前言:七八九用于Spark的编程实验
大数据开源框架之基于Spark的气象数据处理与分析_木子一个Lee的博客-CSDN博客_spark舆情分析
目录
实验环境:
实验步骤:
一、解压
二、配置环境变量:
三、修改配置文件
1.修改spark-env.sh配置文件:
2.修改配置文件slaves:
3.分发配置文件:
四、测试:
五、网页测试:
六、解决能启动Spark Shell但是报错:
七、安装python3.6
八、Jupyter Notebook
1.安装pip
2.安装jupyter
3.配置环境变量
4.创建Jupyter默认配置文件
5.启动和测试
九、Pip安装matplotlib
实验环境:
操作系统:Ubuntu 18.04
Python:3.6.9
Spark版本:2.4.0
实验步骤:
一、解压
tar -zxf ./spark-2.4.0-bin-without-hadoop.tgz -C /usr/local

修改文件名字
mv spark-2.4.0-bin-without-hadoop spark
二、配置环境变量:

vim /etc/profile添加:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
三、修改配置文件
1.修改spark-env.sh配置文件:
cd /usr/local/spark/conf
cp spark-env.sh.template spark-env.sh:
添加(最后一项不添加也行):
export JAVA_HOME=/usr/local/jdk
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_HOST=master
export SPARK_MAETER_PORT=7070
#spark默认web访问端口为8080,为了防止冲突,可以修改(不改也行)

2.修改配置文件slaves:
cp slaves.template slaves
添加slave1和slave2:

3.分发配置文件:
scp -r /usr/local/spark root@slave1:/usr/local/scp -r /usr/local/spark root@slave2:/usr/local/
四、测试:
先启动hadoop
start-dfs.shstart-yarn.sh再启动spark:

启动spark master节点:
start-master.sh
启动spark所有slave节点:
start-slaves.sh
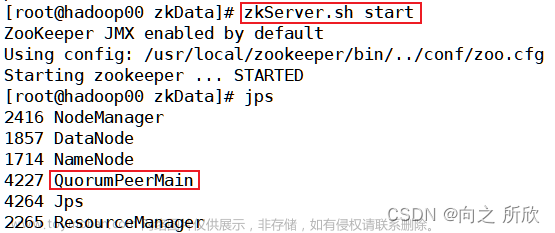
Jps:
master节点:

slaves:


五、网页测试:
在master浏览器打开
http://master:8080
Spark的关闭:
关闭Master节点
stop-master.sh关闭Worker节点
sbin/stop-slaves.sh关闭Hadoop集群
stop-dfs.shstop-yarn.sh测试自带样例:
./run-example sparkPi 2>&1|grep "Pi is"

六、解决能启动Spark Shell但是报错:


解决:
vim /etc/profile添加:
export TERM=xterm-color
刷新环境变量:
source /etc/profile
重新启动即可
shark-shell
七、安装python3.6
apt-get install python3.6-tk
查看版本:

八、Jupyter Notebook
1.安装pip
apt-get install -y python3-pip

更新pip:

2.安装jupyter
python3 - pip install jupyter


3.配置环境变量
vim /etc/profile添加如下代码
export PATH=$PATH:~/.local/bin退出编辑并执行
source /etc/profile

4.创建Jupyter默认配置文件
jupyter notebook --generate-config
生成SHA1加密的密钥,保存密钥,如''argon2:$argon2idXXX''
ipythonfrom notebook.auth import passwd下面命令需要自己自定义一个密码:
passwd()exit()
把这个argon2字符串复制粘贴到一个文件中保存起来,后面用于配置密码。(每个人都不一样!!!)
'argon2:$argon2id$v=19$m=10240,t=10,p=8$0o4PUoInp4ez5ieMPdBn4Q$PzBU/k+PjTRNXnDnZYXXvE9MB/AR5dTLwwZfdZCo1io'(每个人都不一样!!!)
设置密钥,修改配置文件
执行
vim /root/.jupyter/jupyter_notebook_config.py添加:
c.NotebookApp.ip='*' # 就是设置所有ip皆可访问
c.NotebookApp.password = 'argon2:$argon2id$v=19$m=10240,t=10,p=8$0o4PUoInp4ez5ieMPdBn4Q$PzBU/k+PjTRNXnDnZYXXvE9MB/AR5dTLwwZfdZCo1io'
# 上面复制的那个argon2密文'
c.NotebookApp.open_browser = False # 禁止自动打开浏览器
c.NotebookApp.port =8888 # 端口需要注意的是,在配置文件中,c.NotebookApp.password的值,就是刚才前面生成以后保存到文件中的sha1密文。另外,c.NotebookApp.notebook_dir = '/home/hadoop/jupyternotebook' 这行用于设置Notebook启动进入的目录,由于该目录还不存在,所以需要在终端中执行如下命令创建:
mkdir -p /home/hadoop/jupyternotebook
5.启动和测试
jupyter notebook报错:

绕过root用户运行:
jupyter notebook --allow-root


测试:

以上步骤参考:Ubuntu 安装jupyter notebook - Leon_梁远 - 博客园 (cnblogs.com)
或可以首先安装Anaconda,然后再配置Jupyter Notebook:
使用Jupyter Notebook调试PySpark程序_厦大数据库实验室博客 (xmu.edu.cn)
九、Pip安装matplotlib

这个会报错:

可以用
apt-get install python3-matplotlib 文章来源:https://www.toymoban.com/news/detail-502022.html
文章来源:https://www.toymoban.com/news/detail-502022.html
配置完成 文章来源地址https://www.toymoban.com/news/detail-502022.html
到了这里,关于大数据开源框架环境搭建(七)——Spark完全分布式集群的安装部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!