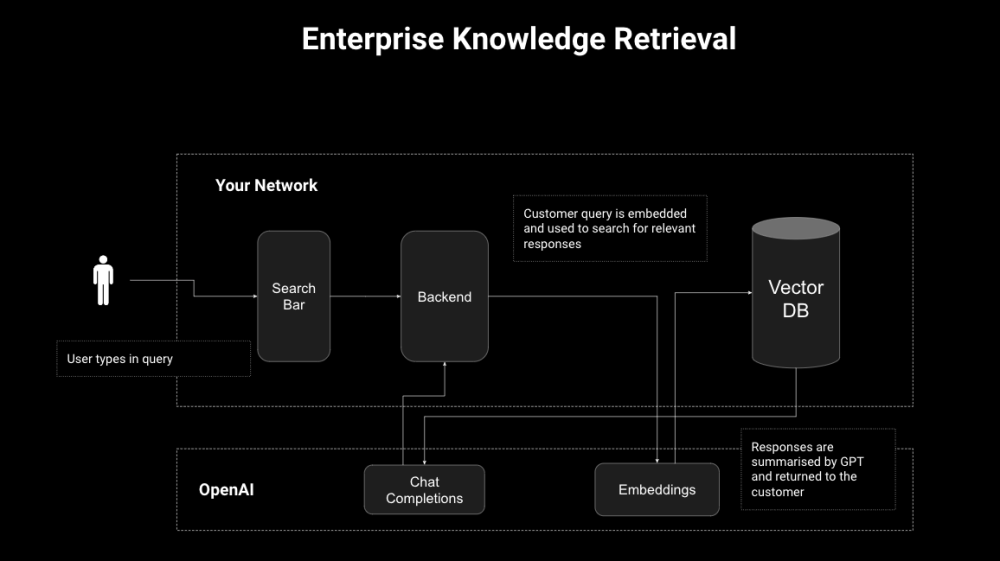
We'll build a knowledge retrieval solution that will embed a corpus of knowledge (in our case a database of Wikipedia manuals) and use it to answer user questions.我们将构建一个知识检索解决方案,该解决方案将嵌入一整套知识库(案例中,是一个维基百科手册的数据库wikipedia_articles_2000.csv),并用它来回答用户的问题。
Learning Path学习路径
Walkthrough演练
You can follow on to this solution walkthrough through either the video recorded here, or the text walkthrough below. We'll build out the solution in the following stages:可以通过下面的文本演练来继续此解决方案的演练
- Setup: Initiate variables and connect to a vector database.设置:初始化变量并连接到向量数据库
- Storage: Configure the database, prepare our data and store embeddings and metadata for retrieval.存储:配置数据库,准备我们的数据并存储用于检索的嵌入和元数据
- Search: Extract relevant documents back out with a basic search function and use an LLM to summarise results into a concise reply.搜索:使用基本的搜索功能提取出相关的文档,并使用LLM将结果总结为简洁的回复。
- Answer: Add a more sophisticated agent which will process the user's query and maintain a memory for follow-up questions.回答:添加一个更复杂的代理,该代理将处理用户的查询并为后续问题保留记忆。
- Evaluate: Take a sample evaluated question/answer pairs using our service and plot them to scope out remedial action.评估:对样本评估的问题/答案对进行采样并绘制它们以确定补救措施。
Storage(存储)
We'll initialise our vector database first. Which database you choose and how you store data in it is a key decision point, and we've collated a few principles to aid your decision here:
我们首先将初始化我们的向量数据库。你选择哪种数据库以及如何在其中存储数据是一个关键决策点,我们在这里汇总了一些原则来帮助你做出决策。”
How much data to store
How much metadata do you want to include in the index. Metadata can be used to filter your queries or to bring back more information upon retrieval for your application to use, but larger indices will be slower so there is a trade-off.“需要存储多少数据\n你希望在索引中包含多少元数据。元数据可以用来过滤你的查询,或者在检索时获取更多信息供你的应用程序使用,但是较大的索引会更慢,所以这里存在一个权衡。”
There are two common design patterns here:
这里有两种常见的设计模式:
- All-in-one: Store your metadata with the vector embeddings so you perform semantic search and retrieval on the same database. This is easier to setup and run, but can run into scaling issues when your index grows.全包式(All-in-one):将元数据与向量嵌入一起存储,以便在同一个数据库上执行语义搜索和检索。这种模式更容易设置和运行,但当索引增长时可能会遇到扩展性问题。
- Vectors only: Store just the embeddings and any IDs/references needed to locate the metadata that goes with the vector in a different database or location. In this pattern the vector database is only used to locate the most relevant IDs, then those are looked up from a different database. This can be more scalable if your vector database is going to be extremely large, or if you have large volumes of metadata with each vector.仅向量(Vectors only):仅存储嵌入向量以及用于定位与向量相关的元数据的任何ID/引用,存储在不同的数据库或位置。在这种模式中,向量数据库仅用于定位最相关的ID,然后从不同的数据库中查找这些ID。如果您的向量数据库将非常庞大,或者每个向量都有大量元数据,那么这种模式可能更具扩展性。
Which vector database to use(使用向量数据库)
The vector database market is wide and varied, so we won't recommend one over the other. For a few options you can review this cookbook and the sub-folders, which have examples supplied by many of the vector database providers in the market.
