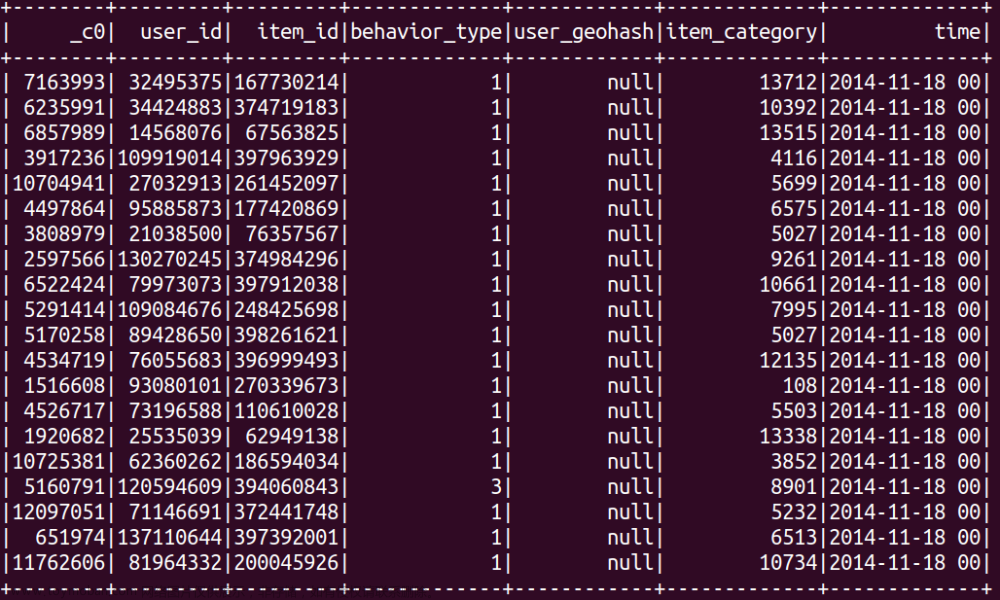
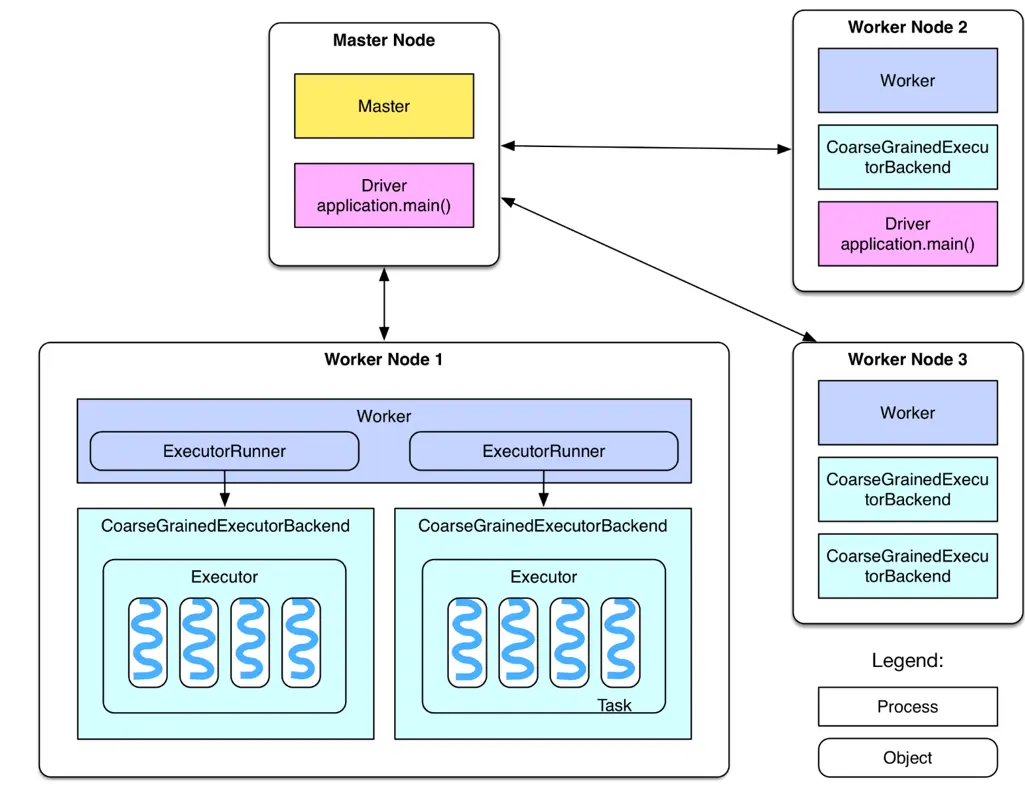
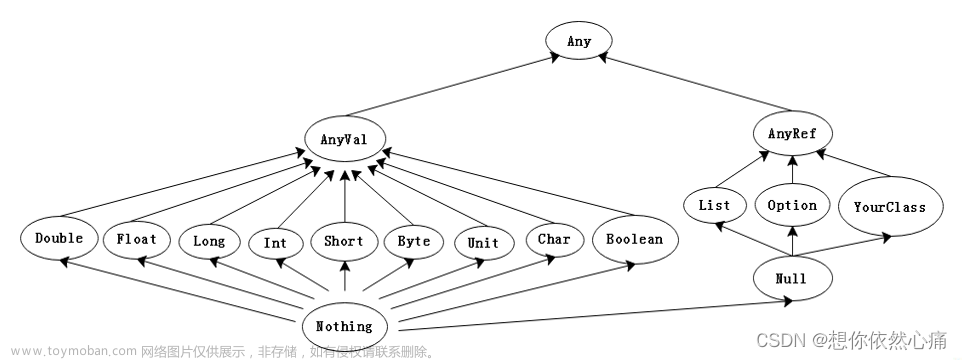
项目一:
一、选择题
DCCDAD
二、简答题
1、Hadoop MapReduce要求每个步骤间的数据序列化到磁盘,所以I/O成本很高,导致交互分析和迭代算法开销很大;Spark 提供了内存计算,把中间结果放到内存中,带来了更高的迭代运算效率。通过支持有向无环图(DAG)的分布式并行计算的编程框架,Spark 减少了迭代过程中数据需要写入磁盘的需求,提高了处理效率。
2、Local模式(单机模式)、Standalone模式、Spark on Mesos模式、Spark on YARN模式
项目二:
一、判断题
√√×√×
二、选择题
DDBDC
项目三:
一、判断题
√××××
二、选择题
DABC
项目四:
一、判断题
√×√√×
二、选择题
DDDA
项目五:
一、判断题
×××××
二、问答题
1、本教材图5-40中,对于输入数据Input,Spark从逻辑上生成RDD1和RDD2两个RDD,经过一系列“转换”操作,逻辑上生成了RDDn;但上述RDD并未真正生成,他们是逻辑上的数据集,Spark只是记录了RDD之间的生成和依赖关系。当RDDn要进行输出时(执行“行动操作”时),Spark才会根据RDD的依赖关系生成DAG(有向无环图),并从起点开始真正的计算。
2、窄依赖:一个RDD对它的父RDD,只有简单的一对一的依赖关系,也就是说,RDD中的每个partition,仅仅依赖于父RDD中的一个partition,父RDD和子RDD的partition之间是一对一的关系。这种情况下,是简单的RDD之间的依赖关系,也被称之为窄依赖。
宽依赖:本质就是shuffle,也就是说每一个父RDD中的partition中的数据,都可能会传输一部分到下一个RDD的每一个partition,也就是说,每一个父RDD和子RDD的partition之间,具有交互错杂的关系,那么这种情况就叫做
项目六:
一、判断题
××√××
二、问答题
