采访嘉宾 | 郭炜、高俊
编辑 | Tina
北京时间 2023 年 6 月 1 日,全球最大的开源软件基金会 Apache Software Foundation(以下简称 ASF)正式宣布 Apache SeaTunnel 毕业成为 Apache 顶级项目 (TLP, Top Level Project)。
Apache SeaTunnel 于 2021 年 10 月申请加入 Apache 孵化器,不到 2 个月,便以“全票通过”的优秀表现正式成为 Apache 孵化器项目。2023 年 5 月 17 日,Apache 董事会通过 Apache SeaTunnel 毕业决议,结束了为期 18 个月的孵化,正式确定 Apache SeaTunnel 成为 Apache 顶级项目。
这是首个由国人主导并贡献到 ASF 的大数据集成领域的顶级项目,为了了解项目的起源、发展过程,以及开源心得,InfoQ 采访了 Apache SeaTunnel 项目的关键成员。
采访嘉宾简介:
郭炜,Apache 基金会成员;Apache DolphinScheduler PMC Member;Apache SeaTunnel Mentor。
高俊,Apache SeaTunnel PMC Chair。
Apache SeaTunnel 的起源
** InfoQ:在大数据体系里,Apache SeaTunnel 起到的主要作用是什么?**
郭炜:目前,大数据体系里有各种各样的数据引擎,有大数据生态的 Hadoop、Hive、Kudu、Kafka、HDFS,也有泛大数据库体系的 MongoDB、Redis、ClickHouse、Doris,更有云上的 AWS S3、Redshift、BigQuery、Snowflake,还有各种各样数据生态 MySQL、PostgresSQL、IoTDB、TDEngine、Salesforce、Workday 等。我们需要工具让这些数据之间能互联互通,那么 Apache SeaTunnel 就是打通这些复杂数据源的利器,它可以简单、准确、实时地把各种数据源整合到目标数据源当中,成为大数据流动的“高速公路”。
** InfoQ:Apache SeaTunnel 是如何发挥作用的,其关键原理、核心设计是什么?**
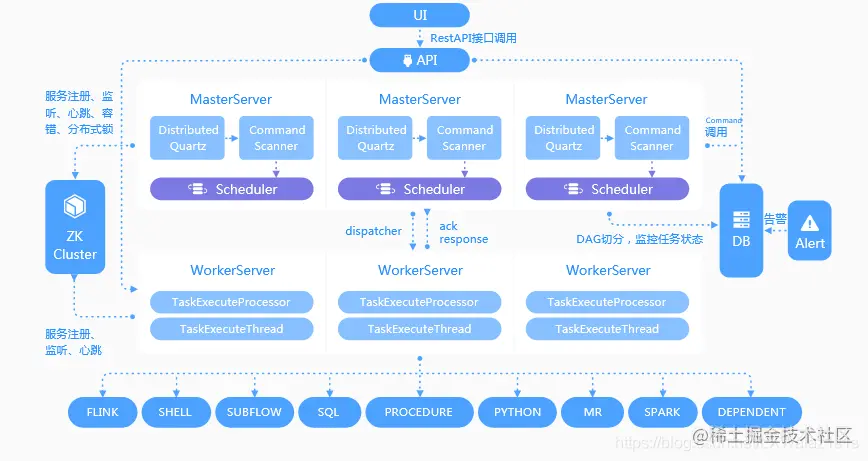
郭炜:面对成百上千的数据源,我们需要一个简单高效的架构来解决各种各样的数据源之间数据集成的问题。Apache SeaTunnel 由三大部分组成,源连接器(Source Connector)、传输计算引擎(SeaTunnel Zeta、Flink、Spark),目标连接器(Sink Connector)。简单来说,源连接器就是实时地读取数据源端(也许是 JDBC,也许是 Binlog,也许是非结构化 Kafka 或者 SaaS API,AI 数据模型),把这些数据转化成 SeaTunnel 可以理解的标准数据格式再传送给传输计算引擎,传输计算引擎将对这些数据进行处理(例如数据格式变化,分词等)和分发,最终 Sink Connector 将 SeaTunnel 数据格式变化为目标端的格式存入目标数据库。当然,其中有非常复杂的高性能数据传输、分布式快照、全局 Checkpoint、两阶段提交等,来确保数据可以高效、快速地传递到目标端。
最近社区还提交了 SeaTunnel-Web,让用户不仅可以用类 SQL 语言来做 Transform,还可以利用界面拖拽来直接打通不同的数据源。任何一个开源用户都可以方便地扩展自己使用数据源的 Connector,然后提交到 Apache 社区,让更多的人一起使用它。同时,你也可以快速使用别人贡献的 Connector 来快速解决自己企业数据源之间的打通问题。目前,SeaTunnel 已经支持了包括 CDC、云存储、数据库、SaaS 等 100 多个数据源,让企业方便地打通各种各样的数据源。人人为我、我为人人 ,这在开源的 Apache SeaTunnel 项目中体现得淋漓尽致。
Apache SeaTunnel 的演进过程
** InfoQ:Apache SeaTunnel 项目的演进,主要有哪几个发展阶段?**
高俊:Apache SeaTunnel,起初名为 Waterdrop,是一个易用且高效的海量数据集成平台,主要基于 Apache Spark 和 Apache Flink 构建。它支持海量数据的实时同步与转换。