We're going to use Redis as our database for both document contents and the vector embeddings. You will need the full Redis Stack to enable use of Redisearch, which is the module that allows semantic search - more detail is in the docs for Redis Stack.
To set this up locally, you will need to:
- Install an appropriate version of Docker for your OS
- Ensure Docker is running i.e. by running
docker run hello-world - Run the following command:
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latest.
The code used here draws heavily on this repo.
After setting up the Docker instance of Redis Stack, you can follow the below instructions to initiate a Redis connection and create a Hierarchical Navigable Small World (HNSW) index for semantic search.
这段不翻译了,主要意思是例子使用了redis-stack,redis的一个增强版本做向量数据库,按照要求启动向量数据库。
Data preparation数据准备
The next step is to prepare your data. There are a few decisions to keep in mind here(对于数据准备,有一些需要注意的决策):
Chunking your data
In this context, "chunking" means cutting up the text into reasonable sizes so that the content will fit into the context length of the language model you choose. If your data is small enough or your LLM has a large enough context limit then you can proceed with no chunking, but in many cases you'll need to chunk your data. I'll share two main design patterns here:在这个语境中,“切分”意味着将文本切成合理的大小,以便内容能够适应你选择的语言模型的上下文长度。如果数据足够小或者LLM的上下文限制足够大,那么可以不进行切分,但在许多情况下,需要切分数据。
- Token-based: Chunking your data based on some common token threshold i.e. 300, 500, 1000 depending on your use case. This approach works best with a grid-search evaluation to decide the optimal chunking logic over a set of evaluation questions. Variables to consider are whether chunks have overlaps, and whether you extend or truncate a section to keep full sentences and paragraphs together.基于令牌的:根据一些常见的令牌阈值(例如300,500,1000等)来切分数据,这取决于用例。这种方法最适合通过一组评估问题进行网格搜索评估来决定最优的切分逻辑。需要考虑的变量是切分是否有重叠,以及为了保持完整的句子和段落在一起,你是否扩展或截断一个部分。
- Deterministic: Deterministic chunking uses some common delimiter, like a page break, paragraph end, section header etc. to chunk. This can work well if you have data of reasonable uniform structure, or if you can use GPT to help annotate the data first so you can guarantee common delimiters. However, it can be difficult to handle your chunks when you stuff them into the prompt given you need to cater for many different lengths of content, so consider that in your application design.确定性的:确定性切分使用一些常见的分隔符,如页面分隔,段落结束,节标题等进行切分。如果你的数据结构合理统一,或者你可以使用GPT先对数据进行注释,以便你可以保证常见的分隔符,那么这种方法可能会很好用。然而,当你把切分的内容塞入提示时,可能会很难处理,因为你需要适应许多不同长度的内容,所以在你的应用设计中要考虑这一点。 你应该存储哪些向量
Which vectors should you store
It is critical to think through the user experience you're building towards because this will inform both the number and content of your vectors. Here are two example use cases that show how these can pan out:思考你正在构建的用户体验是非常关键的,因为这将决定你的向量的数量和内容。这里有两个示例用例,展示了这些情况可能如何发展:
-
Tool Manual Knowledge Base: We have a database of manuals that our customers want to search over. For this use case, we want a vector to allow the user to identify the right manual, before searching a different set of vectors to interrogate the content of the manual to avoid any cross-pollination of similar content between different manuals.工具手册知识库:我们有一个我们的客户想要搜索的手册数据库。对于这个用例,我们想要一个向量让用户识别出正确的手册,然后搜索另一组向量来查询手册的内容,以避免不同手册之间的相似内容交叉污染。
- Title Vector: Could include title, author name, brand and abstract.标题向量:可以包括标题,作者名字,品牌和摘要。
- Content Vector: Includes content only.内容向量:只包括内容。
-
