点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【3D目标检测】技术交流群
后台回复【FastPillars】获取本文论文和代码!!!
摘要
3D检测器的部署是现实世界自动驾驶场景中的主要挑战之一。现有的基于BEV(即鸟瞰图)的检测器支持稀疏卷积(称为SPConv),以加快训练和推理,这为部署(尤其是在设备上应用)带来了困难。本文解决了从LiDAR点云中高效检测3D目标的问题,并考虑了模型部署。为了减少计算负担,论文从行业角度提出了一种基于Pillar的高性能3D检测器,称为FastPillars。与以前的方法相比,论文引入了一个更有效的Max-and-Attention pillar encoding(MAPE)模块,并以重参数化的方式重新设计了一个功能强大、轻量级的骨干CRVNet,该骨干CRVNet带有Cross Stage Partial网络(CSP),形成了一个紧凑的特征表示框架。大量实验表明,FastPillars在设备速度和性能方面都超过了最先进的3D检测算法。具体而言,FastPillars可以通过TensorRT有效部署,在nuScenes测试集上以64.6 mAP在单个RTX3070Ti GPU上获得实时性能(约24FPS)。
总结来说,本文的主要贡献如下:
论文提出了一种用于工业应用的基于Pillar的一阶段3D检测器,称为FastPillars。FastPillars是部署友好的,并且消除了阻碍设备部署的稀疏卷积的需要。FastPillar-s和FastPillar-m,它们在nuScenes测试集上分别可以以24 FPS的速度实现64.6 mAP和70.1 NDS,以及以16 FPS的速度达到66.0 mAP和71.1 NDS;
还提出了一种简单但有效的Max-and-Attention pillar encoding(MAPE)模块。MAPE几乎无需额外的耗时(仅4ms)就能提高每个pillar特征的表示能力;
论文为3D检测任务设计了一个紧凑的全卷积主干网络CRVNet,它具有竞争性的特征学习能力和推理速度,而不需要稀疏卷积。同时论文还表明,专门为2D图像设计的轻量级网络结构可以很好地处理使用3D点云的任务,并在性能和速度之间实现出色的权衡;
在nuScenes数据集上的大量实验表明,FastPillars具有卓越的效率和准确的检测性能。论文还提供了详细的性能与推理速度对比分析,以进一步验证论文方法的优越性。
相关工作
基于体素的3D探测器:基于体素的3D检测器[5,6,18,19,30,44,47,49]通常将非结构化点云转换为紧凑形状的规则pillar/voxel网格。这进一步允许通过利用成熟的2D/3D卷积神经网络来学习点云特征。VoxelNet[49]是一项开创性的工作,它对输入点云进行密集体素化,然后利用体素特征提取器(VFE)和3D CNN来学习几何表示。其缺点是由于3D卷积的巨大计算负担,推理速度相对较慢。为了节省内存成本,SECOND[44]使用3D稀疏卷积[14]来加速训练和推理。这里,稀疏卷积仅对非空体素进行操作,这大大提高了计算和存储效率。SPConv的一个缺点是它对部署不友好,这使得在嵌入式系统上应用它们很困难。为此,PointPillars[19]被提议将体素进一步简化为pillar(即,在高度上没有体素化),并利用高度优化的2D卷积,这在低耗时的情况下获得了良好的性能。同时,易于部署的优势使PointPillar成为实践中的主流方法。之后,提出了CenterPoint[47],它使用几乎实时且anchor-free的管道,实现了最先进的性能。最近,PillarNet[30]项目指向BEV空间,并使用基于“encoder-neck-head”架构的2D SPConv以实时速度提高3D检测性能。由于SPConv的使用,它不可避免地面临着在工业应用中部署的困难,并随着网络量化而进一步加速。
