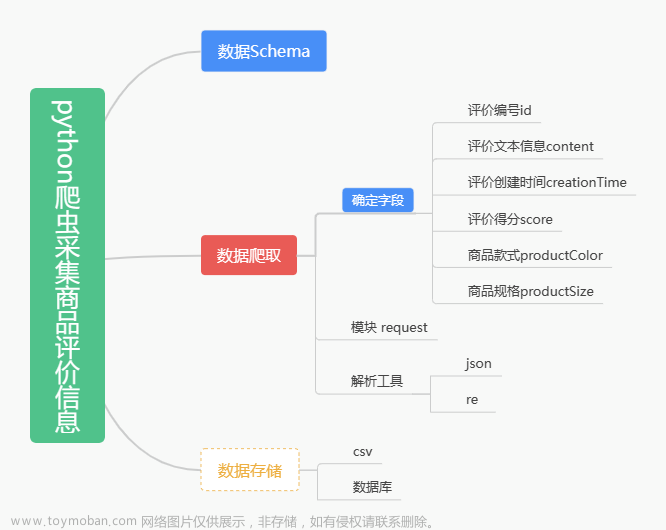
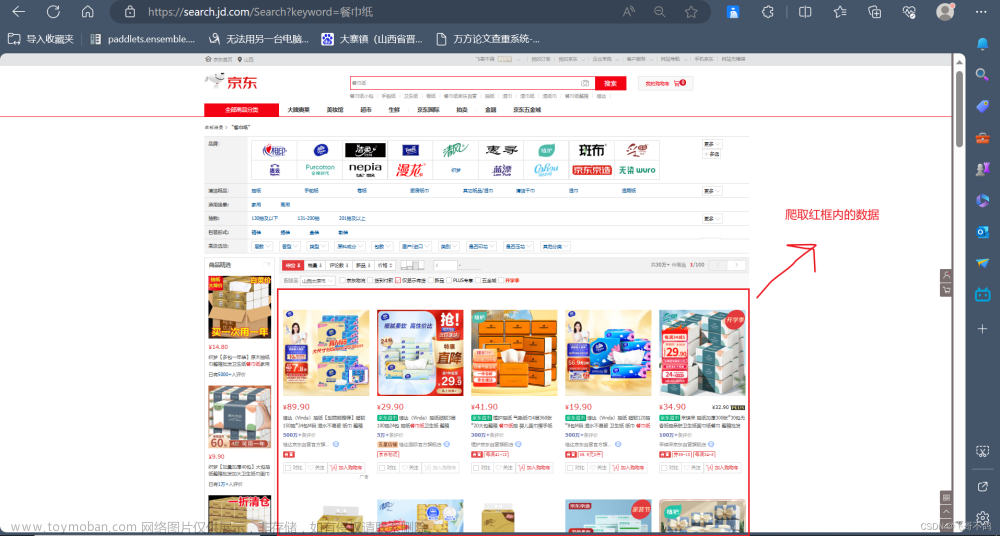
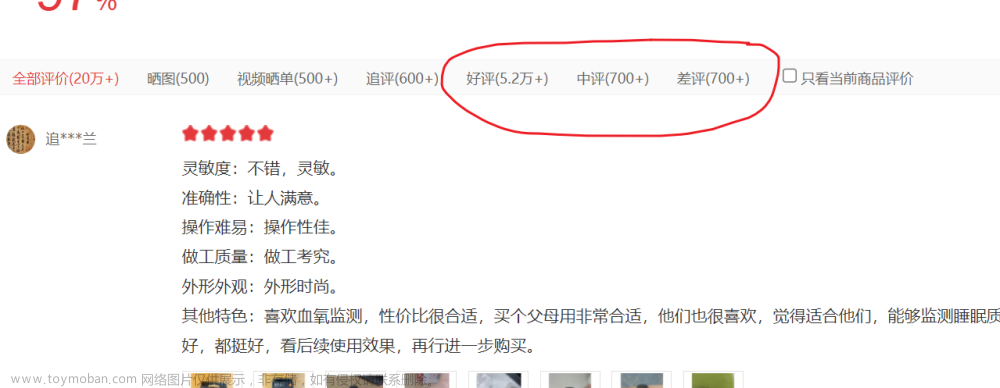
以小米手环7为例,分别爬取小米手环7用户评价中的好评、中评、差评
使用工具:PyCharm Community
需要python库:requests
安装方法:File-->Settings-->Project -->Python Interpreter
代码如下:
好评:
import requests
if __name__ == "__main__":
#爬取好评100页
for page in range(0,100):
url = 'https://club.jd.com/comment/productPageComments.action'
param = {
'productId': '100039939514',
'score': '3', #好评score
'sortType': '5',
'page': page,
'pageSize': '10',
'isShadowSku': '0',
'fold': '1',
}
#UA伪装
headers = {
'cookie': 'shshshfpa=353c3350-9f6e-c6e4-75c2-e45fb0638a20-1677122793; shshshfpb=cYvrYbQje1MA2t7vxC5UUEw; __jdv=76161171|direct|-|none|-|1679360388347; __jdu=1677051379551729066919; areaId=14; PCSYCityID=CN_340000_340100_0; shshshfpx=353c3350-9f6e-c6e4-75c2-e45fb0638a20-1677122793; __jda=122270672.1677051379551729066919.1677051379.1677240645.1679360388.14; __jdc=122270672; jsavif=1; shshshfp=560297ae18037fe111337616ab2a555f; token=06336cfeaa30940f5c417f6798e29f98,2,932978; __tk=115a0c213a52a38c2ce94507d97fc721,2,932978; ipLoc-djd=14-1116-3431-57939; 3AB9D23F7A4B3C9B=T6XOSS2CQO2OX3CXET3VGDVF7I5HMHLXB4ZJR7Y73ZLZJCFPBJOSJNGAPFVEW5DQB6OJQEHGFPLPICSY2LRQX6UUGM; jwotest_product=99; CA1AN5BV0CA8DS2EPC=166bb245180140fcb233e32ead6800cb; PCA9D23F7A4B3CSS=7fe8a2d8af887bd902df1a00848ab151; 3AB9D23F7A4B3CSS=jdd03T6XOSS2CQO2OX3CXET3VGDVF7I5HMHLXB4ZJR7Y73ZLZJCFPBJOSJNGAPFVEW5DQB6OJQEHGFPLPICSY2LRQX6UUGMAAAAMHAHEIWMQAAAAACMTZKWKC62MG3AX; _gia_d=1; shshshsID=55c4b556288dea72398a8eb93ef6dc03_8_1679362134063; __jdb=122270672.9.1677051379551729066919|14.1679360388; JSESSIONID=D6FE691B40A1D1D5386BAA5EDD77C29D.s1',
