基础
自然语言处理(NLP)
自然语言处理PaddleNLP-词向量应用展示
自然语言处理(NLP)-前预训练时代的自监督学习
自然语言处理PaddleNLP-预训练语言模型及应用
自然语言处理PaddleNLP-文本语义相似度计算(ERNIE-Gram)
自然语言处理PaddleNLP-词法分析技术及其应用
自然语言处理PaddleNLP-快递单信息抽取
理解
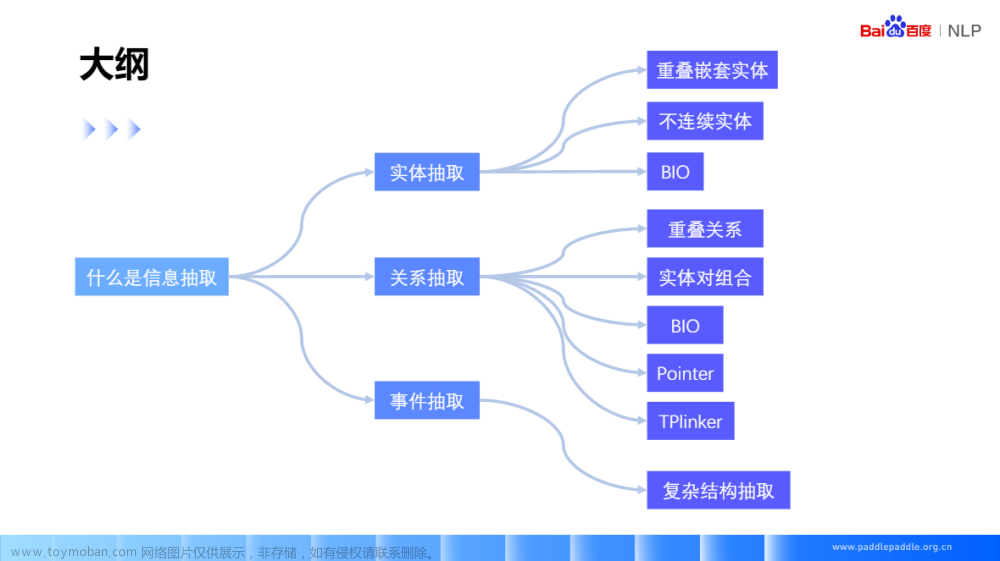
自然语言处理PaddleNLP-信息抽取技术及应用
自然语言处理PaddleNLP-基于预训练模型完成实体关系抽取--实践
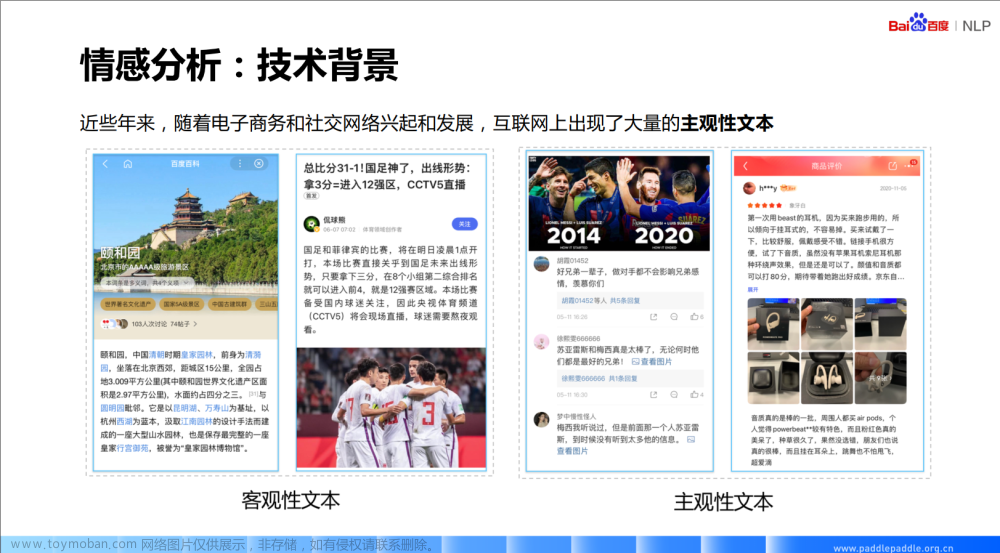
自然语言处理PaddleNLP-情感分析技术及应用-理论
自然语言处理PaddleNLP-情感分析技术及应用SKEP-实践
问答
自然语言处理PaddleNLP-检索式文本问答-理论
自然语言处理PaddleNLP-结构化数据问答-理论
翻译
自然语言处理PaddleNLP-文本翻译技术及应用-理论
自然语言处理PaddleNLP-机器同传技术及应用-理论
对话
自然语言处理PaddleNLP-任务式对话系统-理论
自然语言处理PaddleNLP-开放域对话系统-理论
产业实践
自然语言处理 Paddle NLP - 预训练模型产业实践课-理论
NLP问答任务
相似度和规则匹配,都是早期的方法,现在主流的方法,都是基于生成的方法
结构化数据问答,有两种形式,一种是知识图谱形式、一种是关系型数据库形式。
主要应用在企业中,减少销售的成本
应用于商业智能,用于报告生成,解放了财务能力,降低人力成本
结构化数据问答任务
结构化数据问答:基于给定的结构化知识库和自然语言问题,给出问题对应的答案
任务能力:
- 推理能力:基于现有知识推理/计算给出答案,E.g. OPPOA93比魅族18贵多少呀
- 输出结果可解释:输出知识库查询语句
结构化形式存储,不尽存储了问题的知识和答案,这种存储有利于推理和计算
结构化问答能够输出查询语句,是人类可读可理解的,相对于其它问答形式,这种是可控的。
表格问题中,一般用语义解析技术(Text-to-SQL)
表格问答:核心技术,将自然语言问题转成数据库上可执行的SQL查询语句
两大功能:
- SQL解析功能:比较关键,是表格问答的核心技术,如何将自然语言转成可查询的SQL语句
- SQL执行功能


评估方法
常用的有两种,这两种是不等价的。
- 精确匹配正确率:评估生成的SQL的正确率,预测SQL与标准SQL相等的问题占比
- 执行正确率:评估答案正确率,执行预测SQL获得正确答案的问题占比
分母是问题集合大小N,预测的SQL和标准的SQL相等的问题数量,在判断相等的时候会忽略顺序的影响
问题
这种方式和第一种相比,分子是通过答案相比,这两种方式是不等价的。
- 精确匹配正确率:针对同一个问题,有不同的SQL写法,而且SQL都是正确的,这种情况下。如果使用第一种评估方式,标准的SQL只是正确写法中的一个,使用这种方式会漏掉一些正确的结果。导致评估的结果会偏低,这种情况就比较适合使用第二种方式(评估答案准确率)
- 执行正确率:数据库的不完毕性,有些问题是没有答案的,这样的话,就导致正常的SQL没有答案,错误的SQL也没有答案,按答案判断两种情况都是正常的。这样会导致评估结果会偏高
