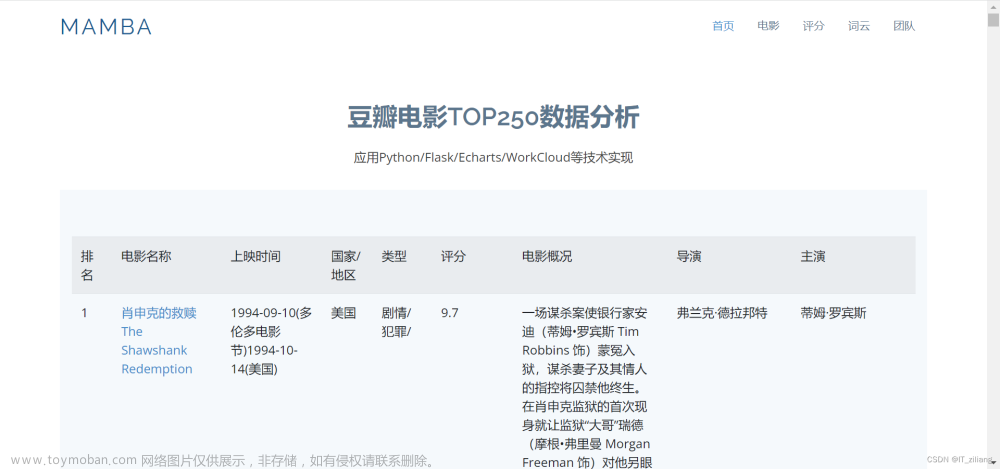
我们今天讲一个爬虫项目案例,实现对豆瓣电影top榜的爬取 。把爬取的数据存到我们电脑本地文件当中。通过这个项目可以让我们真正感受到爬虫的带给我们的乐趣。现在我来讲一下思路以及实现方法,因为豆瓣电影的这个反爬机制不高,所以我们可以通过这个案列快速上手,感受爬虫的乐趣!!!!
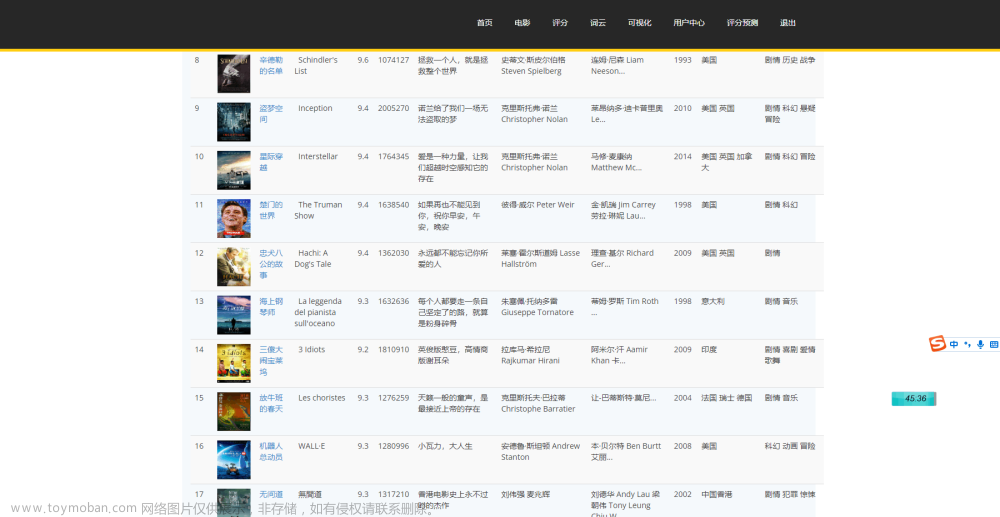
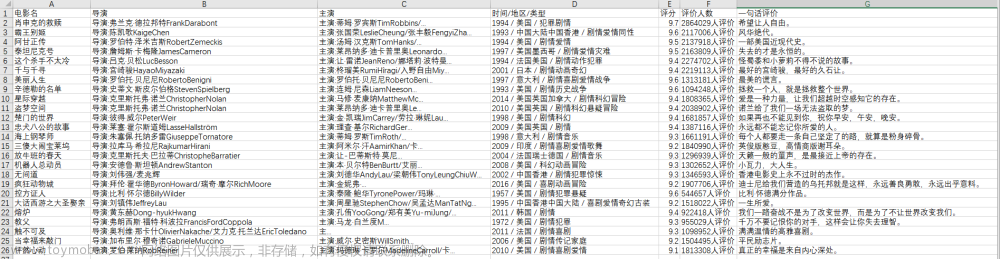
我们主要思路是爬取豆瓣电影Top250页面上的电影名称和评分,并将它们存储到本地文件或Excel文件中。
具体步骤如下:
发送HTTP请求获取豆瓣电影Top250页面的HTML内容。
使用BeautifulSoup库对HTML内容进行解析,获取每部电影的名称和评分。
将每部电影的名称和评分存储到一个列表中。
使用pandas库将列表中的数据存储到本地文件或Excel文件中。
在这个过程中,我们使用了以下模型和方法:
requests模块:用于发送HTTP请求获取网页内容。
BeautifulSoup库:用于解析HTML内容,提取所需的信息。
pandas库:用于将数据存储到本地文件或Excel文件中。
不多说 直接上代码,代码里我加上了最详细的步骤,看不懂,评论区告诉我!!!
import requests # 导入requests模块,用于发送HTTP请求
from bs4 import BeautifulSoup # 导入BeautifulSoup库,用于解析HTML
import pandas as pd # 导入pandas库,用于数据处理
url = 'https://movie.douban.com/top250' # 定义要爬取的网页URL
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'} # 定义HTTP请求头部信息,模拟浏览器行为
response = requests.get(url, headers=headers) # 发送HTTP请求,获取网页内容
soup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup库解析HTML内容
movies = soup.find_all('div', class_='info') # 获取所有电影信息块
movie_list = [] # 定义一个空列表,用于存储电影名称和评分
for movie in movies:
title = movie.find('span', class_='title').get_text() # 获取电影名称
rating = movie.find('span', class_='rating_num').get_text() # 获取电影评分
movie_list.append((title, rating)) # 将电影名称和评分添加到列表中
df = pd.DataFrame(movie_list, columns=['电影名称', '评分']) # 将列表转换为DataFrame格式,指定列名
df.to_excel('douban_top50.xlsx', index=False) # 将DataFrame存储到Excel文件中,不包括行索引

文章来源:https://www.toymoban.com/news/detail-502357.html
代码很少,所以还不赶快练起来!!!tips:要先导入我们要用的库哟!!!!文章来源地址https://www.toymoban.com/news/detail-502357.html
到了这里,关于python爬虫项目——豆瓣Top250的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://imgs.yssmx.com/Uploads/2024/02/797225-1.png)

![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)