系列文章目录
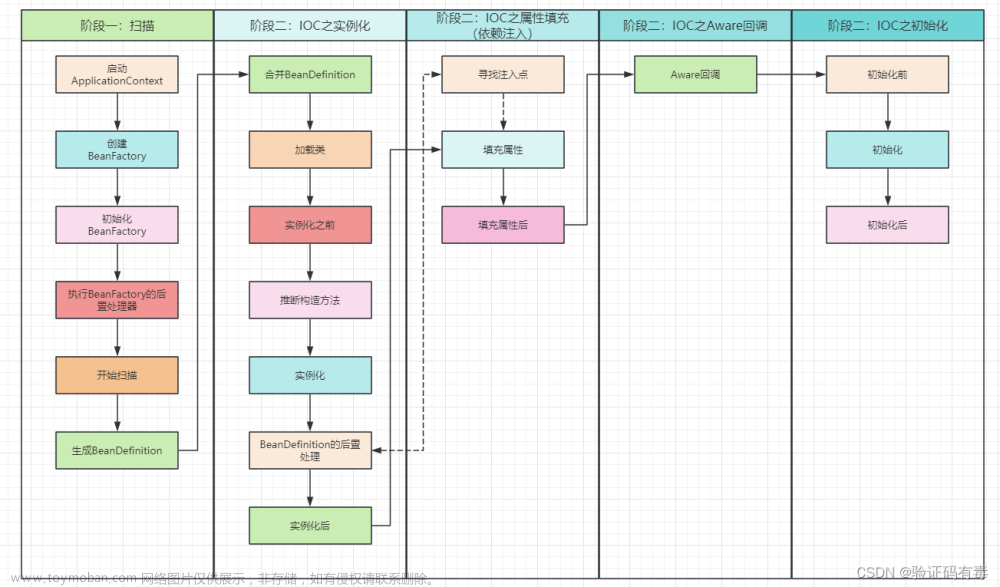
扫描包
ClassPathBeanDefinitionScanner.java
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 解析@Lazy、@Primary、@DependsOn、@Role、@Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检查Spring容器中是否已经存在该beanName
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 注册
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
寻找候选的组件
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
ClassPathScanningCandidateComponentProvider.java
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
通过组件索引寻找
这里的componentsIndex 在初始化的时候会尝试解析 META-INF/spring.components 文件中的配置信息
把断点打在 ClassPathScanningCandidateComponentProvider的setResourceLoader方法上调试可以看到堆栈

可以看到,的确是初始化的时候加载的信息,然后进入CandidateComponentsIndex loadIndex(@Nullable ClassLoader classLoader)方法。
@Nullable
public static CandidateComponentsIndex loadIndex(@Nullable ClassLoader classLoader) {
ClassLoader classLoaderToUse = classLoader;
if (classLoaderToUse == null) {
classLoaderToUse = CandidateComponentsIndexLoader.class.getClassLoader();
}
return cache.computeIfAbsent(classLoaderToUse, CandidateComponentsIndexLoader::doLoadIndex);
}
重点是后面的最后的cache.computeIfAbsent(classLoaderToUse, CandidateComponentsIndexLoader::doLoadIndex),对Map.computeIfAbsent()不清楚的可以点击链接看看 computeIfAbsent方法。然后可以看doLoadIndex方法
@Nullable
private static CandidateComponentsIndex doLoadIndex(ClassLoader classLoader) {
if (shouldIgnoreIndex) {
return null;
}
try {
Enumeration<URL> urls = classLoader.getResources(COMPONENTS_RESOURCE_LOCATION);
if (!urls.hasMoreElements()) {
return null;
}
List<Properties> result = new ArrayList<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
result.add(properties);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + result.size() + "] index(es)");
}
int totalCount = result.stream().mapToInt(Properties::size).sum();
return (totalCount > 0 ? new CandidateComponentsIndex(result) : null);
}
catch (IOException ex) {
throw new IllegalStateException("Unable to load indexes from location [" +
COMPONENTS_RESOURCE_LOCATION + "]", ex);
}
}
这里的shouldIgnoreIndex可以通过配置spring.properties文件中的spring.index.ignore属性设置true或者false,默认为false。
然后加载spring.components文件,如果属性数量大于0,最后this.componentsIndex将得到值,否则为null。
回到之前的寻找候选组件的方法
此时this.componentsIndex有值,将不会再走扫描包路径下的所有组件,而是直接通过组件索引和包路径查找匹配的组件
private Set<BeanDefinition> addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
Set<String> types = new HashSet<>();
for (TypeFilter filter : this.includeFilters) {
// Component注解
String stereotype = extractStereotype(filter);
if (stereotype == null) {
throw new IllegalArgumentException("Failed to extract stereotype from " + filter);
}
types.addAll(index.getCandidateTypes(basePackage, stereotype));
}
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (String type : types) {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(type);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(metadataReader.getResource());
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Using candidate component class from index: " + type);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + type);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because matching an exclude filter: " + type);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
首先会经过this.includeFilters过滤一遍,this.includeFitters在初始化的时候会默认加上三个注解类型过滤分别是
- org.springframework.stereotype.Component
- javax.annotation.ManagedBean
- javax.inject.Named
