1、完全分布式部署介绍
完全分部式是真正利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上。
2、nameNode HA+完全分布式部署
2.1、nameNode切换方法
分别处于Active和Standby中

hadoop可以创建多个副本到各个datanode中实现高可用,但是如果要防止出现问题必须给namenode做一个备用服务器。
HA的意思是High Availability高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用。
HA方式安装部署才是最常见的生产环境上的安装部署方式。Hadoop HA是Hadoop 2.x中新添加的特性,包括NameNode HA和 ResourceManager HA因为DataNode和NodeManager本身就是被设计为高可用的,所以不用对他们进行特殊的高可用处理。
服务器失效之后在故障转移域切换。

ZooKeeper-based election
如果本地NN是健康的,并且zkfc发现没有其他的NN持有那个独占锁。那么他将试图去获取该锁,一旦成功,那么它就需要执行Failover,然后成为active的NN节点。Failover的过程是:第一步,对之前的NN执行fence(栅栏),如果需要的话。第二步,将本地NN转换到active状本
ZooKeeper集群最好是3台及以上的奇数

作为一个ZK集群的客户端,用来监控NN的状态信息。每个运行NN的节点必须要运行一个zkfc。zkfc提供以下功能:
Health monitoring
zkfc定期对本地的NN发起health-check的命令,如果NN正确返回,那么这个NN被认为是OK的。否则被认为是失效节点。
ZooKeeper session management
当本地NN是健康的时候,zkfc将会在zk中持有一个session。如果本地NN又正好是active的,那么zkfc还有持有一个“ephemeral"的节点作为锁,一旦本地NN失效了,那么这个节点将会被自动删除。
2.2、 NameNode+HA数据共享方法
Namenode主要维护两个文件,一个是fsimage,一个是editlog。
fsimage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等,对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等
editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。

nameNode之间的数据共享是通过journalNode(保存的是editlog)
在Active Namenode与StandBy Namenode之间的绿色区域就是journalNode(日志节点),当然数量不一定只有1个,作用相当于NFS共享文件系统,Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步。日志节点其实是运行在各个dataNode中的。
两个NameNode为了数据同步,会通过一组称作journalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的journalNodes进程。stardby状态的NameNode有能力读取jNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态active状态意味着提供服务,standby状态意味着处于休眠状态,只进行数据同步,时刻准备着提供服务。
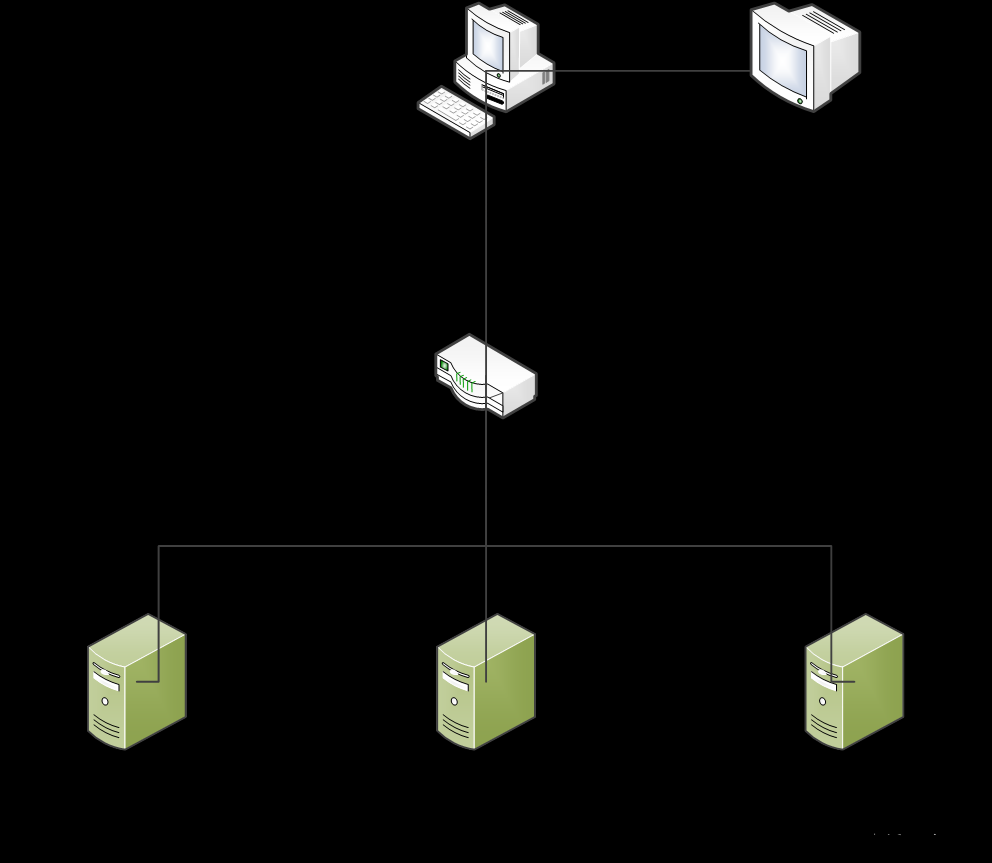
3、完全分布式部署规划

6台服务器的静态ip可以scp复制


不想写255.255.255.255可以换成PREFIX=24
如果需要让虚拟机上网,可以配置firewall

修改主机名 修改hosts 时间同步ntpdate

配置免密登录

私钥免密


用for循环拷贝ssh免密登录文件到其他主机2-6

3.1、jdk部署

rsync -av 增量传输,保证数据的一致性

for循环scp复制本地环境变量上传到hd2-6服务器
source /etc/profile
3.2、Zookeeper部署
3.2.1、zookeeper作用
ZooKeeper 是为分布式应用程序提供高性能协调服务的工具集合,译名为“动物园管理员”分布式应用程序可以基于它实现配置维护、命名服务、分布式同步、组服务等。是Hadoop集群管理的一个必不可少的模块,它主要用来解决分布式应用中经常遇到的数据管理问题,如集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等在ZooKeeper集群当中,集群中的服务器角色有两种Leader和Learner,Learner角色又分为Observer和Follower

Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Follower完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Follower具有相同的系统状态
3.2.2、部署软件包

每台服务器myid不同,需要分别修改,例如server.1对应的myid内容为1,server.2对应的myid内容为2,server.3对应的myid为3。
2888端口:follower连接到leader机器的端口
3888端口 :leader选举端口
还可以直接配置ip,在zoo.cfg文件末尾

在conf文件中的示例文件中可以看见tickTime滴答时间=2s 初始化限制时间=10次 20s
数据同步请求限制=5次 10秒
tickTime相当于校对时间参数

echo "1-3" > /opt/data/myid 三台服务器都必须输入myid内容
3.2.3、启动zookeeper
因为安装包是tar.gz的二进制包,所以启动必须在安装位置中的bin目录下。
可以把安装位置配置到环境变量就不用进入安装目录启动了

source /etc/profile
其他两台服务器直接scp拷贝环境变量过去即可
最后分别启动三台服务器之后查看状态可以看见Mode有两个跟随者和一个leader

3.3、安装hadoop
scp拷贝二进制hadoop安装包到6台服务器,tar xf解压之后mv 到/opt/hadoop
最后配置一下hadoop的环境变量就行

3.3.1、修改hadoop配置文件
1、hadoop-env.sh
[root@localhost ~]#vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
修hadoop-envsh 25行,mapred-env.sh 16行,yarn-env.sh 23行针对hadoop-2.8.5版本
2、core-site.xml
[root@localhost ~]#vim core-site.xml
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs .defaultFS</name>
<value>hdfs://nsl</value>
</property>
<!-- 指定hadoop临时目录(元数据) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hd4:2181,hd5:2181,hd6:2181</value>
</property>
3、hdfs-site.xml
[root@localhost ~]#vim hdfs-site.xml
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs .ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址,RPC是机器之间的通信方式 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<vaue>hd1:9000</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs .namenode.rpc-address,ns1,nn1</name>
<value>hd1:9000</value>
</property>
<!-- nn1的http通信地址,http是人和机器之间的通信方式 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hd1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address .ns1.nn2</name>
<value>hd2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs .namenode.http-address.ns1.nn2</name>
<value>hd2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位 -->
<property>
<name>dfs .namenodeshared.edits .dir</name><value>qjournal://hd4:8485;hd5:8485;hd6:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位号-->
<property>
<name>dfs .journalnode.editsdir</name>
<value>/opt/data/journa1</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover .enabled</name>
<value>true</value>
</property>
<!-- 配号失败自动切换实现方式 -->
<property>
<name>dfs.client.failover .proxy.provider .ns1</name>
<value>
org.apache. hadoop,hdfs , server ,namenode.ha,ConfiguredFailoverProxyProvider
</value>
</property>
<!--配置隔离机制 -->
<property>
<name>dfs .ha,fencing.methods</name>
<value>sshfence/value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs .ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
4、配置datanode节点记录文件 slaves
[root@localhost ~]#vim slaves
hd4
hd5
hd6
5、mapred-site.xml
[root@localhost ~]#cp /opt/hadoop285/etc/hadoop/mapred-site.xml.template /opt/hadoop285/etc/hadoop/mapred-site.xml
[root@localhost ~]#vim mapred-site.xml
<!-- 指定mr框架为yarn方式(mapreduce的资源调度方式) -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6、yarn-site.xml
[root@localhost ~]#vim yarn-site.xml
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager .hostname</name>
<value>hd3</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为洗牌shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.3.2、复制修改后的hadoop目录到所有集群节点

上传本地配置好的配置文件到所有集群 节点之后复制配置文件到hadoop目录替换之前的。

最后用for循环拷贝整个配置好的目录到其他节点
3.3.3、启动整个集群的步骤
在namenode节点启动zookeeper
[root@localhost ~]#zkServer .sh start
启动journalnode(在namenode上操作,例如hd1)

必须是daemons才可以同时启动整个集群的journalnode,jps在三个节点上验证
可以通过判断是否生成data文件来确认有没有启动journalnode,hd1不是集群的节点所以没有data
格式化hdfs文件系统(在namenode上操作,例如hd1)
[roothd1 ~]# hdfs namenode -format

拷贝到hd2之后两个节点的元数据信息完全一致
格式化zk(namenode上操作,例如hd1 ),格式化zookeeper的客户端zkfc,监控namenode的
[root@localhost ~]#hdfs zkfc -formatZK
启动hdfs(namenode上操作,例如hd1)
[root@localhost ~]#start-dfs.sh
启动yarn (namenode上操作,例如想让hd2成为resourcemanager,需要在hd2)
[root@localhost ~]#start-yarn.sh
启动yarn之后必须输入三次yes
访问
NameNode1:http://hd1:50070 查看NameNode状态
3.3.4、hadoop集群验证

创建一个测试的txt文件之后放入input文件夹中调用yarn的jar包中的wordcount方法计算输出结果到output中的00文件中
最后可以看到词频统计的结果

浏览器访问可以直接在linux服务器上的浏览器

后台启动浏览器的前提是在本地配置域名解析hosts文章来源:https://www.toymoban.com/news/detail-500973.html
 文章来源地址https://www.toymoban.com/news/detail-500973.html
文章来源地址https://www.toymoban.com/news/detail-500973.html
到了这里,关于大数据基础平台实施及运维进阶的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!