1、对于流数据,Spark Streaming接收实时输入的数据流后,将数据流按照时间片(秒级)为单位进行拆分为一个个小的批次数据,然后经Spark引擎以类似批处理的方式处理每个时间片数据;Spark Streaming将流式计算分解成一系列短小的批处理作业,也就是把Spark Streaming的输入数据按照时间片段(如1秒),分成一段一段的离散数据流(称之为DStream,Discretized Stream);每一段数据都转换成Spark中的RDD,然后将Spark Streaming中对DStream流处理操作变为针对Spark中对RDD的批处理操作
2、步骤如下:
(1)通过创建输入DStream来定义输入源
(2)对DStream进行转换操作和输出操作来定义流计算。
(3)streamingContext.start()来开始接收数据和处理流程。
(4)streamingContext.awaitTermination()方法,等待处理结束(手动结束或因为错误而结束)。
(5)可以通过streamingContext.stop()来手动结束流计算进程。
项目七:文章来源:https://www.toymoban.com/news/detail-501306.html
一、判断题
√√×××
二、问答题
1、k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集。
2、推荐系统分为基于内容的推荐、基于知识的推荐和基于协同过滤的推荐等类别。基于内容的推荐算法,原理是用户喜欢和自己关注过的Item在内容上类似的Item;协同过滤包括基于用户的协同过滤、基于物品的协同过滤。基于用户的协同过滤推荐,可以用“臭味相投”这个词汇表示;当一个用户A需要个性化推荐时,可以先找到与A兴起相似的其他用户,然后把那些用户喜欢的、而用户A没听过的物品推荐给A。基于物品的协同过滤推荐是利用用户对物品的偏好程度(等级),计算物品之间的相似度,然后找出最相似的物品进行推荐。文章来源地址https://www.toymoban.com/news/detail-501306.html
到了这里,关于Spark大数据分析与实战课后习题参考答案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!