Investor Reports: We have a database of investor reports that contain financial information about public companies. I want relevant snippets pulled out and summarised so I can decide how to invest. In this instance we want one set of content vectors, so that the retrieval can pull multiple entries on a company or industry, and summarise them to form a composite analysis.投资者报告:我们有一个包含公共公司财务信息的投资者报告数据库。我希望能拉出相关的片段并总结,以便我决定如何投资。在这种情况下,我们希望有一组内容向量,这样检索就可以提取一个公司或行业的多个条目,并将它们总结形成一个综合分析。
- Content Vector: Includes content only, or content supplemented by other features that improve search quality such as author, industry etc.内容向量:只包括内容,或者通过其他可以提高搜索质量的特征来补充内容,比如作者,行业等。
For this walkthrough we'll go with 1000 token-based chunking of text content with no overlap, and embed them with the article title included as a prefix.对于这段例子,将选择基于1000个令牌的文本内容切分,没有重叠,并将它们嵌入,文章标题作为前缀包含在内。
Search(搜索)
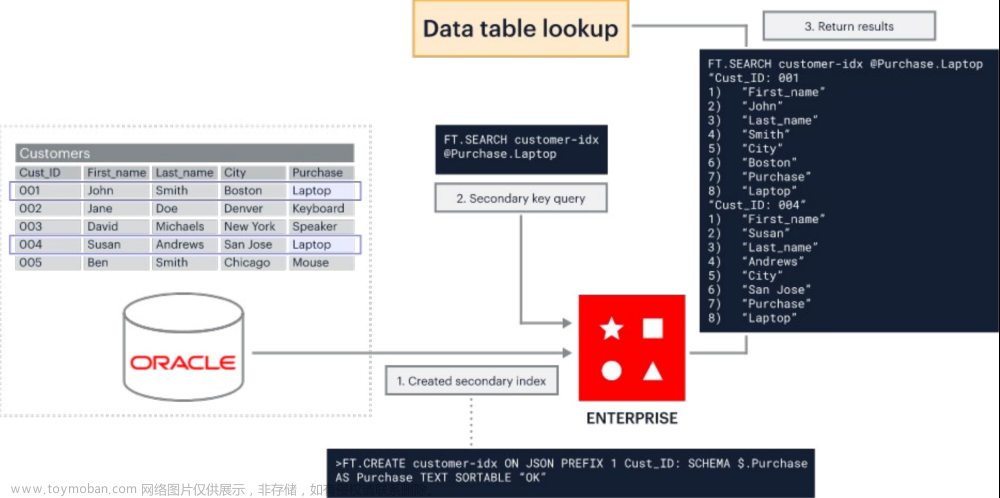
We can now use our knowledge base to bring back search results. This is one of the areas of highest friction in enterprise knowledge retrieval use cases, with the most common being that the system is not retrieving what you intuitively think are the most relevant documents. There are a few ways of tackling this - I'll share a few options here, as well as some resources to take your research further:现在可以使用我们的知识库来返回搜索结果。这是企业知识检索用例中摩擦最大的一个领域,最常见的问题是系统没有检索到你直观认为最相关的文档。有一些方法可以解决这个问题 - 在这里分享一些选项,以及一些资源来帮助使用者进一步研究:
Vector search, keyword search or a hybrid(向量搜索,关键词搜索或混合搜索)
Despite the strong capabilities out of the box that vector search gives, search is still not a solved problem, and there are well proven Lucene-based search solutions such Elasticsearch and Solr that use methods that work well for certain use cases, as well as the sparse vector methods of traditional NLP such as TF-IDF. If your retrieval is poor, the answer may be one of these in particular, or a combination:尽管向量搜索的开箱即用能力很强,但搜索仍然不是一个已经解决的问题,有一些经过良好验证的基于Lucene的搜索解决方案,如Elasticsearch和Solr,它们使用了在某些用例中表现良好的方法,以及传统NLP的稀疏向量方法,如TF-IDF。如果检索效果不好,你可以使用下面方法中的一种或者它们的组合来优化搜索效果:
- Vector search: Converts your text into vector embeddings which can be searched using KNN, SVM or some other model to return the most relevant results. This is the approach we take in this workbook, using a RediSearch vector DB which employs a KNN search under the hood.向量搜索:将你的文本转换成向量嵌入,可以使用KNN,SVM或其他一些模型进行搜索,返回最相关的结果。这是我们在这个工作簿中采取的方法,使用一个RediSearch向量数据库,它在底层使用了KNN搜索。
- Keyword search: This method uses any keyword-based search approach to return a score - it could use Elasticsearch/Solr out-of-the-box, or a TF-IDF approach like BM25.关键词搜索:这种方法使用任何基于关键词的搜索方法来返回一个分数 - 它可以使用开箱即用的Elasticsearch/Solr,或者像BM25那样的TF-IDF方法。
-
Hybrid search: This last approach is a mix of the two, where you produce both a vector search and keyword search result, before using an
alphabetween 0 and 1 to weight the outputs. There is a great example of this explained by the Weaviate team here.混合搜索:这最后一种方法是前两者的混合,你可以生成一个向量搜索结果和一个关键词搜索结果,然后使用一个0到1之间的alpha值来权衡输出。Weaviate团队在这里解释了这个方法的一个很好的例子。
Hypothetical Document Embeddings (HyDE)混合搜索
This is a novel approach from this paper, which states that a hypothetical answer to a question is more semantically similar to the real answer than the question is. In practice this means that your search would use GPT to generate a hypothetical answer, then embed that and use it for search. I've seen success with this both as a pure search, and as a retry step if the initial retrieval fails to retrieve relevant content. A simple example implementation is here:这最后一种方法是前两者的混合,你可以生成一个向量搜索结果和一个关键词搜索结果,然后使用一个0到1之间的alpha值来权衡输出。Weaviate团队在这里解释了这个方法的一个很好的例子。
def answer_question_hyde(question,prompt):
hyde_prompt = '''You are OracleGPT, an helpful expert who answers user questions to the best of their ability.