Waterdrop 阶段。这一阶段的主要目标是帮助 Spark 更简单地处理异构数据源数据。在此期间,Waterdrop 的主要使命是通过提供一个简单易用、能够支持每天数百亿条海量数据同步的开源软件,将海量数据同步的能力传播到全世界。
SeaTunnel 初期。在 2021 年 Waterdrop 更名为 SeaTunnel 之后,它的主要目标是更简单地进行异构数据源同步和集成。SeaTunnel 的设计目标是要大大降低用户使用 Spark、Flink 等技术做数据集成的门槛。这个阶段的重点是利用 Spark 和 Flink 作为底层数据同步引擎,提高数据同步的吞吐性能。此外,SeaTunnel 还开始引入可插拔的插件体系,支持超过 100 种数据源,从而增强其数据集成的能力。
SeaTunnel 中期。在 SeaTunnel 的中期阶段,SeaTunnel 建立了Zeta引擎,专为数据同步集成而设计。新的引擎减少了对第三方服务的依赖,使得那些没有大数据平台或不愿意依赖大数据平台进行数据同步的用户也能轻松使用 SeaTunnel。Zeta 引擎利用 Dynamic Thread Sharing 技术优化资源使用,提供数据同步任务的 Checkpoint 和容错机制,以及执行计划优化器以减少网络传输,从而提高数据同步效率。SeaTunnel 的这一阶段重点在于支持全场景数据同步,包括离线批量同步、全量同步、增量同步、实时同步以及 CDC。
SeaTunnel 最新阶段。最近,SeaTunnel 进入了一个新的发展阶段,这个阶段的目标是使得更广泛的用户群体,包括数据分析师和数据科学家,也能从 SeaTunnel 高效、简单的数据集成功能中受益。为了实现这个目标,SeaTunnel 引入了可视化界面,让用户能更直观、更方便地实现异构数据的实时同步和集成,其目标已经扩展到为工程师、数据分析师、数据科学家、AI 算法工程师等人群提供更高效、更简单的异构数据同步、实时同步集成功能。
从 Waterdrop 到 SeaTunnel ,再到 Zeta 引擎的自主设计,再到现在的可视化界面融合,Apache SeaTunnel 的发展历程凸显了其持续创新,致力于降低大数据处理难度,并提升数据处理效率的使命。未来,我们期待 SeaTunnel 能在大数据领域持续推动创新,为更多用户提供优质的数据集成解决方案。
** InfoQ:Apache SeaTunnel 经历过重构?那么改进了哪些功能,并如何保证稳定性的?**
高俊:这里主要指的是对 Apache SeaTunnel 连接器的重构,连接器是负责将具体的上下游数据源进行打通,是数据集成的关键组成部分。加入 Apache 之前,Waterdrop 的定位是让 Flink 和 Spark 使用起来更简单,所以整个架构设计都是基于 Flink 和 Spark 之上。特别是连接器,基本是将 Spark 和 Flink 的连接器引入进来就行了,对于 Spark 和 Flink 没有的连接器,需要使用 Spark 和 Flink 的 API 分别开发一套代码,早期批和流还是不同的 Flink API,意味着同一个数据源为了实现批同步和流同步,也需要开发两套代码。
代码的开发量和维护成本太高了。于是去年年初社区发起了重构连接器的讨论,目标是定义 SeaTunnel 自己的连接器 API,与具体的引擎解耦,不依赖具体的引擎 API,真正的实现批流一体,同一个数据源只需要一套代码就可以同时运行在 Spark 和 Flink 引擎上。
在讨论初期有不少人持反对意见,认为 Flink 和 Spark 这些引擎很成熟,强依赖它们也没什么问题,有些贡献者觉得我们应该放弃 Spark 全面依赖 Flink,在 Flink 的基础上把功能做好做完善。而且,重构连接器 API 意味着之前的 50 多个连接器的工作都白费了,一切要从零开始。但最终社区达成了共识,一切从 SeaTunnel 项目的定位出发,所以技术方向应该服从项目的目标和定位。目标确立后,社区花了一个月设计新的连接器 API,然后用了 4、5 个月就已经支持到了 100 多个连接器,速度之快是之前的架构不可能达到的,并真正实现了 SeaTunnel 支持多引擎和多引擎版本的能力。
