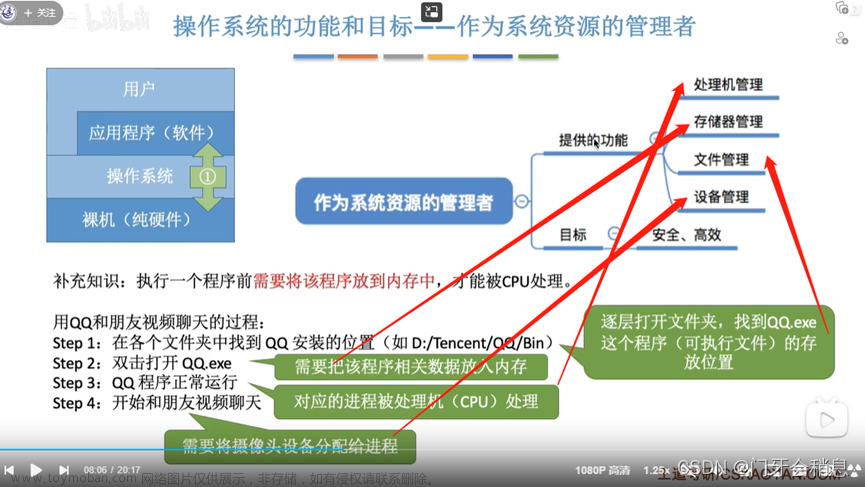
Hadoop安全模式
安全模式是保证系统保密性、完整性及可用性的一种机制,在一定程度上可以防止系统里的资源遭到破坏、更改和泄露,使整个系统持续、可靠地正常运行。
了解Hadoop安全模式
安全模式是Hadoop的保护机制,保障系统不受破坏。当处于安全模式时,文件系统只接收读数据的请求,而不接收删除、修改等变更请求。
若没有安全模式,则Hadoop将处于不受保护的状态,可能存在以下风险:
(1)Hadoop服务将不验证用户或其它服务。任何用户都可以访问HDFS,所有用户都可以对集群里的目录或文件进行增、删、改、查,个人文件的私密性将毫无保障。
(2)攻击者可以伪装成Hadoop服务。注册一个新的任务跟踪器,潜入Hadoop集群,监控整个集群的文件或目录和监控集群的运行。
(3)DataNode不会对节点上的数据块的访问实施任何访问控制。未经授权的用户可以随时获取想要的数据块信息,只需要提供对应的数据块ID,任何人都可以写任意数据到该节点。
所以,没有安全模式的Hadoop集群使用的风险是比较大的,集群的安全机制是必要的。
Hadoop开发者设定了一个安全模式:
用户只能访问有访问权限的HDFS目录或文件。
用户只能访问或修改自身的MapReduce任务。
用户使用Hadoop集群的相关服务要进行身份验证,以防未经授权的NameNode、DataNode、JobTracker或TaskTracker服务。
服务与服务之间也需要相互认证,以防未经授权的服务。
Kerberos凭证的获取和使用对用户和程序是透明的,前提是操作系统在登录时为用户获取了Kerberos票证授予票证,(Kerberos是一种计算机网络授权协议,使用在非安全网络中,对个人通信以安全的手段进行身份验证)。
查看、解除和开启Hadoop安全模式
查看安全模式
当启动Hadoop集群时,集群会进入安全模式,主要为了检查系统中的DataNode上的数据块的数量和有效性。在Linux系统上启动Hadoop集群,启动完成后可在本机浏览器的地址输入栏中输入“http://masster:9870”并按Enter键,查看HDFS的监控服务。


Summary模块下显示了安全模式信息,默认情况下刚开启集群时将自动开启安全模式,若显示“Safe mode is ON”,说明安全模式已启动。如果数据块还没加载到阈值,集群处于安全模式。若显示“Safe mode is off”,表示安全模式已自动关闭。

也可以在Linux终端使用命令查看安全模式情况。
解除和开启安全模式
当启动Hadoop集群时,集群会开启安全模式,原因是DataNode的数据块数没有达到总数据块的阈值。如果没有先关闭Hadoop集群,而直接关闭了虚拟机,那么Hadoop集群也会进入安全模式、保护系统。当再次开启Hadoop集群时,集群会一直处于安全模式,不会自动解除,这时使用命令可以解除安全模式。

使用命令使集群进入安全模式,在安全模式中,用户只能读取HDFS上的数据,不能进行增加、修改等操作。

查看Hadoop集群的基本信息
查询集群的存储系统信息
HDFS的监控服务默认是通过NameNode的9870端口进行访问的。
在本机浏览器的地址栏中输入“http://master:9870”并按Enter键查看当前HDFS的基本统计信息。
在页面中的“DataNode”,可以查看各DataNode的存储信息。
Hadoop也提供了命令行查询HDFS资源信息的方式,即“hdfs dfsadmin -report”命令;
基本语法:
-report : 输出文件系统的基本信息及相关数据统计。
-report -live : 输出文件系统中在线节点的基本信息及相关数据统计。
-report -dead : 输出文件系统中失效节点的基本信息及相关数据统计。
-report -decommissioning : 输出文件系统中停用的节点基本信息及相关数据统计。
在master节点中使用”hdfs dfsadmin -report -live“命令查看HDFS在线DataNode的基本信息。通过查询HDFS在线DataNode的基本信息,可以初步了解当前文件系统的基本情况。
查询集群的计算资源信息
在浏览器地址栏中输入http://master:8088/cluster/nodes 并按Enter键,查看当前Hadoop集群的计算资源信息。
页面中的”slave1:8042“超链接可以查看计算节点slave1的计算资源信息。
上传文件到HDFS目录
HDFS负责为用户创建、写入、读出、修改和存储文件、删除文件等。
HDFS是构建在服务器节点指定的目录/data/hadoop 上的,在实际工作环境中,文件系统是独立运行的,不同文件系统间的数据传输可通过命令或工具实现。
在本机浏览器的地址输入栏中输入”http://master:9870“ 并按Enter键,远程访问HDFS的监控端口。当需要访问HDFS上的文件及目录时,可以单击网页中的”Utilities“,在下拉菜单中选择”Browse the file system“。根目录”/“是HDFS所有目录的起始点。继续单机”Name“中的文件名可以浏览文件目录下的内容。
文件上传的流程:
在本地计算机中使用SSH或FTP工具上传文件至Linux本地的目录(master节点),如/root/hadoop/目录。