在实际应用在选择评估方式时,
-
- 看选择的测试数据,提供了哪些信息,有没有提供SQL、答案,
-
- 实际应用更关注哪个指标,是关注SQL正常,还是更关注答案

数据集
一般是按数据集化分,要么问题在训练集中,要么在测试集中,多领域是按数据库划分的,在一个数据集中
-
多领域(cross-domain):训练/测试集使用的数据库是否相同或交叉,数据集是包含多个数据库的,每个数据库有一个领域,每个领域有一个或多个数据库,数据集划分时,是按训练集、测试集划分的。一个数据库所有的问题,只能属于一个集合,要么属于训练集,要么属于测试集。这会导致测试集中的数据库和问题,在训练集中是没有见过的。多领域化分,是用来划分模型的泛化性。同时也给任务带来很大的挑战
-
单/多表(multi-table):构成数据库的表的数量,多表涉及到表的检索,一张表为单表,涉及多张表的表示多表
-
简单/复杂:从SQL角度评估,是否包含高级从句、集合操作、嵌套等,简单 SQL只包含SELECT WHERE(答案、条件),复杂:有可能包含排序、分组、集合操作
CSpider 数据库是英文,问题是中文
主流学习方式
基于规则的方式,已经不用了,主流的有以下两种
-
有监督方法:以生成的SQL是否正确,来指导模型的学习,这种学习方法依赖于标准数据,由于正确的SQL语句标注比较困难
-
弱监督方法:给出数据库问题,以及问题对应的答案,标注答案要比标注SQL相对容易很多,在这情况下,SQL是中间输出,会以答案指导SQL的生成,能够输出正常答案的SQL就是正确的。这种需要在整个数据库中去搜索合理或正常的正确语句,搜索空间比较大。这种方式比较适合简单的数据集,复杂的数据集很难执行下去。
https://github.com/salesforce/WikiSQL
为了各类数据集都适用,后面都是基于有监督方法的介绍
encode-decoder 中英文翻译,中文句子翻译成英文句子,
encode 把中文句子映射到表示空间上,完成编码的作用
decode 从表示空间上,解码出对应的英文句子
从下往上看,把多输入进行拼接,自然语言和DB Schema 的拼接,将拼接输入给 Encoder 编码器,解码器按顺序输出每个元素,直到遇到结束符,最终生成序例(SQL语句)
Decode 引入了两个开关,generate、copy 多领域数据集在划分训练集和测试集时,是按数据库进行化分的,测试集中的一些问题在训练集中没有见过,如何在生成的时候把这些没有见过的生成出来。输出信息,应该包含在输入定义的 db schema 信息中,这时候就可以把定义的输入信息copy到输出信息中。
对于 SQL 关键词,是生成的,数据库和问题中的元素是copy的
Text-to-SQL任务挑战
领域泛化:测试集中数据库未在训练集中出现过
输出结构化:生成的SQL语句在数据库上可执行,即满足数据库结构、SQL语法

Text-to-SQL实例
解决方案
编码:Relation-awarerepresentation 利用匹配关系强化编码方式
解码:Grammar-baseddecoder 利用语法解码,保证生成的SQL是满足语法的
Encode => 隐式表示 => Decode
输入部分仍然是自然语言+Schema的拼接,在这边为了更好的识别条件值,增加了条件值的一个拼接,
使用基础的编码器,对数据进行一个表示,得到一个隐式表示,