将匹配includeFitters过滤器的才会加入其中进入下一步。再遍历所有类,通过ASM技术读取得到类的元数据信息
然后isCandidateComponent(metadataReader)用类的元数据判断是否符合候选组件
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
// 符合includeFilters的会进行条件匹配,通过了才是Bean,也就是先看有没有@Component,再看是否符合@Conditional
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
这里用excludeFilters和includeFilters进行过滤匹配,只有两个都通过了才会看看是否符合@Conditional,接下来重点是shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase)方法,如果没有@Conditional注解将直接返回false ,也就是不要跳过。
public boolean shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase) {
if (metadata == null || !metadata.isAnnotated(Conditional.class.getName())) {
return false;
}
if (phase == null) {
if (metadata instanceof AnnotationMetadata &&
ConfigurationClassUtils.isConfigurationCandidate((AnnotationMetadata) metadata)) {
return shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION);
}
return shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN);
}
List<Condition> conditions = new ArrayList<>();
for (String[] conditionClasses : getConditionClasses(metadata)) {
for (String conditionClass : conditionClasses) {
Condition condition = getCondition(conditionClass, this.context.getClassLoader());
conditions.add(condition);
}
}
AnnotationAwareOrderComparator.sort(conditions);
for (Condition condition : conditions) {
ConfigurationPhase requiredPhase = null;
if (condition instanceof ConfigurationCondition) {
requiredPhase = ((ConfigurationCondition) condition).getConfigurationPhase();
}
if ((requiredPhase == null || requiredPhase == phase) && !condition.matches(this.context, metadata)) {
return true;
}
}
return false;
}
下面是一个创建ScannedGenericBeanDefinition的方法
里面是将className设置到BeanDefinition中,并不是class对象,这是因为还没加载class,应该在需要Bean的时候加载,所以开始只是简单的赋值className
/**
* Create a new ScannedGenericBeanDefinition for the class that the
* given MetadataReader describes.
* @param metadataReader the MetadataReader for the scanned target class
*/
public ScannedGenericBeanDefinition(MetadataReader metadataReader) {
Assert.notNull(metadataReader, "MetadataReader must not be null");
this.metadata = metadataReader.getAnnotationMetadata();
setBeanClassName(this.metadata.getClassName());
setResource(metadataReader.getResource());
}
然后ConfigurationClassUtils.isConfigurationCandidate(AnnotationMetadata metadata)判断是否是lite配置类
public static boolean isConfigurationCandidate(AnnotationMetadata metadata) {
// Do not consider an interface or an annotation...
if (metadata.isInterface()) {
return false;
}
// Any of the typical annotations found?
// 只要存在@Component、@ComponentScan、@Import、@ImportResource四个中的一个,就是lite配置类
for (String indicator : candidateIndicators) {
if (metadata.isAnnotated(indicator)) {
return true;
}
}
// Finally, let's look for @Bean methods...
// 只要存在@Bean注解了的方法,就是lite配置类
return hasBeanMethods(metadata);
}
只要存在@Component、@ComponentScan、@Import、@ImportResource四个中的一个,或者存在@Bean注解的方法,就是lite配置类。最后判断是否满足匹配所有Condition,满足则不跳过,一个不满足则跳过。
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
最后会再次进行判断是否是候选组件,只有满足条件才会加入候选,条件:
1、类是否独立?
public boolean isIndependent() {
// 如果是内部类,enclosingClassName会存outClassName
// 如果是static的内部类,则independentInnerClass
return (this.enclosingClassName == null || this.independentInnerClass);
}
也就是判断是否是顶级类,或者静态内部类?如果是不是内部类或者是静态内部类,那这个类就是独立的。
2、类是否是具体的?
/**
* Return whether the underlying class represents a concrete class,
* i.e. neither an interface nor an abstract class.