用于目标检测的行业级轻量级网络结构:多年来,YOLO系列[1,12]一直是轻量级2D检测的事实上的行业标准,其主干设计主要继承了CSPNet的思想[40]。通过在两个单独的分支中处理部分特征以获得更丰富的梯度组合,CSPNet不仅降低了内存和计算成本,而且提高了性能。
最近,RepVGG[8]使用基于重参数化的结构设计重构了著名的plain network VGG[34]。在训练期间,普通的Conv-BN-ReLU被其过度参数化的三分支对应物(即Conv3x3-BN、Conv1x1-BN和Identity-BN)取代,然后是三个分支相加后的ReLU函数。三分支结构实质上有助于网络优化,而重参数化在推理时将三个分支相同地转换为一个分支,提高了推理效率。由于这一优势,这一趋势席卷了2D目标检测器,并在极端速度下表现出高性能,如PPYOLOE[43]、YOLOv6[21]和YOLOv7[39]。尽管取得了成功,但据论文所知,目前还没有看到这些方案在3D检测中的任何应用。
论文方法
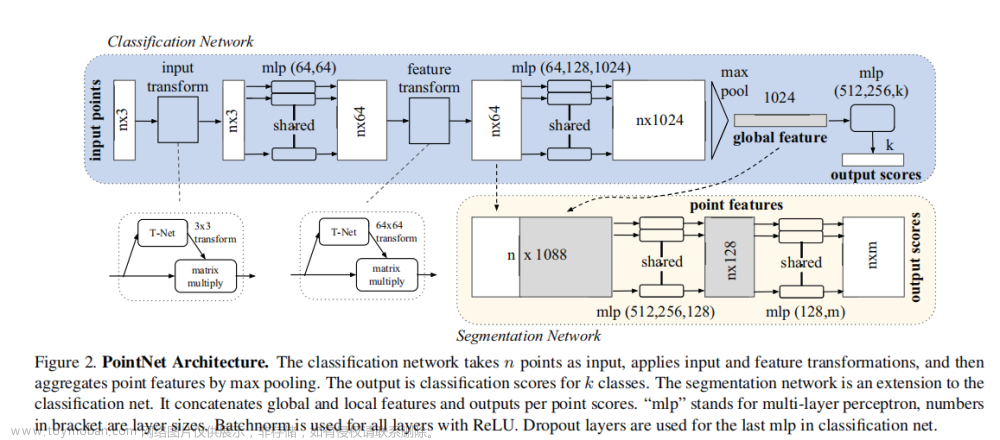
本节将介绍FastPillars用于基于pillar的实时一阶段3D检测,这是一种端到端可训练且无SPConv的神经网络。如图1所示,网络架构由四个部分组成:pillar编码模块、用于特征提取的主干、用于特征融合的neck和用于3D box回归的头。
Max-and-Attention Pillar Encoding
点云voxel/pillar编码对于基于网格的3D检测方法至关重要。开创性的PointPillars[19]积极利用max pooling来聚合每个pillar中的点云特征,以表示相应的pillar。然而,max-pooling操作将导致细粒度信息的丢失,而这些局部几何模式对于基于pillar的目标非常关键,尤其是对于小目标。本文提出了一种简单但高效的pillar编码模块,称为Max-and-Attention Pillar Encoding(MAPE),它以可忽略的计算负担考虑到每个pillar的局部详细几何信息,并有利于BEV中小目标(例如行人等)的性能。同时,MAPE模块的轻量级pillar编码方法使其非常适合实时嵌入式应用。如图2所示,的MAPE模块由三个单元组成:1)点云编码单元;2)max-pooling编码单元;3)attentive-pooling编码单元。
点云编码:首先将每个pillar中的点云增强为。值得注意的是,在每个pillar中,没有采用任何采样策略来保持每个pillar中的点云数相同,因为这种操作可能会丢失有用的点云并损害原始几何图案。其次,通过MLP层将内的增强逐点云特征映射到高维特征空间。该过程制定为:
Max-pooling编码:该单元用于将pillar内的所有点云特征聚合为单个特征向量,同时它对每个pillar中的点云排列不变,公式如下:
Attention-pooling编码:该单元旨在维护局部细粒度信息。Max pooling很难在每个pillar中集成逐点云特征,因为它只需要最大值。然而,丰富的局部细节对于从BEV角度检测较小的目标非常有用。因此,论文转向强大的注意力机制来自动学习重要的局部特征。具体而言,首先使用由共享MLP组成的函数来预测pillar中这些点的云注意力得分。其次学习到的注意力分数可以被视为一个soft mask,它动态地衡量逐点云特征。最后,加权求和特征如下:
最后将学习到的pillar-wise max-pool和attentive pooling特征通过平均值进行组合。max-pooling操作保留每个pillar中的最大响应特性,而attentive pooling特性保留局部细粒度信息。通过结合这两个特征,可以有效地保留更丰富的信息,以增强pillar表示。尽管是一种简单的方法,但MAPE模块显著影响了小目标的性能,如实验所示。值得注意的是,MAPE模块仅在额外4毫秒耗时的情况下,在nuScenes数据集上提高了约0.6mAP的性能。
CRVNet Backbone
