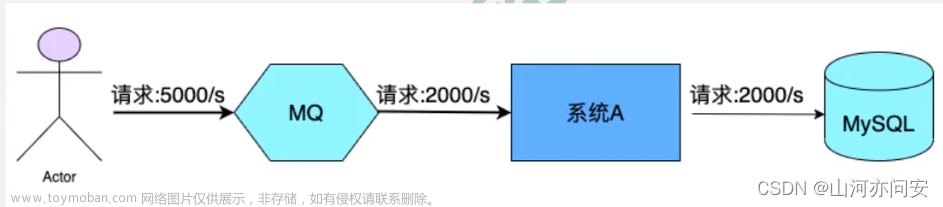
什么是消息队列
在分布式系统中,不同模块之间需要通信和交换信息。但是传统的通信方法(如 HTTP)会带来一些问题:耦合性高,反应慢,并且无法容忍荷载瞬间增大的情况。这时候,消息队列就能充分发挥它的优势了。
消息队列是指一种相对于本地数据存储设备而言更强调异步、解耦、流控和削峰的技术方案。基于消息队列机制,可以轻松地实现不同程序之间的异步消息传递,从而降低了程序的耦合度,同时还能够在一定程度上保证程序的稳定性和可靠性,提升了整个系统的性能。
为什么使用 RabbitMQ
RabbitMQ 是开源的消息代理软件,采用了 Erlang 语言实现,具有以下几个优点:
-
可扩展性好:由于 RabbitMQ 是纯 Erlang 实现,拥有很高的并发处理能力,支持每秒钟数百万条消息的处理。因此,RabbitMQ 具有很好的可扩展性。
-
支持多种协议:RabbitMQ 支持 AMQP 协议、STOMP 协议等,同时还兼容 MQTT 协议等。
-
提供了各种功能:RabbitMQ 提供了如消息持久化、高可用性、HA 模式等多种功能,支持负载均衡、断线重连机制等。
-
易于使用和配置:RabbitMQ 功能齐全,同时又相对简单。Python 提供了许多 RabbitMQ 的客户端库(如 Puka,Py-AMQP 和 Kombu 等),可以轻松地在 Python 中使用 RabbitMQ。
RabbitMQ 主要概念
在使用 RabbitMQ 之前,需要先了解一些基础概念。
Message Broker
Message Broker 是指消息代理,它是实现消息传递、路由和转换的中间件软件,位于生产者和消费者之间。
Producer
Producer 是指消息的发布者,将消息发送到 Exchange。
Exchange
Exchange 负责接收来自 Producer 发送的消息并根据消息类型选择一个或多个合适的 Queue 投递给 Consumer。
Queue
Queue 是存储消息的队列,它是 Consumer 处理消息的“容器”。
Routing Key
Routing Key 是通过 Xchange 将 Message 路由到具体的 Queue 所必须的参数。
Consumer
Consumer 是消息的接收者,负责从指定的 Queue 或订阅的主题订阅消息并进行处理。
如何使用 RabbitMQ
现在,我们来尝试使用 Python 中的 Pika 库和 RabbitMQ 实现一个简单的消息队列生产者和消费者。在本例中,我们将使用默认设置(即使用虚拟主机/主机名 localhost)。首先,确保你已经安装了 Pika 库:
$ pip install pika
生产者
import pika
def main():
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
if __name__ == '__main__':
main()
以上代码做了如下的事情:
-
创建了一个与 RabbitMQ 服务器建立连接的 BlockingConnection。连接到主机名为
localhost,也就是默认设置。 -
通过 Channel 宣告了一个 Queue。如果 Queue 不存在则会被创建。
-
发送了一条消息。通过调用 basic_publish 将消息发布到指定的 Exchange,该 Exchange 会将消息推送给相应的 Queue。
-
关闭连接。最后一定要关闭连接。
消费者
import pika
def callback(ch, method, properties, body):
print("Received %r" % body)
def main():
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_consume(queue='hello',
on_message_callback=callback,
auto_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
if __name__ == '__main__':
main()
以上代码做了如下的事情:
-
创建一个与 RabbitMQ 服务器建立连接的 BlockingConnection,并获得一个 Channel 对象。
-
使用
queue_declare()定义了一个名称为hello的 Queue。 -
将这个 Queue 绑定到 default 的 Exchange 上去。default 的 Exchange 会从消息的 Routing Key 中解析出来相应的 Queue 进行消息推送。
-
通过
basic_consume()阻塞当前进程,等待消息。 -
当有消息到达时回调函数
callback()会被触发,将消息打印出来。 -
最后关闭 Connection 和 Channel。确保 Pika 已经把所有信息发送给了 RabbitMQ Server,否则会影响 RabbitMQ Server 因为TCP连接的最大文件接收大小。
你可以使用以下命令运行生产者和消费者:
$ python producer.py
$ python consumer.py
输出将会是:
Producer:
[x] Sent 'Hello World!'
Consumer:文章来源:https://www.toymoban.com/news/detail-501168.html
[*] Waiting for messages. To exit press CTRL+C
Received b'Hello World!'
总结
RabbitMQ 是一款功能强大、易于使用的消息队列软件。在本文中,我们简单地介绍了消息队列的概念及 RabbitMQ 的工作原理与主要概念,并通过 Python 中的 Pika 库实现了一个简单的生产者和消费者。使用 RabbitMQ 可以提升系统并发量、可靠性和稳定性,非常适合用于需要解耦不同模块之间通信的业务场景。如果需要更深入学习 RabbitMQ,可以访问 RabbitMQ 官网(www.rabbitmq.com)获取相关资料。文章来源地址https://www.toymoban.com/news/detail-501168.html
到了这里,关于RabbitMQ详细讲解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!