现在,SeaTunnel 已经支持了 Spark2、Spark3、Flink 1.14、Flink 1.15、Flink 1.16 等多个引擎和版本,同时也有了自己的专注于解决同步领域问题的超高性能引擎 Zeta。
** InfoQ:SeaTunnel CDC 与 Flink CDC、DataX 的主要区别是什么?我们应该如何选型?**
郭炜:SeaTunnel 是批量处理和 CDC 处理同时支持,它可以自动化地切换批和流的切换点,同时在引擎方面,它支持了 Flink CDC 不支持的 DDL 变更检测,第三方 Kafka 缓冲支持,多表公用一个任务等。相比 DataX,除了批量性能超过其 30% 之外,更是支持了实时 CDC 同步场景。当然,最大的差别还是在于 SeaTunnel CDC 是一个支持 100 多个数据源的同步工具,它支持非结构化到结构化的自动转化,不仅支持数据库,也支持 Kafka、SaaS API 等复杂数据的实时抽取。更是有强大的 SeaTunnel-Web 界面,让大家拖拖拽拽就可以建立同步任务,同时可以监控处理各种同步情况。总之,SeaTunnel 的目标就是让异构数据源简单、高效、准确地集成到用户指定的目标端去。
** InfoQ:Snowflake、AWS 在 Zero-ETL 数据转换、流通和集成上有一些投入,您们如何看待这个技术方向?它会是未来吗?**
郭炜:Zero-ETL 和 DataMesh 类似,目标都是尽量不移动数据或者少量移动数据的情况下来达到实现查询数据结果的目标。在一些场景下,例如,KV 查询和 OLAP 联合查询或者 OLTP+OLAP 联合查询有一定优势。但是,数据应用的场景非常复杂,否则就不会出现几千种数据引擎来处理各种各样的事项,同时,数据集成不仅仅是数据库之间的数据集成,还包括 SaaS 到数据源,向量数据到 AI 引擎,各种各样新兴的场景会层出不穷,这些其实都是 DataMesh 和 Zero-ETL 无法处理的场景。所以,从我的观点来看,DataMesh 和 Zero-ETL 可以解决用户 20% 左右的数据集成的场景问题,随着 AI 和 SaaS 的流行,更多的场景需要更专业的数据集成工具来解决。
Apache SeaTunnel 的开源故事
** InfoQ:Apache SeaTunnel 是如何和开源结缘的?能具体说说其中的故事吗?**
高俊:SeaTunnel 的诞生。Apache SeaTunnel 开始叫做 Waterdrop,主要致力于更简单在不同数据源上使用 Spark、Flink 处理数据,后来遇到了郭炜和白鲸开源的代立冬,我们一眼看中了这个领域无限的空间。此时,Apache Sqoop 已经退役,Apache 基金会领域当中也没有一款可以替代 Sqoop 解决大数据同步生态的项目,而在国内 DataX 也只能支持批量同步数据源,同时数据源支持也有限,而在海外有 FiveTran、Airbyte 这些爆火的项目,在业界的确非常需要一个可以高效、简单、准确打通各种数据源的开源项目。
于是,在 Apache 董事会成员姜宁、欧洲 PMC Jean-Baptiste Onofré、Apache 大佬 Ted Liu 等人的支持下,SeaTunnel 进入到了 Apache 孵化器,成为一个专业的,以高效数据集成、打通各个数据源的 Apache 孵化项目。
进入 Apache 孵化器之后,SeaTunnel 得到了快速的发展,Connector 数量也从过去的 20 个变成现在的 100 多个连接器,涵盖了大部分公司使用的数据源,不仅是国内的 B 站、头条、新浪,连美国 JP Morgan 的用户都被如此多、高效的数据连接器吸引使用,印度第二大运营商 Bharti Airtel 更是在生产环境中使用了 SeaTunnel。