在master节点终端,使用HDFS命令,上传文件至HDFS的/user/root/目录下;也可以通过逆向操作进行文件下载,即将HDFS上的文件下载至本地计算机中。
HDFS的基本操作:
通过”hdfs dfs“命令即可完成对HDFS目录及文件的管理操作,包括创建目录、上传文件和下载文件,查看文件内容、删除文件或目录等。
创建目录
在集群服务器的终端,输入”hdfs dfs“命令,按下Enter键后即可看到HDFS基础操作命令的使用帮助信息,其中的[-mkdir [-p]<path>...]命令可用于创建目录,参数path用以指定创建的新目录。如在HDFS中创建/user/dfstest 目录:hdfs dfs -mkdir /user/dfstest
"hdfs dfs -mkdir <path>"命令只能逐级创建目录,如果父级目录不存在,那么使用该命令将会报错。
若加上”-p“,则可以同时创建多级目录,同时创建父级目录test和子目录example "hdfs dfs -mkdir -p /user/test/example".
上传文件与下载文件
创建新目录/usre/dfstest后,即可向该目录上传文件,通过”hdfs dfs “命令查看上传、下载文件命令的使用帮助信息。
文件上传
hdfs dfs [-copyFroLocal [-f] [-p] [-i] <localsrc> ... <dst>] : 将文件从本地文件系统复制到HDFS,主要参数localsrc为本地文件路径,dst为复制的目标路径。
hdfs dfs [-moveFroLocal [-f] [-p] [-i] <localsrc> ... <dst>] : 将文件从本地文件系统移动到HDFS,主要参数localsrc为本地文件路径,dst为移动的目标路径。
hdfs dfs [-put [-f] [-p] [-i] <localsrc> ... <dst>] : 将文件从本地文件系统上传到HDFS,主要参数localsrc为本地文件路径,dst为上传的目标路径。
文件下载
hdfs dfs [-copyToLocal [-p] [-ignoreCre] [-crc] <src> ...<localsrc>] : 将文件从HDFS复制到本地文件系统,主要参数src为HDFS文件路径,localsrc为本地系统文件路径。
hdfs dfs [-get [-p] [-ignoreCre] [-crc] <src> ...<localsrc>] : 获取HDFS上指定路径的文件到本地文件系统,主要参数src为HDFS文件路径,localsrc为本地系统文件路径。
查看文件内容
hdfs dfs [-cat [-ignoreCrc] <src> ...] : 输出HDFS文件内容,主要参数src用于指定文件路径。
hdfs dfs [-tail [-f] <file> ...] : 输出HDFS文件最后1024B的内容,主要参数file用于指定文件。
删除文件或目录
hdfs dfs [-rm [-f] [-r|-R] [-skipTrash] <src>...] : 删除HDFS上的文件,主要参数src用于指定删除文件的路径。
hdfs dfs [-rmdir [--ignore-file-no-non-empty] <dir>...] : 若删除的是一个目录,则可以用该命令,主要参数dir用于指定目录路径 。
运行首个MapReduce任务
MapReduce是Hadoop的数据处理引擎,是运算程序的核心。Hadoop官方提供了一个hadoop-mapreduce-examples-3.1.4.jar示例程序包给使用者初步运行MapReduce任务。
了解Hadoop官方的示例程序包
该程序包封装了一些常用的测试模块:
multifilewc : 统计多个文件中单词的数量
pi : 应用拟蒙特卡罗方法估算圆周率Π的值
randomtextwriter : 在每个DataNode随机生成一个10G的文本文件
wordcount : 对输入文件的单词进行频数统计
wordmean : 计算输入文件中单词的平均长度
wordmedian : 计算输入文件中单词长度的中位数
wordstandarddeviation : 计算输入单词长度的标准差
提交MapReduce任务给集群运行
提交MapReduce任务通常使用”hadoop jar“命令。
基础语法:
hadoop jar <jar> [maiClass] args
使用"hadoop jar"命令提交MapReduce任务
Hadoop jar \
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
/user/root/email_log.txt \
/user/root/output
”hadoop jar“命令的常用参考说明:
$HADOOP_HOME : 指主机中设置的环境变量(参考/etc/profile文件内容),此处的$HADOOP_HOME指的是Linux本地的/user/local/hadoop-3.1.4目录
hadoop-mapreduce-examples-3.1.4.jar : Hadoop官方提供的示例程序包,其中包括词频统计模块