Provide a confident answer to their question. If you don't know the answer, make the best guess you can based on the context of the question.
User question: USER_QUESTION_HERE
Answer:'''
hypothetical_answer = openai.Completion.create(model=COMPLETIONS_MODEL,prompt=hyde_prompt.replace('USER_QUESTION_HERE',question))['choices'][0]['text']
search_results = get_redis_results(redis_client,hypothetical_answer)
return search_results
Fine-tuning embeddings微调嵌入
This next approach leverages the learning you gain from real question/answer pairs that your users will generate during the evaluation approach. It works by:
这个方法利用了你在评估过程中从真实的问题/答案对中获得的学习。它的工作方式是:
- Creating a dataset of positive (and optionally negative) question and answer pairs. Positive examples would be a correct retrieval to a question, while negative would be poor retrievals.
创建一个正面(可选负面)问题和答案对的数据集。正面的例子是一个问题的正确检索,而负面的例子是差的检索。 计算问题和答案的嵌入以及它们之间的余弦相似性。 训练一个模型来优化嵌入矩阵和测试检索,选择最好的一个。 将基础Ada嵌入矩阵与这个新的最好的矩阵进行矩阵乘法,创建一个新的用于检索的微调嵌入。 在这个烹饪书中有一个详细的微调嵌入方法和执行代码的演示。
- Calculating the embeddings for both questions and answers and the cosine similarity between them.计算问题和答案的嵌入以及它们之间的余弦相似性。
- Train a model to optimize the embeddings matrix and test retrieval, picking the best one.
Perform a matrix multiplication of the base Ada embeddings by this new best matrix, creating a new fine-tuned embedding to do for retrieval.训练一个模型来优化嵌入矩阵和测试检索,选择最好的一个。 将基础Ada嵌入矩阵与这个新的最好的矩阵进行矩阵乘法,创建一个新的用于检索的微调嵌入。
There is a great walkthrough of both the approach and the code to perform it in this cookbook.
对于这个演示,我们将坚持使用基础语义搜索,返回用户问题的前5个块,并使用GPT提供一个总结的回应。
Reranking重新排名
One other well-proven method from traditional search solutions that can be applied to any of the above approaches is reranking, where we over-fetch our search results, and then deterministically rerank based on a modifier or set of modifiers. 另一个从传统搜索解决方案中得到验证的方法是重新排列,我们可以对任何上述方法过度获取搜索结果,然后基于修饰符或一组修饰符确定性地重新排列。
An example is investor reports again - it is highly likely that if we have 3 reports on Apple, we'll want to make our investment decisions based on the latest one. In this instance a recency modifier could be applied to the vector scores to sort them, giving us the latest one on the top even if it is not the most semantically similar to our search question.一个例子是投资者报告 - 如果我们有3份关于Apple的报告,我们很可能希望根据最新的一份报告做出投资决策。在这种情况下,可以应用一个最近的修饰符来对向量分数进行排序,这样我们就可以得到最新的一份,即使它在语义上不是最接近我们搜索问题的。
For this walkthrough we'll stick with a basic semantic search bringing back the top 5 chunks for a user question, and providing a summarised response using GPT.在这个演示中,我们将坚持使用基础语义搜索,返回用户问题的前5个块,并使用GPT提供一个总结的回应。
对于notebook的示例,其中的一些说明对于私有知识库实践给了一个大方向的指导,但是感觉缺少实践的针对性,这个也可以理解,比较人家只提供平台,怎么用好其实是工程问题。后半部分稍微有点晦涩,需要多读几遍结合例子代码,希望以后能在实际项目上派上用处。
这个例子中的还有个chatbot例子,也是利用streamlit实现的。
在运行完notebook后,用文章来源:https://www.toymoban.com/news/detail-500939.html
streamlit run chatbot.py
启动页面。记住必须运行notebook做好数据的处理,否则chatbot没有数据无法正常工作。文章来源地址https://www.toymoban.com/news/detail-500939.html
到了这里,关于GPT学习笔记-Enterprise Knowledge Retrieval(企业知识检索)--私有知识库的集成的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!