SeaTunnel 的第一个挑战。不过此时 SeaTunnel 也遇到它的第一个挑战,那就是曾经以 Spark、Flink 为核心引擎的时候,我们在大数据同步场景里多处受挫,例如,无法支持 CDC 场景下的表自动变更,同步几千个表的时候,Spark、Flink 要么都在一个任务里,任何一个表出问题,整个任务失败,要么就是一个表一个任务,资源和源数据库都受不了,SeaTunnel 用户在数据量大了之后苦不堪言。这时候,我提出一个想法,那就是建立 Apache SeaTunnel 自己的引擎——一个专门为数据同步集成而生的引擎。它不依赖于以计算为主的 Flink、Spark,可以自由地满足数据同步场景中的 Schema Evolution,错误数据采集,数据限流等,还可以节约 Flink、Spark 为复杂计算预留的内存、CPU slot,同时采用类似 Apache Arrow 的内存技术,在保证全局一致性前提下,最大限度提升数据传输效率。而且,社区小伙伴们给这个引擎起了一个很有想象力的名字,Zeta,它是宇宙里速度最快小行星的名字,意味着可以载着宇宙的数据快速穿梭于星际之间。(后来发现也是泽塔奥特曼的英文名,我想既可以帮助数据星际传输,如果遇到怪兽也可以打小怪兽吧 _)。
从零开始直接写一个引擎谈何容易,一遍一遍的设计讨论,一遍一遍地推翻原有设计,大概做了四到五版的设计和原型实现后,在 2022 年的 10 月份,第一个版本的 SeaTunnel Zeta 才发布了 Alpha 版。这个版本一经发布就技惊四座,不仅支持了 DataX 不支持的 CDC 场景,还在框架上支持 DDL 变更同步,性能更是好得出奇,比海外类似开源的产品要快 40 倍。SeaTunnel Zeta 的出现一下子打开了 Apache SeaTunnel 的天花板,无论将来有几千上万的数据源连接器,都可以乘坐着 Zeta 小星星以光速 1/3 的速度遨游宇宙了~
SeaTunnel 的第二个挑战,开源和开源商业界限怎么分?这时候,Apache SeaTunnel 的 Committer 们各个颇有大将风范,剑锋所指各种数据源,数据源连接器数量一下增长了 5 倍,从 2022 年 1 月份 20 个数据源变为 2022 年 12 月的 104 个数据源。
但是问题又来了,用户纷纷抱怨,写类 SQL 的代码还是太麻烦,普通人用不了,能不能更简单地用界面使用 SeaTunnel?的确,让数据同步能力平民化就是 SeaTunnel 这个项目建立的初衷。此时,已经加入白鲸开源的我跟白鲸开源的联合创始人代立冬商量,能不能把基于 SeaTunnel 的商业版 WhaleTunnel 的界面贡献给 Apache 社区,让更多的人拥更简单的数据同步的能力。一直推崇开源文化的开源积极分子代立冬十分明白一个简单易用的界面对于解决用户问题有多么的重要,可是如果界面也开源了,那么白鲸开源这家商业公司将来收入靠什么呢?怎么能养活这些热爱开源的人继续贡献开源呢?
我找到了白鲸开源商业合伙人,也是前 Informatica 中国区总经理李晨和运营合伙人聂励峰商量这个事情,虽然大家热爱开源,但是大家也要吃饭养家糊口啊...... 这次讨论非常激烈,持续了一整天。最终李晨讲到,“白鲸开源”的基因就是开源,如果我们为了商业订单,把能帮助到大家快速解决问题的核心功能闭源了,这样闭源和开源会对立,那么白鲸开源和 Informatica、Fivetran 这些闭源软件公司有什么区别?我们要走就走一条在中国持续开源的路,坚信在更多的用户对于开源产品的打磨,一定会让白鲸开源商业产品做的更好,而不是走一条闭源产品的路!
于是,在 2023 年一个春天的夜晚,几个人一致同意把商业 WhaleTunnel 的界面全部贡献到 SeaTunnel 当中,让更多的人具有更简单异构数据实时同步的能力。在后面 SeaTunnel 周例会上,我一公布这个消息,一下子好多用户都兴奋了,说我们就等着 web 开源了,赶紧做好,我们马上上线!(代立冬、李晨、聂励峰周会听到这里,浅浅一笑,偷偷地下线,不留功与名——如果将来这几个人出来拿着碗“化缘”,也请大家多多支持啊,支持他们就是支持 SeaTunnel 这些原创的开源力量了)。
SeaTunnel 毕业啦!过五关、斩六将,在 Apache 基金会 7 位 Mentor 的辅导下,Apache SeaTunnel 社区共加入了 28 位 Commiter、18 位 PMC,也在社区的共同努力下发布了 8 个 Apache Releases。通过透明的开发过程和开源的代码管理,Apache SeaTunnel 项目在社区中获得了广泛的参与。中间还克服了社区的建立和本土化、精力分配、团队协作和社区成长等重重困难和挑战,最终于 2023 年 6 月 1 日儿童节这一天,给所有社区的小儿童和大儿童们献上了儿童节的贺礼!