*/
default boolean isConcrete() {
return !(isInterface() || isAbstract());
}
也就是 如果是接口或者抽象类,则返回false ,如果是具体类,则返回true。
3、类如果是抽象类,类方法上是否有@Lookup注解
如果类是抽象类,但是类有方法上含有@Lookup注解,则也满足称为候选组件的条件。如果对@Lookup不了解的可以看这个博客。
前面三个条件只要满足条件1,还有条件2、3其中一个则能称为候选组件
通过包路径扫描所有候选组件
这里是通过getResourcePatternResolver()方法获得一个PathMatchingResourcePatternResolver对象然后找到所有和路径匹配的资源。下面的步骤和通过组件索引寻找候选组件的步骤相同。
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 获取basePackage下所有的文件资源
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// excludeFilters、includeFilters判断
if (isCandidateComponent(metadataReader)) { // @Component-->includeFilters判断
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
生成Bean的名字
在上面已经寻找到所有的候选组件,然后将遍历这些候选组件,首先是解析组件获得Scope数据然后赋值,接下来就是生成Bean的名字了
@Override
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
if (definition instanceof AnnotatedBeanDefinition) {
// 获取注解所指定的beanName
String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);
if (StringUtils.hasText(beanName)) {
// Explicit bean name found.
return beanName;
}
}
// Fallback: generate a unique default bean name.
return buildDefaultBeanName(definition, registry);
}
首先是判断注解上有没有指定beanName,如果能取到则返回beanName,如果注解上没有则生成一个BeanName
protected String buildDefaultBeanName(BeanDefinition definition) {
String beanClassName = definition.getBeanClassName();
Assert.state(beanClassName != null, "No bean class name set");
String shortClassName = ClassUtils.getShortName(beanClassName);
return Introspector.decapitalize(shortClassName);
}
生成默认的BeanName,首先获得BeanClassName,也就是去取beanClass。因为beanClass的类型是Object,开始扫描的时候会赋值String,所以这里会进行判断。如果beanClass是class对象则转为Class对象再getName(),否则转String返回
@Override
@Nullable
public String getBeanClassName() {
Object beanClassObject = this.beanClass;
if (beanClassObject instanceof Class) {
return ((Class<?>) beanClassObject).getName();
}
else {
return (String) beanClassObject;
}
}
这时候再将长的路径名字截取得到后面的类名,再通过JDK的Introspector.decapitalize(String name)方法获得默认生成的类名
解析设置BeanDefinition信息

postProcessBeanDefinition是设置BeanDefinition的默认值,processCommonDefinitionAnnotations是解析是否有@Lazy、@Primary、@DependsOn、@Role、@Description注解
检查Spring容器中是否已经存在该beanName
首先检查Spring容器是否已经包含该beanName了,如果不包含,直接返回true
protected boolean checkCandidate(String beanName, BeanDefinition beanDefinition) throws IllegalStateException {
if (!this.registry.containsBeanDefinition(beanName)) {
return true;
}
BeanDefinition existingDef = this.registry.getBeanDefinition(beanName);
BeanDefinition originatingDef = existingDef.getOriginatingBeanDefinition();
if (originatingDef != null) {
existingDef = originatingDef;
}
// 是否兼容,如果兼容返回false表示不会重新注册到Spring容器中,如果不冲突则会抛异常。
if (isCompatible(beanDefinition, existingDef)) {
return false;
}
throw new ConflictingBeanDefinitionException("Annotation-specified bean name '" + beanName +
"' for bean class [" + beanDefinition.getBeanClassName() + "] conflicts with existing, " +
"non-compatible bean definition of same name and class [" + existingDef.getBeanClassName() + "]");
}
如果Spring容器包含了,则先获取Spring容器中的BeanDefinition最原始的BeanDefinition,然后查看两个BeanDefinition是否兼容,如果兼容返回false表示不会重新注册到Spring容器中,如果不冲突则会抛异常。查看是否兼容,首先是通过比较资源文件是否是同一个,如果不同再看是否是同一个BeanDefinition对象,只要满足其中一个条件那就是兼容的。如果同一个组件被扫描多次,则会出现Spring容器已注册该Bean,而且兼容的情况。
protected boolean isCompatible(BeanDefinition newDefinition, BeanDefinition existingDefinition) {
return (!(existingDefinition instanceof ScannedGenericBeanDefinition) || // explicitly registered overriding bean
(newDefinition.getSource() != null && newDefinition.getSource().equals(existingDefinition.getSource())) || // scanned same file twice
newDefinition.equals(existingDefinition)); // scanned equivalent class twice
}
注册BeanDefinition
经过多次检查,而且Spring容器没有注册该Bean,现在则会注册
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
注册将BeanDefinition对象放进beanDefinitionMap中
注册完beanDefinition还会注册BeanName的别名
实例化非懒加载的单例Bean
先为上下文初始化ConversionService(类型转换器),如果BeanFactory存在名字脚conversionService的Bean,则设置BeanFactory的conversionService属性。在Spring有关类型转换器的可以看我的这篇文章:Spring源码ConversionService解析
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// Initialize conversion service for this context.
