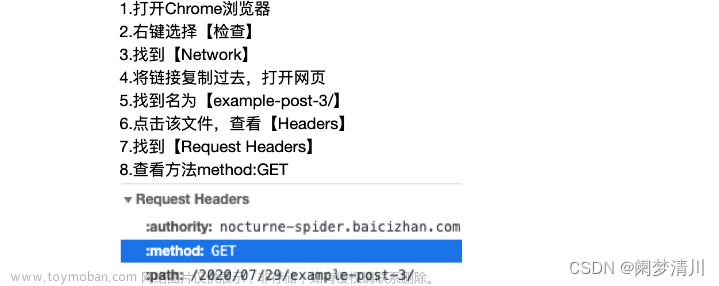
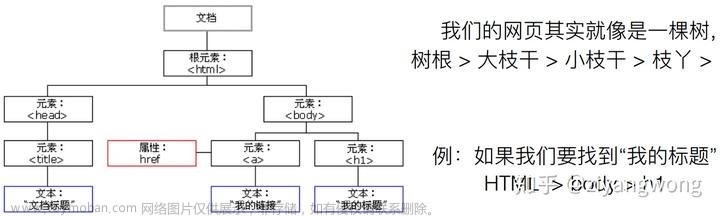
一、安装 requests 模块
pip install requests
二、发送请求,获取json字符串响应
爬取接口示例,这里以 Get 请求为例,这里请求的接口会返回一个 JSON 字符串。
import requests
import json
url = 'https://blog.csdn.net/community/home-api/v1/get-business-list'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
data = {
"page": "1",
"size": "20",
"businessType": "lately",
"noMore": "false",
"username": "qq_33697094"
}
# 发送get请求(如果是post请求,使用requests.post)
result = requests.get(url, headers=headers, params=data)
# 使用 result.content.decode 获取该接口返回的json字符串或者html页面为
responseStr = result.content.decode('utf-8')
# 将接口返回的json字符转为字典
dic = json.loads(responseStr)
titles = []
for item in dic["data"]["list"]:
titles.append(item["title"])
print(titles)
若接口返回的是 json 字符串,也可以像下面这样,直接使用 result.json() 接收接口返回的数据为字典。
# 发送请求
result = requests.get(url, headers=headers, params=data)
# 获取结果为字典(json对象)
dic = result.json()
三、发送请求,获取 html 网页并解析获取文本
上面的示例是发送一个请求,该请求返回的一个json字符串。有时候我们是想获取某个网址链接页面下的数据,比如某个 ur l 它返回的不是一个json字符串,它是由多个请求和数据组成的一个网页,这个时候可以使用 BeautifulSoup 或 lxml 库去解析 html 然后获取想要的数据。
BeautifulSoup 和 lxml 库都是解析 html 的库,lxml 解析器更加强大,速度更快,它可以方便的解析 html 和 xml ,推荐使用 lxml 解析器。
安装 lxml 模块
pip install lxml
从返回的 html 解析数据示例
import requests
from lxml import html
url = 'https://blog.csdn.net/qq_33697094?type=lately'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
# 发送请求
result = requests.get(url, headers=headers)
# 获取该接口返回的 html 页面并格式化
tree = html.fromstring(result.text)
# 获取 <div class='blog-list-box-top'的 div 标签下 h4 标签里的文本
titles = tree.xpath("//div[@class='blog-list-box-top']/h4/text()")
# 获取 class属性是'blog-list-box'的article 标签下 a 标签里的 href 属性
urls = tree.xpath("//article[@class='blog-list-box']/a/@href")
print(titles)
print(urls)
上面是使用 xpath 去定位 html 的元素,关于 xpath 的语法和使用你可以参考如下文章:文章来源:https://www.toymoban.com/news/detail-501131.html
lxml库与Xpath提取网页数据
lxml库的基本使用
Selenium 中的 XPath
selenium 定位元素
XPath in Selenium: How to Find & Write
How to use XPath in Selenium文章来源地址https://www.toymoban.com/news/detail-501131.html
到了这里,关于python 爬虫入门示例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!