'referer': 'https://item.jd.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
response = requests.get(url=url, params=param, headers=headers)
for index in response.json()['comments']:
content = index['content']
print(content)
with open('good_comments2.txt', mode='a', encoding='utf-8') as fp:
fp.write(content)
fp.write('\n')中评:
import requests
if __name__ == "__main__":
#爬取中评55页
for page in range(0,55):
url = 'https://club.jd.com/comment/productPageComments.action'
param = {
'productId': '100023000435',
'score': '2', #中评score
'sortType': '5',
'page': page,
'pageSize': '10',
'isShadowSku': '0',
'fold': '1',
}
headers = {
'cookie': 'shshshfpa=353c3350-9f6e-c6e4-75c2-e45fb0638a20-1677122793; shshshfpb=cYvrYbQje1MA2t7vxC5UUEw; __jdv=76161171|direct|-|none|-|1679360388347; __jdu=1677051379551729066919; areaId=14; PCSYCityID=CN_340000_340100_0; shshshfpx=353c3350-9f6e-c6e4-75c2-e45fb0638a20-1677122793; __jda=122270672.1677051379551729066919.1677051379.1677240645.1679360388.14; __jdc=122270672; jsavif=1; shshshfp=560297ae18037fe111337616ab2a555f; token=06336cfeaa30940f5c417f6798e29f98,2,932978; __tk=115a0c213a52a38c2ce94507d97fc721,2,932978; ipLoc-djd=14-1116-3431-57939; 3AB9D23F7A4B3C9B=T6XOSS2CQO2OX3CXET3VGDVF7I5HMHLXB4ZJR7Y73ZLZJCFPBJOSJNGAPFVEW5DQB6OJQEHGFPLPICSY2LRQX6UUGM; jwotest_product=99; CA1AN5BV0CA8DS2EPC=166bb245180140fcb233e32ead6800cb; PCA9D23F7A4B3CSS=7fe8a2d8af887bd902df1a00848ab151; 