// 如果BeanFactory中存在名字叫conversionService的Bean,则设置为BeanFactory的conversionService属性
// ConversionService是用来进行类型转化的
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
// Register a default embedded value resolver if no BeanFactoryPostProcessor
// (such as a PropertySourcesPlaceholderConfigurer bean) registered any before:
// at this point, primarily for resolution in annotation attribute values.
// 设置默认的占位符解析器 ${xxx} ---key
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
// Initialize LoadTimeWeaverAware beans early to allow for registering their transformers early.
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
// Allow for caching all bean definition metadata, not expecting further changes.
beanFactory.freezeConfiguration();
// Instantiate all remaining (non-lazy-init) singletons.
// 实例化非懒加载的单例Bean
beanFactory.preInstantiateSingletons();
}
真正实例化非懒加载的单例Bean是在beanFactory.preInstantiateSingletons()
@Override
public void preInstantiateSingletons() throws BeansException {
if (logger.isTraceEnabled()) {
logger.trace("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
for (String beanName : beanNames) {
// 获取合并后的BeanDefinition
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
if (isFactoryBean(beanName)) {
// 获取FactoryBean对象
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
// 创建真正的Bean对象(getObject()返回的对象)
getBean(beanName);
}
}
}
else {
// 创建Bean对象
getBean(beanName);
}
}
}
// 所有的非懒加载单例Bean都创建完了后
// Trigger post-initialization callback for all applicable beans...
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
StartupStep smartInitialize = this.getApplicationStartup().start("spring.beans.smart-initialize")
.tag("beanName", beanName);
SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
smartInitialize.end();
}
}
}
获得所有BeanDefinitionName,遍历每一个BeanDefinitionName,先获取合并后的BeanDefinition
protected RootBeanDefinition getMergedLocalBeanDefinition(String beanName) throws BeansException {
// Quick check on the concurrent map first, with minimal locking.
RootBeanDefinition mbd = this.mergedBeanDefinitions.get(beanName);
if (mbd != null && !mbd.stale) {
return mbd;
}
return getMergedBeanDefinition(beanName, getBeanDefinition(beanName));
}
合并BeanDefinition
这里会进行合并BeanDefinition
参数:
-
beanName:要获取合并Bean定义的Bean名称。 -
bd:要合并的原始Bean定义。 -
containingBd:包含当前Bean定义的父级Bean定义。如果没有父级Bean定义,则为null。
protected RootBeanDefinition getMergedBeanDefinition(
String beanName, BeanDefinition bd, @Nullable BeanDefinition containingBd)
throws BeanDefinitionStoreException {
synchronized (this.mergedBeanDefinitions) {
RootBeanDefinition mbd = null;
RootBeanDefinition previous = null;
// Check with full lock now in order to enforce the same merged instance.
if (containingBd == null) {
mbd = this.mergedBeanDefinitions.get(beanName);
}
if (mbd == null || mbd.stale) {
previous = mbd;
if (bd.getParentName() == null) {
// Use copy of given root bean definition.
if (bd instanceof RootBeanDefinition) {
mbd = ((RootBeanDefinition) bd).cloneBeanDefinition();
}
else {
mbd = new RootBeanDefinition(bd);
}
}
else {
// Child bean definition: needs to be merged with parent.
// pbd表示parentBeanDefinition
BeanDefinition pbd;
try {
String parentBeanName = transformedBeanName(bd.getParentName());
if (!beanName.equals(parentBeanName)) {
pbd = getMergedBeanDefinition(parentBeanName);
}
else {
BeanFactory parent = getParentBeanFactory();
if (parent instanceof ConfigurableBeanFactory) {
pbd = ((ConfigurableBeanFactory) parent).getMergedBeanDefinition(parentBeanName);
}
else {
throw new NoSuchBeanDefinitionException(parentBeanName,
"Parent name '" + parentBeanName + "' is equal to bean name '" + beanName +
"': cannot be resolved without a ConfigurableBeanFactory parent");
}
}
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanDefinitionStoreException(bd.getResourceDescription(), beanName,
"Could not resolve parent bean definition '" + bd.getParentName() + "'", ex);
}
// Deep copy with overridden values.
