GitHub
1.介绍
1.1 挑战
- 视觉转换器的输入单元,即图像补丁,没有预先存在的词汇。
- 预测遮罩面片的原始像素往往会在预训练短程依赖性和高频细节上浪费建模能力
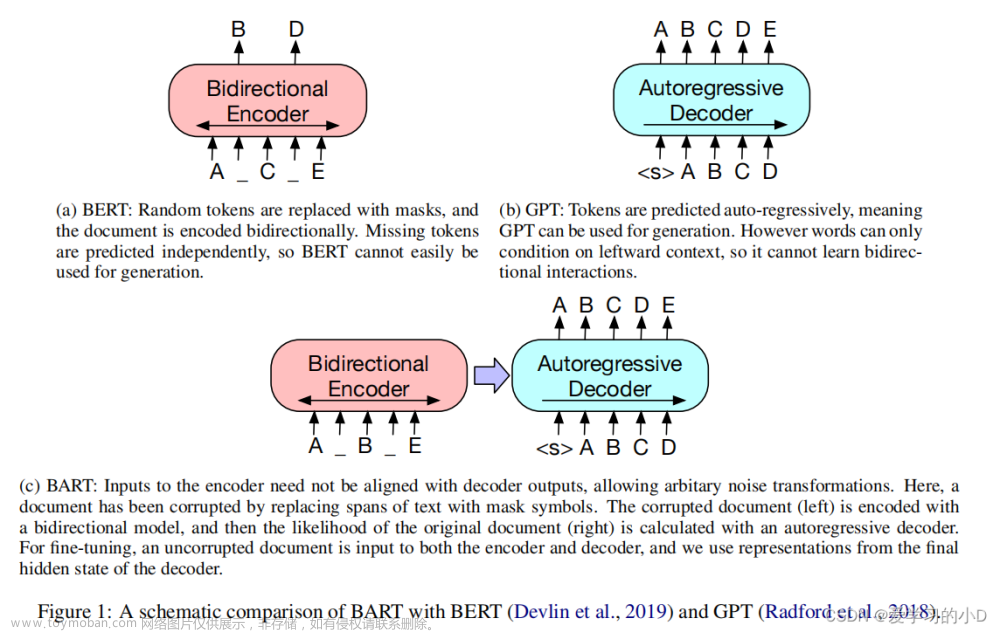
1.2 回顾一下Bert的基本架构和流程
- 输入编码:通过tokenizer将输入的文本中的每个单词转换为固定维度的向量表示
- 输入Transformer 编码器:使用多层的 Transformer 编码器来捕捉输入文本的上下文信息。
1.3 重点把握
- 怎么tokenize:通过DiscreteVAE(代码中使用的是Dalle_VAE)的潜在code获得的!
- 怎么将图片打上掩码?随机屏蔽一定比例的图像补丁!
- 网络学习的是什么?视觉标记!
2.方法

图一
2.1 图片表示
2.1.1 图片PATCH化
和vit基本相同,将每个224×224的图像分割成14×14的图像块网格
2.1.2 视觉token表示
将图像表示为“图像标记器”获得的离散标记序列,而不是原始像素。
使用离散变分自动编码器(dVAE)学习的图像标记器。视觉标记学习过程中有两个模块,即标记器和解码器。
- 标记器:将图像像素x映射为离散标记z
- 解码器:基于视觉标记z来重建输入图像x
由于潜在的视觉表征是离散的,因此模型训练是不可微的。
2.2 骨干网络:transformer
- 为输入序列预先准备了一个特殊token[S](图一左下角)
- 将标准可学习1D位置embeddings添加到补丁embeddings.
- 编码器其实就是L层的transform
- 最后一层的输出被用作图像块的编码表示
2.3 预训练BEIT
- 给定一个输入图像x,我们将其拆分为N个图像块,并将其标记为N个视觉标记。我们随机屏蔽了大约40%的图像块。用可学习嵌入e[M]∈RD替换屏蔽的块。
- mask的图像块被馈送到L层变换器。最终的隐藏向量被视为输入补丁的编码表示。
- 使用softmax分类器来预测相应的视觉标记
预训练的目标是在给定损坏图像的情况下最大化正确视觉标记的对数似然性:

三.代码

核心代码如上图所示,输入的图片通过d_vae(代码中使用的是Dalle_VAE)来获得一个编码表示,通过一个Vit获得预测的图像块的编码表示
3.1 dataset
在上图中,一个batch得到三个输出:
samples, images, bool_masked_pos = batch数据集的构建只有短短四行
def build_beit_pretraining_dataset(args):
transform = DataAugmentationForBEiT(args)
print("Data Aug = %s" % str(transform))
return ImageFolder(args.data_path, transform=transform)

DataAugmentationForBEiT前两个还好说,分别是vit和vae的数据处理,第三个是用来随机生成mask的。
3.2 视觉token表示

其实就是这个部分
with torch.no_grad():
input_ids = d_vae.get_codebook_indices(images).flatten(1)
bool_masked_pos = bool_masked_pos.flatten(1).to(torch.bool)
labels = input_ids[bool_masked_pos]通过DiscreteVAE(代码中使用的是Dalle_VAE)获得整张图片的code
codebook:这里的Codebook类似于一张表,一本词典,或者主成分分析里面的主成分向量。【参考深度量化学习中提到的codebook是什么意思?有点抽象但是我感觉意思和味道是对的】
【挖个小坑】VAE系列后面应该会读一读论文
3.3 图像变换器
其实就是加上了cls_token和mask_token的vit和一个线性层用来预测图像块的编码表示(code)文章来源:https://www.toymoban.com/news/detail-503128.html
 文章来源地址https://www.toymoban.com/news/detail-503128.html
文章来源地址https://www.toymoban.com/news/detail-503128.html
到了这里,关于【论文笔记】BEIT:BERT PRE-TRAINING OF IMAGE TRANSFORMERS的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!