主干网络旨在从投影的2D伪图像或3D体素特征中分层地提取各种级别的语义特征。先前的工作[6,30,44,47]通常使用稀疏卷积[14]来基于ResNet[15]或VGG[34]架构提取体素/逐柱特征。稀疏卷积大大提高了计算效率,因为大多数体素/pillar是空的。例如,在nuScenes数据集上的单个帧点云中,空pillar的比例约为90%。然而直接在稀疏特征图上使用2D卷积将导致过度的计算负担和高耗时,这促使论文设计更紧凑和有效的主干网络。
受RepVGG[8]和CSPNet[40]的启发,论文提出了CRVNet(Cross-Stage-Patrial RepVGG-style Network)。网络的主要组成部分如图3所示。训练阶段的每个模块如图3(a)所示。在推断阶段(图3(b)),每个Rep-Block被转换为具有激活函数的3个卷积层(表示为RepConv)的堆栈。这是因为3x3卷积具有更高的计算密度,并且在大多数设备上效率很高。因此,RepBlock骨干网络以优异的特征表示能力显著降低了推理耗时。此外论文注意到,如果模型容量进一步扩大,单路径平面网络中的计算成本和参数数量将呈指数增长。因此进一步将RepBlock与CSP结构结合起来。如图3(d)所示,CSP结构由三个1x1卷积层和原始网络结构组成。论文在主干网络的每个阶段使用CSP结构,其中每个阶段包含N个RepConv(图3(c))。通过引入CSP结构,整个网络具有更少的参数,并且更加紧凑和高效。值得注意的是,尽管RepBlock和CSP在基于2D图像的任务中被证明是有效的[21,39,43],但它们尚未被充分用于3D点云任务。本文的FastPillars-s和FastPillar-m模型分别建立在VGG和ResNet-34网络上。论文发现,最终性能对后期的容量不敏感,但对早期的容量非常敏感,这与FCOS-LiDAR中的情况一致[36]。因此,论文将FastPillers-s中VGG的四个阶段的块数从(4,6,16,1)更改为(6,16,1,1),将FastPillars-m中ResNet-34的四个级别的块数分别从(3,4,6,3)和(6,6,3,2),同时都删除了第一阶段的第一个2x下采样。
Neck and Center-based Heads
在Neck中,论文采用了PillarNet[30]中的增强neck设计。neck将特征与来自主干的8x和16x特征图融合,以实现不同空间语义特征的有效交互。论文发现,在这种neck设计中,级联操作之前的卷积层的数量显著影响最终性能。论文将在实验中详细讨论这一点。对于回归头,直接遵循[47]使用其简单但有效的head设计。此外还添加了一个IoU分支来预测预测框和地面真实框之间的3D IoU。然后[17]中的IoU感知校正函数用于弥补分类和回归预测之间的差距。具体而言,非最大抑制(NMS)后处理的校正置信分数C通过以下公式计算:
最终损失函数如下 :
实验
论文在nuScenes数据集上展开实验。
整体结果
定量评估
为了公平比较,论文在nuScenes测试集上使用之前发布的仅限LiDAR的非集成方法来评估FastPillars。如表1所示,FastPillars显著优于最先进的(SOTA)方法,同时具有24FPS的实时速度。与最先进的PillarNet方法[30]相比,FastPillars-m实现了几乎相同的性能,并且在没有衰落策略的情况下也超越了几乎所有以前的方法。
与实时一阶段方法的比较
为了进一步评估论文方法的速度和性能优势,还将FastPillars与nuScenes值集上的实时一阶段3D点云检测器进行了比较。如表2所示,与使用CenterPoint的训练设置的CenterPoint论文中实现的PointPillars[20]相比,FastPillars-s在3D mAP和NDS中的表现也更好,分别高9.74%和7.0%。与最先进的PillarNet方法相比[30],FastPillars-s实现了具有竞争力的性能(mAP和NDS分别仅低0.16%和0.33%),但速度是PillarNet的两倍。实验表明,该方法具有较少的参数、较高的性能和FPS。注意,FLOPs不会强烈反映真实的推理速度(即FPS)。推理速度明显更快是因为PillarNet需要稀疏卷积,因此对部署不友好,而我们的方法是全卷积的,可以通过TensorRT和网络量化有效地部署在资源受限的机载系统中。因此,FastPillars能够在性能和速度之间提供更好的权衡。