中国终于有了自己的开源数据同步集成的顶级项目啦!这是 SeaTunnel 的一大步,但只是中国开源的一小步,相信更多的优秀开源项目在中国如春笋般出现,中国的开源商业也可以支持中国开源的爱好者们更好地兼顾养家糊口和开源贡献!
** InfoQ:SeaTunnel 毕业成为首个国人主导的数据集成领域 Apache 基金会顶级项目,有什么经验可以分享?特别是在运营一个全球化的社区方面?**
高俊:就像我们加入一家新公司需要了解这家公司的文化一样,参与 Apache 开源项目之前,我们也需要了解 ASF 的文化。ASF 文化就是 The Apache Way。
深入进入开源就会发现,开源不只是开放源码这么简单的一件事,开源还关乎社区管理、社区活跃、社区沟通交流、社区文化等,这就需要我们对 Apache way 有更加深刻的理解。
鉴于此前的经验,Apache SeaTunnel 在进入 Apache 孵化器初期就对 Apache Way 的重要性有着深刻的理解,比如对于开源社区来说,Community Over Code 的理念要植根心中,为此也需要社区做出准备和努力,尽可能降低每个有兴趣参与项目人的门槛,甚至打造 0 门槛,比如制定社区激励计划,制作新手入门指南,精选 Good First Issue,重要 Feature 进展跟踪,通过定期的用户访谈获取反馈和优化建议,定期解答社区关于项目和社区的疑问等。
社区贡献不仅限于代码,非代码的贡献甚至有时会发挥比代码更加有价值的作用,比如利用自身影响力为项目引发关注做贡献,写作项目相关技术和非技术文章,参与社区组织的各种活动、在各种时机和场合为 Apache SeaTunnel“代言”,把它推荐给更多的用户等,都是参与社区的渠道。
同时,Community Over Code 还强调开放、交流、合作,Apache SeaTunnel 秉持着这些理念,坚持社区内与海内外社区保持沟通,相互学习交流,坚持与 Apache 社区建立沟通,所有讨论发生在邮件内,issue 中,并通过社区自媒体渠道公布项目和社区的重大进展和计划,让社区保持公开透明。
从进入孵化期至今,Apache SeaTunnel 先后与多个海内外开源项目举办线上线下 Meetup 20 余场,包括已先于 Apache SeaTunnel 顺利从 ASF 孵化器毕业的 Apache Shenyu、Apache InLong、Apache Linkis,Apache Doris、IoTDB、StarRocks、TDengine 等成熟开源项目,以及在美国、印度等海外地区与 Trino、APISIX、Shopee、ALC Indore 联合举办的 Meetup 等。社区之间的合作与交流推动开源技术的发展和应用,Apache SeaTunnel 与其他开源项目合作,共同解决了技术难题,有利于提升开源生态的整体水平,拓展了开源生态的边界。
Apache SeaTunnel 还积极参与国内外的技术大会和展览,展示开源项目和技术成果,通过与业界专家和开发者的交流,扩大项目的影响力和知名度。
经过时间的积累,社区已有了质的变化。从社区的邮件讨论、GitHub 的数据展示中,你会发现 Apache SeaTunnel 的社区开始真正变得活跃与多元化。
** InfoQ:在开源上,Apache SeaTunnel 还有哪些未来规划?**
高俊:主要是五个方面:文章来源:https://www.toymoban.com/news/detail-502085.html
- SeaTunnel 将进一步提高 Zeta 引擎的性能和稳定性,并将过去规划的 DDL 变更,错误数据处理,流速控制、多表同步等落地完成。
- SeaTunnel-Web 也将从 Alpha 状态进入 Release 状态,让大家可以直接从界面来定义、控制整个同步流程。
- 加强AGI组件配合关系,除了可以使用ChatGPT自动生成Connector之外,加强向量数据库,大模型 插件的打通,让现有100多种数据源无缝对接大模型。
- 完善和上下游生态的关系,与 Apache DolphinScheduler、Apache Airflow 等 Apache 生态的整合和互联互通。
- 在 Google Sheet、飞书、腾讯文档支持之后,加强 SaaS Connector 的构造,例如 ChatGPT、Salesforce、Workday 等。
本文由 白鲸开源 提供发布支持!文章来源地址https://www.toymoban.com/news/detail-502085.html
到了这里,关于SeaTunnel毕业!首个国人主导的数据集成项目成为Apache顶级项目的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[ChatGPT]意大利成为首个封禁ChatGPT的国家,这代表了什么](https://imgs.yssmx.com/Uploads/2024/02/459017-1.gif)