3AB9D23F7A4B3CSS=jdd03T6XOSS2CQO2OX3CXET3VGDVF7I5HMHLXB4ZJR7Y73ZLZJCFPBJOSJNGAPFVEW5DQB6OJQEHGFPLPICSY2LRQX6UUGMAAAAMHAHEIWMQAAAAACMTZKWKC62MG3AX; _gia_d=1; shshshsID=55c4b556288dea72398a8eb93ef6dc03_8_1679362134063; __jdb=122270672.9.1677051379551729066919|14.1679360388; JSESSIONID=D6FE691B40A1D1D5386BAA5EDD77C29D.s1',
'referer': 'https://item.jd.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
response = requests.get(url=url, params=param, headers=headers)
for index in response.json()['comments']:
content = index['content']
with open('middle_comments.txt', mode='a', encoding='utf-8') as fp:
fp.write(content)
fp.write('\n')差评:
import requests
if __name__ == "__main__":
#爬取差评69页
for page in range(0,69):
url = 'https://club.jd.com/comment/productPageComments.action'
param = {
'productId': '100023203263',
'score': '1', #差评score
'sortType': '5',
'page': page,
'pageSize': '10',
'isShadowSku': '0',
'fold': '1',
}
headers = {
'cookie': 'shshshfpa=353c3350-9f6e-c6e4-75c2-e45fb0638a20-1677122793; shshshfpb=cYvrYbQje1MA2t7vxC5UUEw; __jdv=76161171|direct|-|none|-|1679360388347; __jdu=1677051379551729066919; areaId=14; PCSYCityID=CN_340000_340100_0; shshshfpx=353c3350-9f6e-c6e4-75c2-e45fb0638a20-1677122793; __jda=122270672.1677051379551729066919.1677051379.1677240645.1679360388.14; __jdc=122270672; jsavif=1; shshshfp=560297ae18037fe111337616ab2a555f; token=06336cfeaa30940f5c417f6798e29f98,2,932978; __tk=115a0c213a52a38c2ce94507d97fc721,2,932978; ipLoc-djd=14-1116-3431-57939; 