推理时间分析
如表3所示使用10次点云扫描,按照基准测试的惯例来测量FastPillers-s/m在nuScenes测试集上的速度。与CenterPoint相比,FastPillars-s实现了SOTA性能,将CenterPoint提高了2.37 mAP和1.83 NDS,同时在表2中运行速度提高了2倍。CenterPoint的推断时间包括体素编码的1.84ms、网络的69.89ms和后处理的7.40ms。FastPillars-s在单个NVIDIA 3070Ti GPU上实现了24 FPS,包括13.22毫秒用于pillar编码,20.10毫秒用于模型正向传播,8.10毫秒用于后处理。对于具有更大主干的FastPillers-m,在同一设备上实现了16.8 FPS,其中pillar编码为13.40 ms,模型前向传播为34.44 ms,后处理为8.12 ms。
消融实验
Max-and-Attention Pillar Encoding Module
如表4所示,与max-pooling操作相比,MAPE模块可以提高0.6%的mAP性能,仅需4ms的额外耗时成本。具体而言,由于MAPE模块自行车(BC)、交通锥(TC)和障碍物类别的mAP分别提高了3.64%、1.33%和3.44%。对于行人类别,论文推测其性能在基准上已经饱和,因此MAPE模块显示出微弱改善。实验表明,MAPE模块通过结合注意力池化和最大池化操作,有效地编码了局部细粒度几何图案和最突出的特征(即最大值),提高了BEV视角下小尺寸目标的感知能力。
CSP比率选择
基于CRVNet主干,使用不同比例的Cross-Stage-Patrial网络进行消融研究,如表5所示。
轻量级主干结构
如表6所示,论文发现应用于FastPillers-s模型的CSPRepVGG主干具有最小的模型容量和耗时,同时具有59.40mAP的良好性能。CSPRep-Res34是FastPillars-m模型主干,尽管具有最大的参数量和耗时,但它具有最佳的性能。与CSPRepVGG主干相比,CSPRep-Res34主干在nuScenes值集上的表现更好,提升为1.92mAP和0.99NDS。总体而言,论文的方法在速度和准确性之间实现了良好的平衡,尤其是在实时耗时方面具有最先进的性能。
结论
本文提出了FastPillars,一种基于一阶段pillar的实时3D检测器,以同时提高检测精度和运行效率,同时考虑部署。特别是,论文表明SPConv可以通过重新设计的强大架构安全地绕过。此外还提出了MAPE模块来补偿PointPillars中pillar编码的信息损失。广泛的实验表明,FastPillars在速度和准确性之间实现了更好的权衡,并且可以通过TensorRT对设备上的实时应用进行定量部署。鉴于其有效性和效率,希望我们的方法可以作为当前主流的基于SPConv的实时3D检测器的强大而简单的替代方案。
参考
[1] FastPillars: A Deployment-friendly Pillar-based 3D Detector
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;
添加汽车人助理微信邀请入群文章来源:https://www.toymoban.com/news/detail-501613.html
备注:学校/公司+方向+昵称文章来源地址https://www.toymoban.com/news/detail-501613.html
到了这里,关于美团最新!FastPillars:基于Pillar的最强3D检测落地方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!