// 子BeanDefinition的属性覆盖父BeanDefinition的属性,这就是合并
mbd = new RootBeanDefinition(pbd);
mbd.overrideFrom(bd);
}
// Set default singleton scope, if not configured before.
if (!StringUtils.hasLength(mbd.getScope())) {
mbd.setScope(SCOPE_SINGLETON);
}
// A bean contained in a non-singleton bean cannot be a singleton itself.
// Let's correct this on the fly here, since this might be the result of
// parent-child merging for the outer bean, in which case the original inner bean
// definition will not have inherited the merged outer bean's singleton status.
if (containingBd != null && !containingBd.isSingleton() && mbd.isSingleton()) {
mbd.setScope(containingBd.getScope());
}
// Cache the merged bean definition for the time being
// (it might still get re-merged later on in order to pick up metadata changes)
if (containingBd == null && isCacheBeanMetadata()) {
this.mergedBeanDefinitions.put(beanName, mbd);
}
}
if (previous != null) {
copyRelevantMergedBeanDefinitionCaches(previous, mbd);
}
return mbd;
}
}
先检查在mergedBeanDefinitions里面是否已经存在合并的Bean定义
如果没有已经合并的Bean的定义,则进行合并操作,先看看有没有父级Bean,如果没有为null,则直接使用当前Bean定义,当前Bean如果是属于RootBeanDefinition就直接克隆一个,不属于就用这个BeanDefinition new一个新的RootBeanDefinition,注意:这里是深拷贝。
这里是有父级Bean的情况了,这里是定义了一个parentBeanDefinition。先把parentName用transformedBeanName方法转化了一下,转成真正的parentBeanName。这里是去掉了所有&符号,和如果是别名最后会取得主要的名字。然后开始找parentBeanDefinition。
这里使用了递归的方式,parentBeanDefinition也会和它的父BeanDefinition先合并。
这里开始合并操作,先用parentBeanDefinition创建一个RootBeanDefinition对象赋值给目前还为null的mbd,然后再用子BeanDefinition重写被父BeanDefinition 赋值的mbd的属性,这就是合并。
最后将合并完成的mbd(mergedBeanDefinition)做最后的处理。赋值Scope属性,然后将合并后的mbd加入缓存中。
创建非懒加载单例Bean
接下来会根据BeanDefinition是否抽象是否为单例和是否是非懒加载来判断是否要实例化。注意这里的抽象是指Bean的抽象,而不是类的抽象。如果一个Bean定义被标记为抽象,那么它不能被实例化,只能作为其他非抽象Bean定义的父类或基类使用。 文章来源:https://www.toymoban.com/news/detail-503023.html
文章来源:https://www.toymoban.com/news/detail-503023.html
在Spring框架中将Bean定义为抽象的三种方式:文章来源地址https://www.toymoban.com/news/detail-503023.html
-
通过XML配置文件:在XML配置文件中,可以使用元素的
abstract属性将Bean定义为抽象。将abstract属性设置为true表示该Bean定义为抽象,不能被实例化。例如:
<bean id="myBean" class="com.example.MyBean" abstract="true">
<!-- Bean的属性配置 -->
</bean>
-
通过Java配置类(
@Configuration):使用Spring的Java配置类,可以使用@Bean方法将Bean定义为抽象。在Java配置类中,可以使用@Bean方法的@Bean注解的abstract属性将Bean定义为抽象。将abstract属性设置为true表示该Bean定义为抽象。例如:
@Configuration
public class AppConfig {
@Bean(abstract = true)
public MyBean myBean() {
// Bean的配置
return new MyBean();
}
}
- 通过编程方式:在编写Java代码时,可以使用Spring的编程方式将Bean定义为抽象。通过
AbstractBeanDefinition的setAbstract(true)方法,可以将Bean定义为抽象。例如:
GenericBeanDefinition beanDefinition = new GenericBeanDefinition();
beanDefinition.setBeanClass(MyBean.class);
beanDefinition.setAbstract(true);
// 将Bean定义注册到Bean工厂中
BeanDefinitionRegistry registry = ...; // 获取Bean定义注册器
registry.registerBeanDefinition("myBean", beanDefinition);
到了这里,关于Spring之Bean生命周期源码解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!