3AB9D23F7A4B3C9B=T6XOSS2CQO2OX3CXET3VGDVF7I5HMHLXB4ZJR7Y73ZLZJCFPBJOSJNGAPFVEW5DQB6OJQEHGFPLPICSY2LRQX6UUGM; jwotest_product=99; CA1AN5BV0CA8DS2EPC=166bb245180140fcb233e32ead6800cb; PCA9D23F7A4B3CSS=7fe8a2d8af887bd902df1a00848ab151; 3AB9D23F7A4B3CSS=jdd03T6XOSS2CQO2OX3CXET3VGDVF7I5HMHLXB4ZJR7Y73ZLZJCFPBJOSJNGAPFVEW5DQB6OJQEHGFPLPICSY2LRQX6UUGMAAAAMHAHEIWMQAAAAACMTZKWKC62MG3AX; _gia_d=1; shshshsID=55c4b556288dea72398a8eb93ef6dc03_8_1679362134063; __jdb=122270672.9.1677051379551729066919|14.1679360388; JSESSIONID=D6FE691B40A1D1D5386BAA5EDD77C29D.s1',
'referer': 'https://item.jd.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
response = requests.get(url=url, params=param, headers=headers)
for index in response.json()['comments']:
content = index['content']
with open('bad_comments.txt', mode='a', encoding='utf-8') as fp:
fp.write(content)
fp.write('\n')其中重要参数来源:
打开开发者工具,快捷键F12键,或鼠标右键-->检查-->网络
url = 'https://club.jd.com/comment/productPageComments.action'
不包括?号后参数
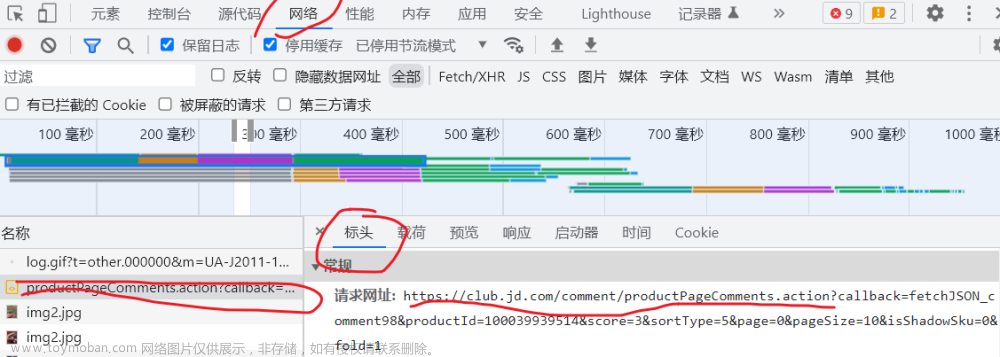
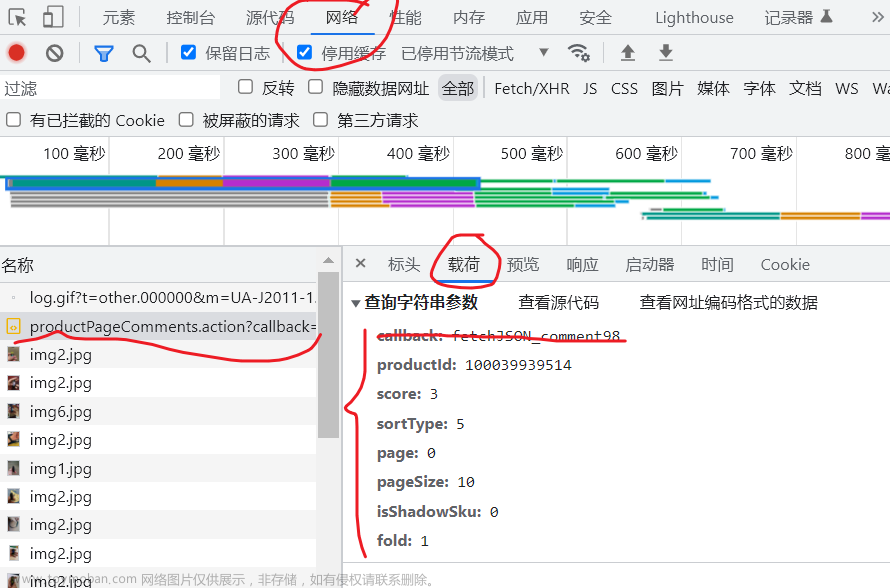
param参数:文章来源:https://www.toymoban.com/news/detail-502882.html
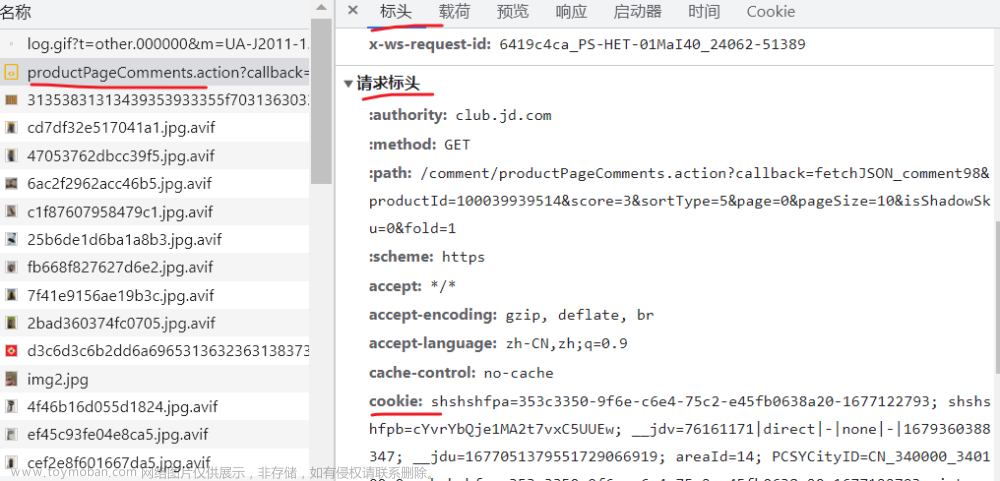
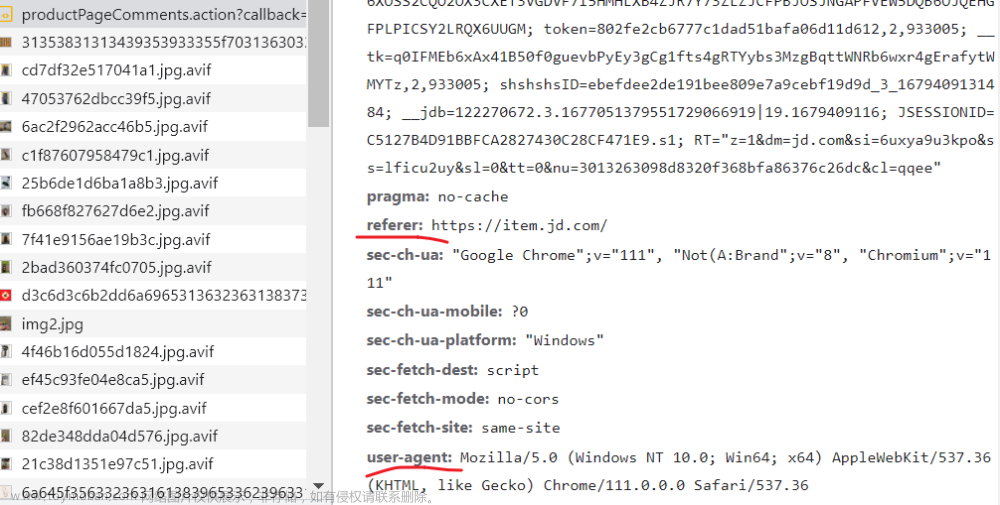
headers:标头-->请求标头:cookie、referer、user-agent文章来源地址https://www.toymoban.com/news/detail-502882.html
到了这里,关于爬虫——python爬取京东商品用户评价的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!