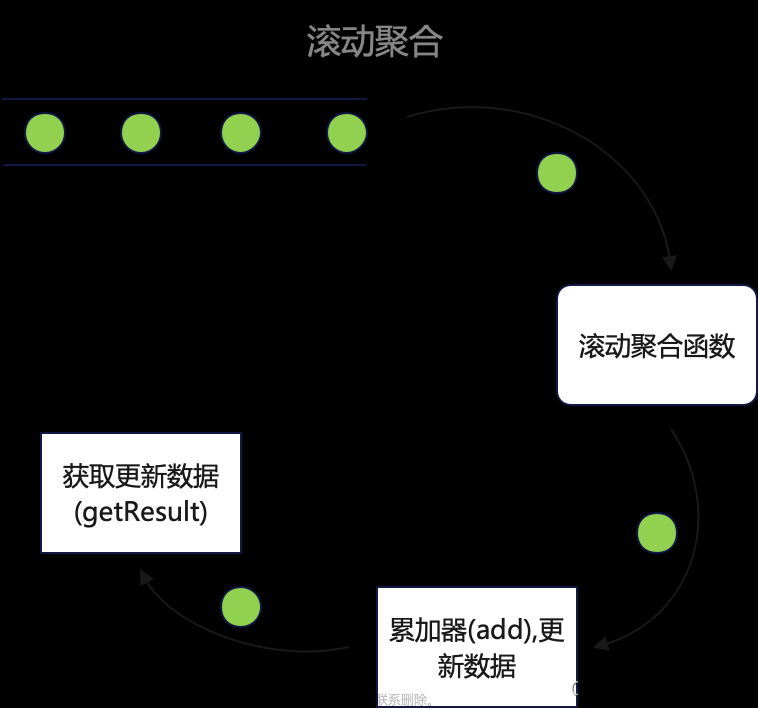
在Flink中max算子和maxBy算子都是用来求取最大值的,下面将结合代码介绍一下它俩的相同点和不同点
-
相同点
- 都是滚动聚合
- 都会根据代码的逻辑更新状态中记录的聚合值,并输出
-
不同点
-
max算子只会更新最大值的字段,maxBy算子会更新整条数据,下面就结合代码看和结果看一下相同点及区别
-
-
测试数据
小明,M,25 小花,W,27 小美,W,29 小强,M,24 小刚,M,29 小A,M,25 小B,W,27 小C,W,29 小D,M,24 小E,M,29 -
max算子public static void main(String[] args) throws Exception { // 创建流处理环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 读取数据文件 DataStreamSource<String> fileStreamSource = env.readTextFile("data/test/user.txt"); // 现将数据转成Tuple3形式(名,性别,年龄) SingleOutputStreamOperator<Tuple3<String, String, Integer>> mapStream = fileStreamSource.map((MapFunction<String, Tuple3<String, String, Integer>>) value -> { // 切割字符串 String[] split = value.split(","); // 将Tuple3返回 return Tuple3.of(split[0], split[1], Integer.parseInt(split[2])); }).returns(new TypeHint<Tuple3<String, String, Integer>>() {}); // 按照性别进行分组 KeyedStream<Tuple3<String, String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f1); // 使用max算子求最大值 SingleOutputStreamOperator<Tuple3<String, String, Integer>> maxStream = keyed.max(2); // 打印数据 maxStream.print(); env.execute(); -
结果
(小明,M,25) (小花,W,27) (小花,W,29) (小明,M,25) (小明,M,29) (小明,M,29) (小花,W,29) (小花,W,29) (小明,M,29) (小明,M,29) -
maxBy算子public static void main(String[] args) throws Exception { // 创建流处理环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 读取数据文件 DataStreamSource<String> fileStreamSource = env.readTextFile("data/test/user.txt"); // 现将数据转成Tuple3形式(名,性别,年龄) SingleOutputStreamOperator<Tuple3<String, String, Integer>> mapStream = fileStreamSource.map((MapFunction<String, Tuple3<String, String, Integer>>) value -> { // 切割字符串 String[] split = value.split(","); // 将Tuple3返回 return Tuple3.of(split[0], split[1], Integer.parseInt(split[2])); }).returns(new TypeHint<Tuple3<String, String, Integer>>() {}); // 按照性别进行分组 KeyedStream<Tuple3<String, String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f1); // 使用maxBy算子求最大值 SingleOutputStreamOperator<Tuple3<String, String, Integer>> maxStream = keyed.maxBy(2); // 打印数据 maxStream.print(); env.execute(); } -
结果文章来源:https://www.toymoban.com/news/detail-502330.html
(小明,M,25) (小花,W,27) (小美,W,29) (小明,M,25) (小刚,M,29) (小刚,M,29) (小美,W,29) (小美,W,29) (小刚,M,29) (小刚,M,29)
通过上面的结果数据首先我们就能确认max和maxBy两个算子都是滚动计算的.
我们再看不同点max算子计算的结果数据前面两个值始终没有发生变化(姓名,性别),变化的只有最后一个最大值,而maxBy算子则是整条数据都进行了更新,而且通过结果我们可以知道maxBy算子再获取最大值时,只有大于状态中记录的数据时才会更新整条数据,小于等于是不进行更新的.文章来源地址https://www.toymoban.com/news/detail-502330.html
到了这里,关于Flink中max和maxBy的区别及使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[flink 实时流基础]源算子和转换算子](https://imgs.yssmx.com/Uploads/2024/04/847286-1.png)