目录
StandardScaler的使用
KNeighborsClassifier的使用
代码实现
数据集介绍
数据集为一份红酒数据,总共有 178 个样本,每个样本有 13 个特征,这里不会为你提供红酒的标签,你需要自己根据这 13 个特征对红酒进行分类。部分数据如下图:

StandardScaler的使用
由于数据中有些特征的标准差比较大,例如 Proline 的标准差大约为 314。如果现在用 kNN 算法来对这样的数据进行分类的话, kNN 算法会认为最后一个特征比较重要。因为假设有两个样本的最后一个特征值分别为 1 和 100,那么这两个样本之间的距离可能就被这最后一个特征决定了。这样就很有可能会影响 kNN 算法的准确度。为了解决这种问题,我们可以对数据进行标准化。
标准化的手段有很多,而最为常用的就是 Z Score 标准化。Z Score 标准化通过删除平均值和缩放到单位方差来标准化特征,并将标准化的结果的均值变成 0 ,标准差为 1。
sklearn 中已经提供了 Z Score 标准化的接口 StandardScaler,使用代码如下:
from sklearn.preprocessing import StandardScaler
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
# 实例化StandardScaler对象
scaler = StandardScaler()
# 用data的均值和标准差来进行标准化,并将结果保存到after_scaler
after_scaler = scaler.fit_transform(data)
# 用刚刚的StandardScaler对象来进行归一化
after_scaler2 = scaler.transform([[2, 2]])
print(after_scaler)
print(after_scaler2)打印结果如下:
[[-1. -1.]
[-1. -1.]
[ 1. 1.]
[ 1. 1.]]
[[3. 3.]]根据打印结果可以看出,经过准换后,数据已经缩放成了均值为 0,标准差为1的分布。
KNeighborsClassifier的使用
想要使用 sklearn 中使用 kNN 算法进行分类,只需要如下的代码(其中 train_feature、train_label 和 test_feature 分别表示训练集数据、训练集标签和测试集数据):
from sklearn.neighbors import KNeighborsClassifier
#生成K近邻分类器
clf=KNeighborsClassifier()
#训练分类器
clf.fit(train_feature, train_label)
#进行预测
predict_result=clf.predict(test_feature)但是当我们需要调整 kNN 算法的参数时,上面的代码就不能满足我的需求了。这里需要做的改变在clf=KNeighborsClassifier()这一行中。
KNeighborsClassifier() 的构造函数包含一些参数的设定。比较常用的参数有以下几个:
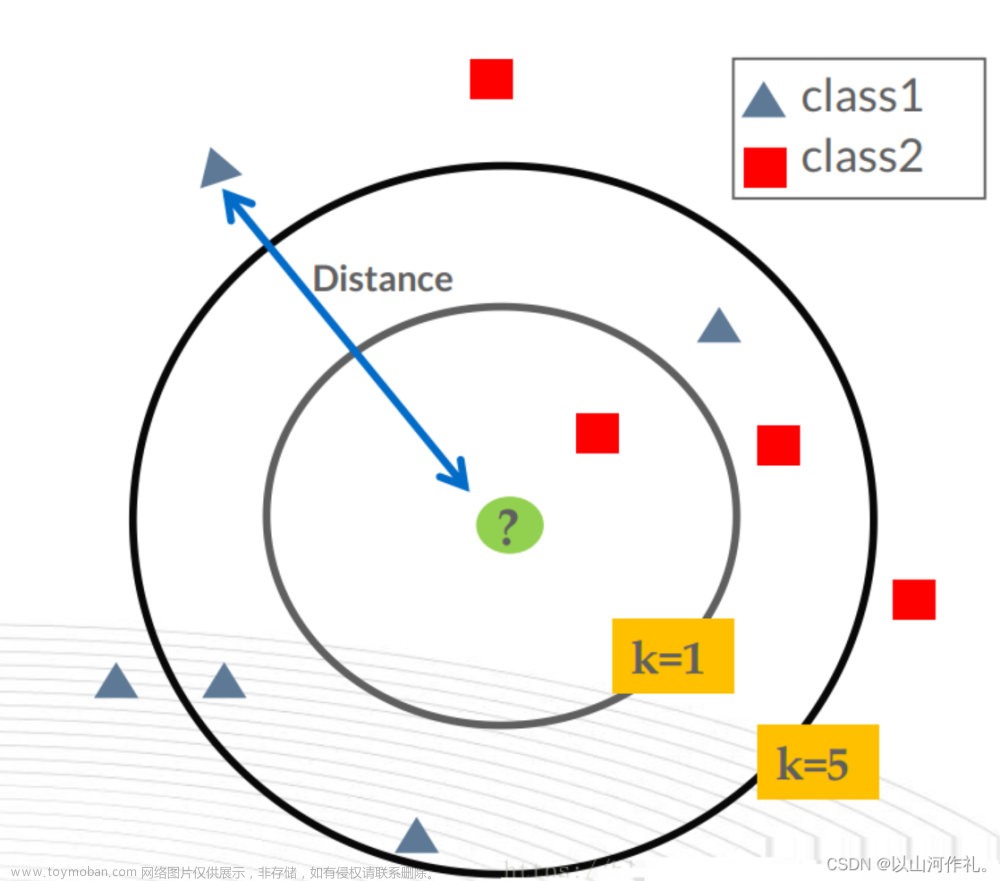
- n_neighbors :即 kNN 算法中的 K 值,为一整数,默认为 5;
- metric :距离函数。参数可以为字符串(预设好的距离函数)或者是callable对象。默认值为闵可夫斯基距离;
- p :当 metric 为闵可夫斯基距离公式时可用,为一整数,默认值为 2,也就是欧式距离。
代码实现
函数需要完成的功能是使用 KNeighborsClassifier 对 test_feature 进行分类。其中函数的参数如下:
-
train_feature : 训练集数据,类型为 ndarray;
-
train_label : 训练集标签,类型为 ndarray;文章来源:https://www.toymoban.com/news/detail-501539.html
-
test_feature : 测试集数据,类型为 ndarray。文章来源地址https://www.toymoban.com/news/detail-501539.html
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import numpy as np
def classification(train_feature, train_label, test_feature):
'''
对test_feature进行红酒分类
:param train_feature: 训练集数据,类型为ndarray
:param train_label: 训练集标签,类型为ndarray
:param test_feature: 测试集数据,类型为ndarray
:return: 测试集数据的分类结果
'''
#********* Begin *********#
#实例化StandardScaler函数
scaler = StandardScaler()
train_feature = scaler.fit_transform(np.array(train_feature).reshape(133,13))
test_feature = scaler.transform(np.array(test_feature).reshape(45,13))
#生成K近邻分类器
clf = KNeighborsClassifier()
#训练分类器
clf.fit(train_feature, train_label.astype('int'))
#进行预测
predict_result = clf.predict(test_feature)
return predict_result
#********* End **********#到了这里,关于机器学习——kNN算法之红酒分类的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!