wordcount : 程序包中的主类名称
/user/root/email_log.txt : HDFS上输入文件名称
/user/root/output : HDFS上的输出文件目录
输出的日志信息:
job_123456_7890 : 表示此项任务的ID,通常也被称为作业号。
map=0% reduce=0% : 表示将开始Map操作和Reduce操作。
Map=100% reduce=0% : 表示Map操作完成。
Map=100 reduce=100% : 表示Reduce操作完成。
Job 作业号 completed successfully :表示此任务成功完成。
Map input records=999999 : 表示输入的记录共999999条。
Reduce output records=99999 : 表示输出的结果共有99999条。
基于Hadoop集群的并行计算的执行率是很高的,执行任务完成后,在HDFS的/user/output/目录下将生成两个新文件,一个是SUCCESS文件,表示任务执行完成;另一个是part-r-00000文件,即任务完成后产生的结果文件。
part-r-00000文件的两列数据:
第一列为用户的邮件地址,第二列为该用户的登录次数。
管理多个MapReduce任务
Hadoop是一个多任务系统,可以同时为多用户、多个作业处理多个数据集。
在本机浏览器的地址栏输入”http://master:8088/“并按Enter键,打开Hadoop集群的资源管理器的监控服务主界面,对提交到Hadoop集群上的多个MapReduce任务进行管理。
查询MapReduce任务
调用Hadoop官方的示例程序包估算pi值,
Hadoop jar \
/user/local/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-maproduce-examples-3.1.4.jar \
pi \
10 \
100
最后的两个参数10和100分别代表Map数量与每个Map的测算次数,参数的值越大,计算的结果精度越高。
查看上面代码的MapReduce任务的计算资源使用情况,在本机浏览器地址输入栏中输入”http://master:8088/“并按Enter键,打开Hadoop集群的资源管理器的监控服务主界面,单击左侧菜单栏中的”Node“选项,也可以 直接访问”http://master:8088/cluster/nodes“,
继续查询当前任务的信息,在资源管理器的监控服务主界面,单击左侧菜单栏中的”Applications“选项,或直接访问”http://master:8088/cluster/apps“,如果该MapReduce任务目前状态为”RUNING“表示这个任务正在执行中,如果MapReduce任务的状态为”ACCEPTED“表示该任务已被资源管理器YARN接受,目前在等待被分配计算资源,只有当计算资源满足后才开始执行;继续单击这个任务的ID可以获取到关于该MapReduce任务更详细的信息。
统计用户登录次数
hadoop jar \
$HADOOP_HOME/share/hadoop/maproduce/hadoop-maproduce-examples-3.1.4.jar \
wordcount \
/user/root/email_log.txt \
/user/root/output1
估算pi值
Hadoop jar \
/user/local/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-maproduce-examples-3.1.4.jar \
pi \
10 \
100
中断Maproduce任务
对于已提交的Maproduce任务,在某些特殊情况下需要中断它,如发现过程有异常、某个任务执行时间过长、占用大量计算资源等。
例如提交两个任务,一个任务1估算pi值,一个任务2统计用户登录次数;
通过本机 浏览器,在资源管理器的监控服务主界面单击MapReduce任务1对应的ID号,将 弹出MapReduce任务1的执行信息窗口,
在界面左上角的”Kill Application“选项,并在弹出的对话框中单击”确定“按钮,
刷新任务1的执行信息窗口,显示MapReduce任务1在执行了987s后被中断了,
刷新资源管理器的任务列表监控界面,可以发现MapReduce任务1已被中断,MapReduce任务2正在执行中。
MapReduce任务的查询与中断将使用在多个MapReduce任务的开发调试中,如果有任务在执行过程中发生异常,则可查询任务的运行状态与相关日志信息,进行分析判断,若有必要,,可以中断相关MapReduce任务。
以上便是Hadoop基本操作的一些基本内容,虽然有些步骤缺少截图说明,读者也可以尝试操作以上步骤进行学习。文章来源:https://www.toymoban.com/news/detail-501340.html
这篇博客多有准备不周,还望您多多指点。文章来源地址https://www.toymoban.com/news/detail-501340.html
到了这里,关于Hadoop基本操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!