在基础编码器上,又增加了一个 Relation-aware Transformer Encoder:用匹配关系增强表示,
接下来在Decode中引入了 Grammar-based Decoder 语法解码,这种解码不是在每次输出时输出一个个元素,而是输出的一个语法序列。
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_to_sql
SchemaLinking
自然语言和数据库Schema进行匹配映射,把匹配信息构成匹配关系矩阵,这个矩阵作为后面模块的输入,
先对自然语言进行分词
问题中的每个词与DB Schema中的成分进行匹配,标注出匹配方式和程度,构建出关系矩阵,颜色表示匹配关系,不同的颜色表示不同的关系
Encoding–BasicEncoder
- 基础编码:把输入映射到隐式空间的过程
Dataprocess:text2sql/dataproc/ernie_input_encoder_v2.py中类ErnieInputEncoderV2
Encoder:third/ERNIE或PaddleNLP:from paddlenlp.transformersimport BertModel
Encoding–Relation-awareEncoder
- 匹配关系增强编码:利用SchemaLinking 中建立起来的关系矩阵,来指导编码,进而强化编码,
学习输入中的每个词对目标词的权重,
输入自然语言和DB Schema进行拼接,
权重越大,对目标词的影响越大
1:08:40
Decoding
- 语法解码:解码过程种通过语法生成语法序列,保证语法的合理性
- 基于Copy机制的解码:对应的元素是数据库元素时,利用copy机制

Grammar-basedDecoder
基本思想:根据SQL语法设定上下文无关文法,将SQL生成看作文法序列生成,即文法选择过程
不再生成单独的 query元素,而是生成符合SQL语言的语法,最后生成的语法序列是可以构成 sql query的。
是经过领域泛化的,换一个库不需要重新标注,除非需要很高的准确率。
应用实例演示:https://ai.baidu.com/unit/v2#/innovationtec/kbqa/skilllist
视频:https://aistudio.baidu.com/aistudio/course/introduce/24177?sharedLesson=1477808&sharedType=2&sharedUserId=2631487&ts=1686638807733文章来源:https://www.toymoban.com/news/detail-501033.html
课件:https://aistudio.baidu.com/aistudio/course/introduce/24177?sharedLesson=1567910&sharedType=2&sharedUserId=2631487&ts=1686638791675文章来源地址https://www.toymoban.com/news/detail-501033.html
到了这里,关于自然语言处理 Paddle NLP - 结构化数据问答-理论的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!