文章来源地址https://www.toymoban.com/news/detail-502161.html
文章来源:https://www.toymoban.com/news/detail-502161.html
| 任务一:完成Hadoop集群部署前环境的准备工作 1.1 虚拟机环境准备 1. 安装虚拟机 2. 克隆虚拟机 3. 修改网络配置 4. 修改主机名和映射 5. 关闭防火墙 1.2 安装JDK 1.3 安装Hadoop 1.4 集群配置 1. 编写集群分发脚本xsync 2. 集群部署规划 表 1.1
(1)核心配置文件 配置core-site.xml (2)HDFS配置文件 配置 hadoop-env.sh 配置 hadoop-site.xml (3)YARN配置文件 配置 yarn-env.sh 配置 yarn-site.xml (4)MapReduce配置文件 配置 mapred-env.sh 配置 mapred-site.xml
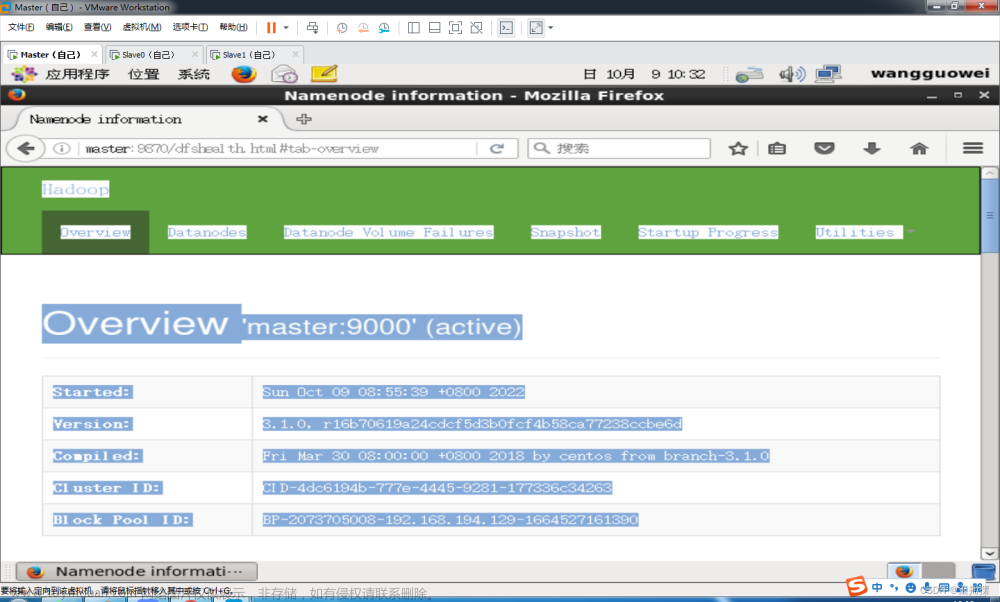
1.5 群起集群 1. 配置slaves 2. 启动集群 (1)如果集群是第一次启动,需要格式化NameNode [hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format (2)启动HDFS [hadoop@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh (3)启动YARN [hadoop@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh (4)使用jps分别查看三台虚拟机的节点 [hadoop@hadoop101 hadoop-2.7.2]$ jps (5)查看web端 http:192.168.2.122:50070/dfshealth.html#tab-overview 任务二:能够将本地文件存储到集群中 1. 上传小文件 [hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -put test/word.txt /user/hadoop/input1
[hadoop@hadoop101 hadoop-2.7.2]$bin/hadoop fs -put/opt/softw are/hadoop-2.7.2.tar.gz /user/hadoop/input1 3. 查看上传文件位置 任务三:能够从集群中下载文件到本地 [hadoop@hadoop101 hadoop-2.7.2]$ bin/hadoop fs -get /user/hadoop/input1/hadoop-2.7.2.tar.gz test/ 任务四:举例练习Hadoop的常用命令
(1)启动HDFS [hadoop@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh (2)启动YARN [hadoop@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -mkdir -p /user/had oop/input1
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -put test/word.txt /user/hadoop/input1
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -ls /user/hadoo p/input1/ [hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/hado op/input/word.txt
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoo p/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount/u ser/hadoop/input1/ /user/hadoop/output
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/hado op/output/*
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -get /user/hadoop/ output/part-r-00000 ./test/
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -rm -r /user/hadado op/output
(1)关闭HDFS [hadoop@hadoop101 hadoop-2.7.2]$ sbin/stop-dfs.sh (2)关闭YARN [hadoop@hadoop102 hadoop-2.7.2]$ sbin/stop-yarn.sh 任务五:编写程序,用MR计算单词个数
[hadoop@hadoop101 hadoop-2.7.2]$ mkdir test
[hadoop@hadoop101 test]$ touch word.txt
[hadoop@hadoop101 test]$ sudo vi word.txt
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -put test/word.txt /user/hadoop/input
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoo p/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount/u ser/hadoop/input/ /user/hadoop/output
[hadoop@hadoop101 hadoop-2.7.2]$cat test/part-r-00000 | ||||||||||||
| 出现问题:在从节点(Slave)执行命令jps后,发现没有运行DataNode。 问题原因:在启动Hadoop之前,进行了多次格式化,导致DataNode的ID发生了变化。 解决方案:格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。(先关闭namenode和datanode进程)或者让 NameNode与DataNode的ID一致 。 | ||||||||||||
| 无 | ||||||||||||
| 我在学习Hadoop过程中的体会和心得如下: Hadoop是一个庞大的生态系统,包含了很多的组件和工具,学习曲线比较陡峭。初学者最好从基础入手,先学习Hadoop的基本概念和核心组件,如HDFS和MapReduce等。 Hadoop的学习不仅是理论知识的积累,更需要实践和经验的积累。通过实际操作和开发Hadoop应用程序,才能更好地掌握和理解Hadoop的知识和技能。 Hadoop是一个分布式计算框架,需要具备一定的计算机编程技能。特别是对于开发MapReduce应用程序,需要掌握Java编程语言和基本的算法知识。 Hadoop的学习需要耐心和坚持不懈的精神,很多时候需要花费大量的时间和精力去理解和解决问题。但是,只要坚持下去,学习Hadoop的收获也是十分丰富的。 总之,学习Hadoop是一项具有挑战性的任务,需要花费不少时间和精力。但是,通过实践和不断的学习,我们可以掌握Hadoop的核心知识和技能,并为大数据时代做出贡献。 |
到了这里,关于大数据应用——工程实践III的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!